

Formation of the Arabidopsis pentatricopeptide repeat family
- PMID: 16825340
- PMCID: PMC1489915
- DOI: 10.1104/pp.106.077826
Formation of the Arabidopsis pentatricopeptide repeat family
Abstract
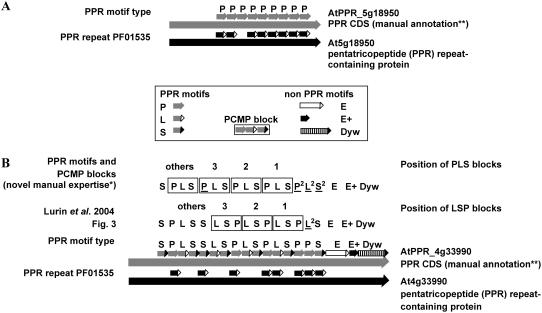
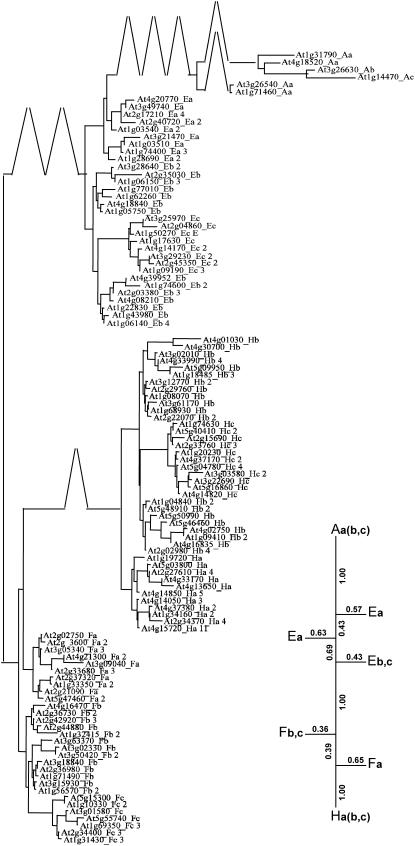
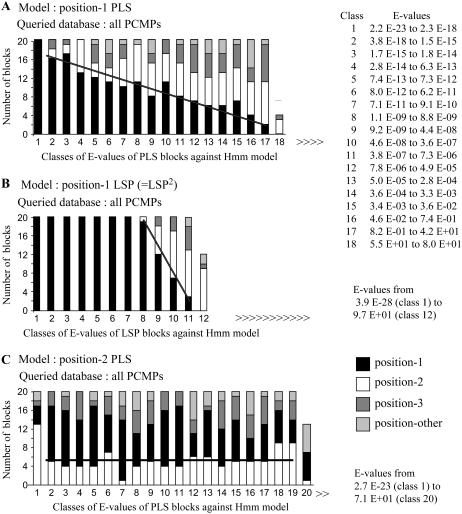
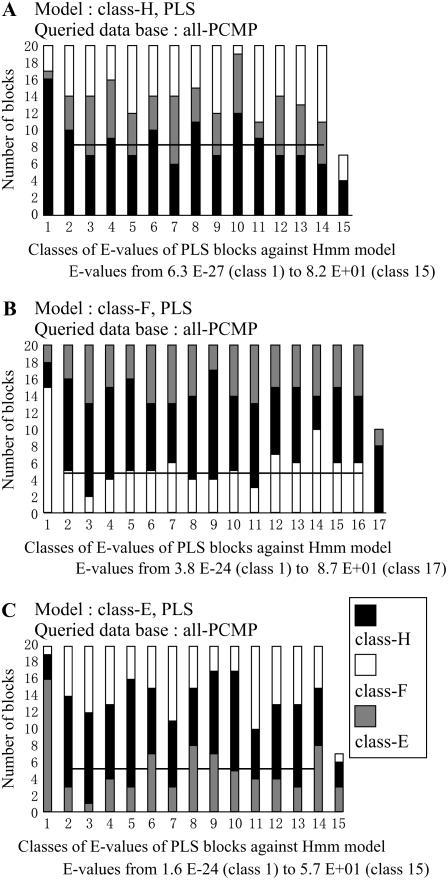
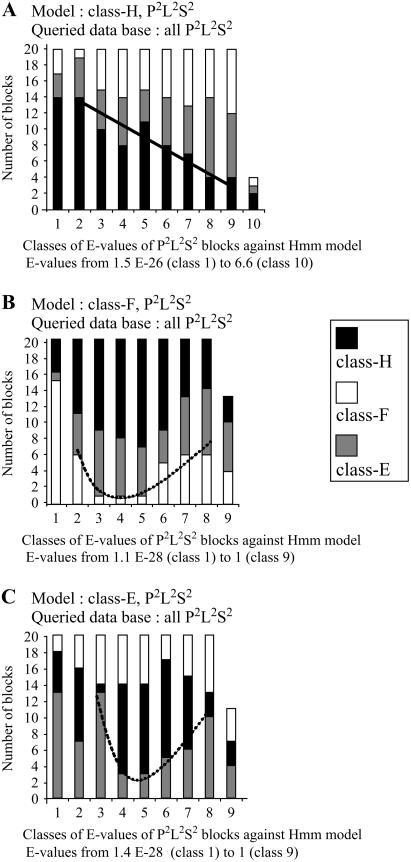
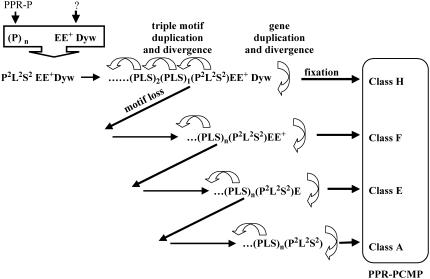
In Arabidopsis (Arabidopsis thaliana) the 466 pentatricopeptide repeat (PPR) proteins are putative RNA-binding proteins with essential roles in organelles. Roughly half of the PPR proteins form the plant combinatorial and modular protein (PCMP) subfamily, which is land-plant specific. PCMPs exhibit a large and variable tandem repeat of a standard pattern of three PPR variant motifs. The association or not of this repeat with three non-PPR motifs at their C terminus defines four distinct classes of PCMPs. The highly structured arrangement of these motifs and the similar repartition of these arrangements in the four classes suggest precise relationships between motif organization and substrate specificity. This study is an attempt to reconstruct an evolutionary scenario of the PCMP family. We developed an innovative approach based on comparisons of the proteins at two levels: namely the succession of motifs along the protein and the amino acid sequence of the motifs. It enabled us to infer evolutionary relationships between proteins as well as between the inter- and intraprotein repeats. First, we observed a polarized elongation of the repeat from the C terminus toward the N-terminal region, suggesting local recombinations of motifs. Second, the most N-terminal PPR triple motif proved to evolve under different constraints than the remaining repeat. Altogether, the evidence indicates different evolution for the PPR region and the C-terminal one in PCMPs, which points to distinct functions for these regions. Moreover, local sequence homogeneity observed across PCMP classes may be due to interclass shuffling of motifs, or to deletions/insertions of non-PPR motifs at the C terminus.
Figures
Similar articles
-
On the expansion of the pentatricopeptide repeat gene family in plants.Mol Biol Evol. 2008 Jun;25(6):1120-8. doi: 10.1093/molbev/msn057. Epub 2008 Mar 14. Mol Biol Evol. 2008. PMID: 18343892
-
PIRLs: a novel class of plant intracellular leucine-rich repeat proteins.Plant Cell Physiol. 2005 Jun;46(6):913-22. doi: 10.1093/pcp/pci097. Epub 2005 Apr 4. Plant Cell Physiol. 2005. PMID: 15809230
