

. 2006 Jul 1;34(Web Server issue):W600-3.
doi: 10.1093/nar/gkl170.
PROTOGENE: turning amino acid alignments into bona fide CDS nucleotide alignments
Affiliations
- PMID: 16845080
- PMCID: PMC1538918
- DOI: 10.1093/nar/gkl170
Item in Clipboard
PROTOGENE: turning amino acid alignments into bona fide CDS nucleotide alignments
Nucleic Acids Res.
.
Abstract
We describe Protogene, a server that can turn a protein multiple sequence alignment into the equivalent alignment of the original gene coding DNA. Protogene relies on a pipeline where every initial protein sequence is BLASTed against RefSeq or NR. The annotation associated with potential matches is used to identify the gene sequence. This gene sequence is then aligned with the query protein using Exonerate in order to extract a coding nucleotide sequence matching the original protein. Protogene can handle protein fragments and will return every CDS coding for a given protein, even if they occur in different genomes. Protogene is available from http://www.tcoffee.org/.
Figures
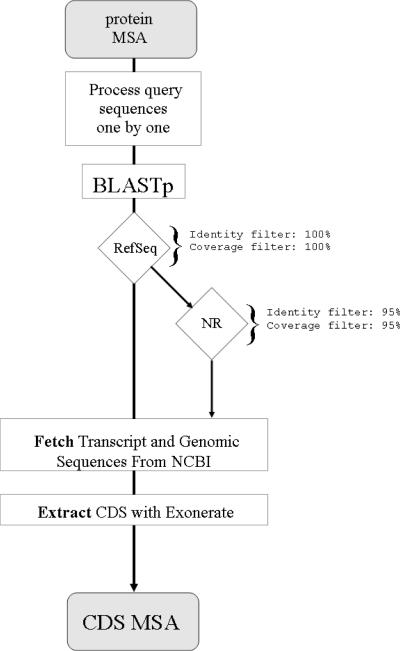
Protogene flow chart sequences are first BLASTed against RefSeq. If no match is found, they are then BLASTed against NR. Nucleotide sequences are fetched from NCBI and processed with Exonerate to yield CDSs that perfectly match the original protein.
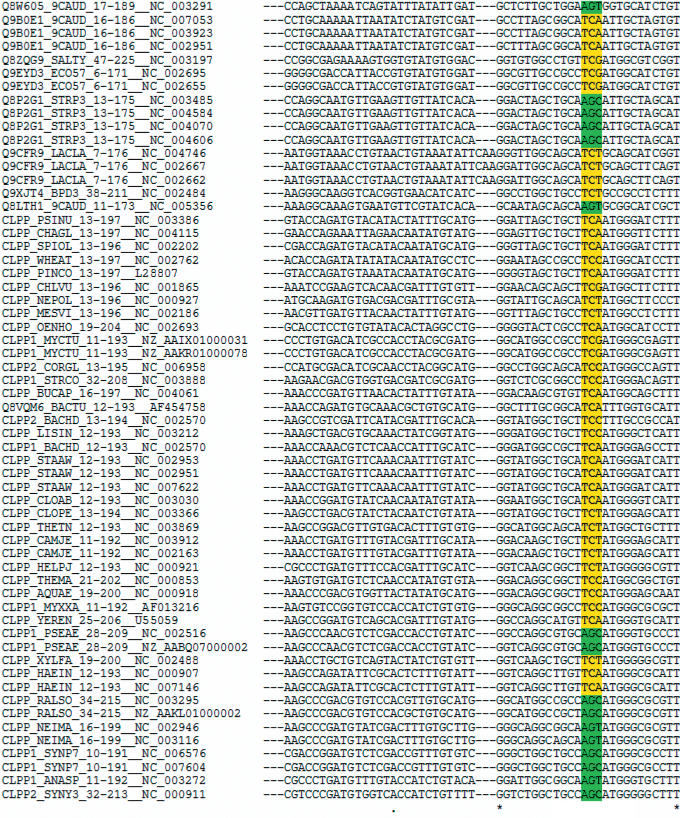
Protogene output on the CLP Serine Protease family. The Seed MSA of the PFAM profile entry (PFAM PF00574) was processed by Protogene. The portion of the alignment containing the Serine active site classes are indicated in yellow (UCN) and green (AGY).
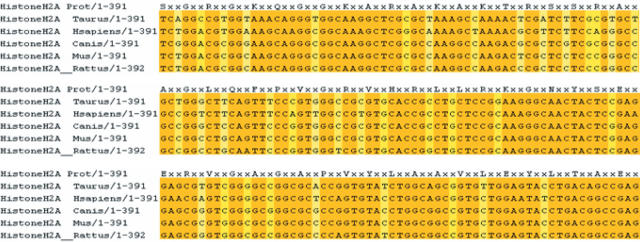
Protogene output on the Human H2A Histone protein. The original protein sequence is indicated on the top. Light coloured columns are those not entirely conserved.
References
-
- Altschul S.F., Gish W., Miller W., Myers E.W., Lipman D.J. Basic local alignment search tool. J. Mol. Biol. 1990;215:403–410. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
