

Automatic document classification of biological literature
- PMID: 16893465
- PMCID: PMC1559726
- DOI: 10.1186/1471-2105-7-370
Automatic document classification of biological literature
Abstract
Background: Document classification is a wide-spread problem with many applications, from organizing search engine snippets to spam filtering. We previously described Textpresso, a text-mining system for biological literature, which marks up full text according to a shallow ontology that includes terms of biological interest. This project investigates document classification in the context of biological literature, making use of the Textpresso markup of a corpus of Caenorhabditis elegans literature.
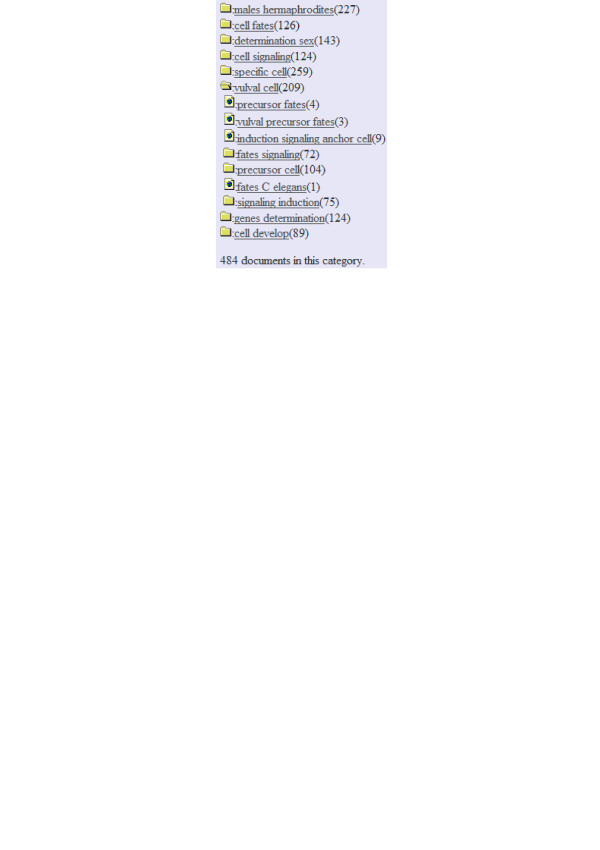
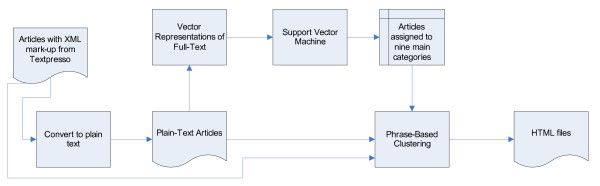
Results: We present a two-step text categorization algorithm to classify a corpus of C. elegans papers. Our classification method first uses a support vector machine-trained classifier, followed by a novel, phrase-based clustering algorithm. This clustering step autonomously creates cluster labels that are descriptive and understandable by humans. This clustering engine performed better on a standard test-set (Reuters 21578) compared to previously published results (F-value of 0.55 vs. 0.49), while producing cluster descriptions that appear more useful. A web interface allows researchers to quickly navigate through the hierarchy and look for documents that belong to a specific concept.
Conclusion: We have demonstrated a simple method to classify biological documents that embodies an improvement over current methods. While the classification results are currently optimized for Caenorhabditis elegans papers by human-created rules, the classification engine can be adapted to different types of documents. We have demonstrated this by presenting a web interface that allows researchers to quickly navigate through the hierarchy and look for documents that belong to a specific concept.
Figures
References
-
- Andrade MA, Bork P. Automated extraction or information in molecular biology. FEBS Lett. 2000;476:12–17. - PubMed
-
- De Bruijn B, Martin J. Getting to the (c)ore of knowledge: Mining biomedical literature. Int J Med Inf. 2002;67:7–18. - PubMed
-
- Staab S, (editor) Mining information for function genomics. IEEE Intell Syst. 2002;17:66.
-
- Jensen LJ, Saric J, Bork P. Literature mining for the biologist: from information retrieval to biological discovery. Nature Reviews Genetics. 2006;7:119–129. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