-
Identification and characterization of cDNAs encoding pentatricopeptide repeat proteins in the basal land plant, the moss Physcomitrella patens.Gene. 2004 Dec 22;343(2):305-11. doi: 10.1016/j.gene.2004.09.015. Gene. 2004. PMID: 15588585
-
[Family of pentatricopeptide repeat proteins].Postepy Biochem. 2005;51(4):440-6. Postepy Biochem. 2005. PMID: 16676579 Review. Polish.
-
Mechanistic insight into pentatricopeptide repeat proteins as sequence-specific RNA-binding proteins for organellar RNAs in plants.Plant Cell Physiol. 2012 Jul;53(7):1171-9. doi: 10.1093/pcp/pcs069. Epub 2012 May 9. Plant Cell Physiol. 2012. PMID: 22576772 Review.
Cited by
-
GhYGL1d, a pentatricopeptide repeat protein, is required for chloroplast development in cotton.BMC Plant Biol. 2019 Aug 13;19(1):350. doi: 10.1186/s12870-019-1945-1. BMC Plant Biol. 2019. PMID: 31409298 Free PMC article.
-
Seedling Lethal1, a pentatricopeptide repeat protein lacking an E/E+ or DYW domain in Arabidopsis, is involved in plastid gene expression and early chloroplast development.Plant Physiol. 2013 Dec;163(4):1844-58. doi: 10.1104/pp.113.227199. Epub 2013 Oct 21. Plant Physiol. 2013. PMID: 24144791 Free PMC article.
-
Chloroplastic pentatricopeptide repeat proteins (PPR) in albino plantlets of Agave angustifolia Haw. reveal unexpected behavior.BMC Plant Biol. 2022 Jul 19;22(1):352. doi: 10.1186/s12870-022-03742-2. BMC Plant Biol. 2022. PMID: 35850575 Free PMC article.
-
Sequence-specific binding of a chloroplast pentatricopeptide repeat protein to its native group II intron ligand.RNA. 2008 Sep;14(9):1930-41. doi: 10.1261/rna.1077708. Epub 2008 Jul 30. RNA. 2008. PMID: 18669444 Free PMC article.
-
LPA66 is required for editing psbF chloroplast transcripts in Arabidopsis.Plant Physiol. 2009 Jul;150(3):1260-71. doi: 10.1104/pp.109.136812. Epub 2009 May 15. Plant Physiol. 2009. PMID: 19448041 Free PMC article.
References
-
- Akagi H, Nakamura A, Yokozeki-Misono Y, Inagaki A, Takahashi H, Mori K, Fujimura T (2004) Positional cloning of the rice Rf-1 gene, a restorer of BT-type cytoplasmic male sterility that encodes a mitochondria-targeting PPR protein. Theor Appl Genet 108: 1449–1457 - PubMed
-
- Aubourg S, Boudet N, Kreis M, Lecharny A (2000) In Arabidopsis thaliana, 1% of the genome codes for a novel protein family unique to plants. Plant Mol Biol 42: 603–613 - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
