

Expansion of protein domain repeats
- PMID: 16933986
- PMCID: PMC1553488
- DOI: 10.1371/journal.pcbi.0020114
Expansion of protein domain repeats
Abstract
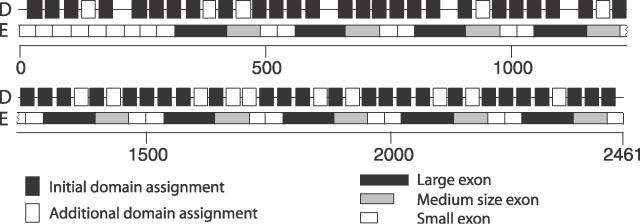
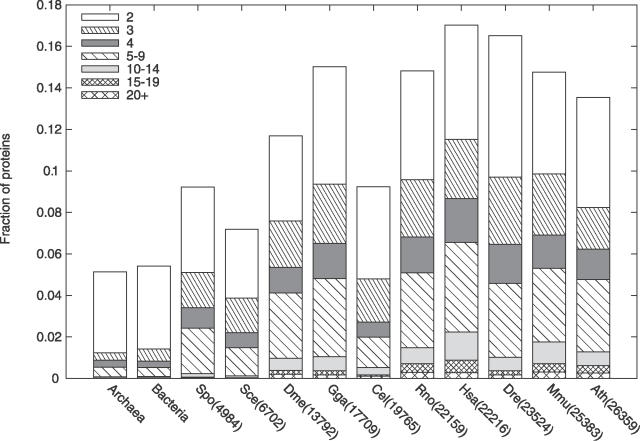
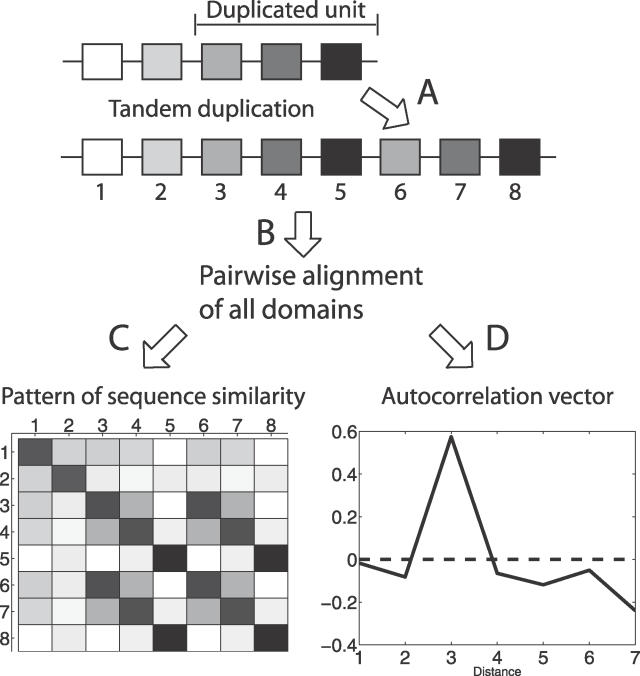
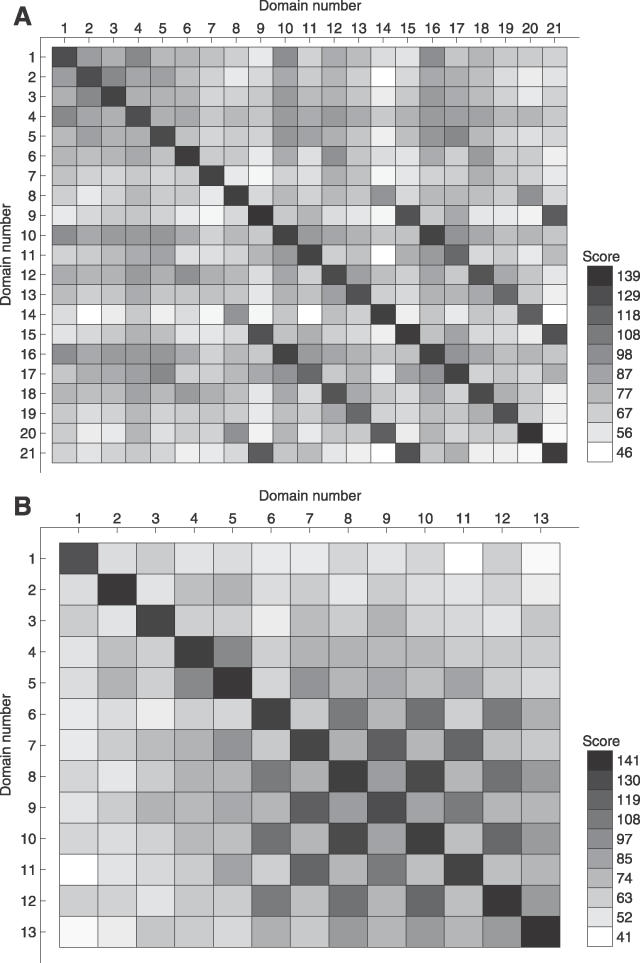
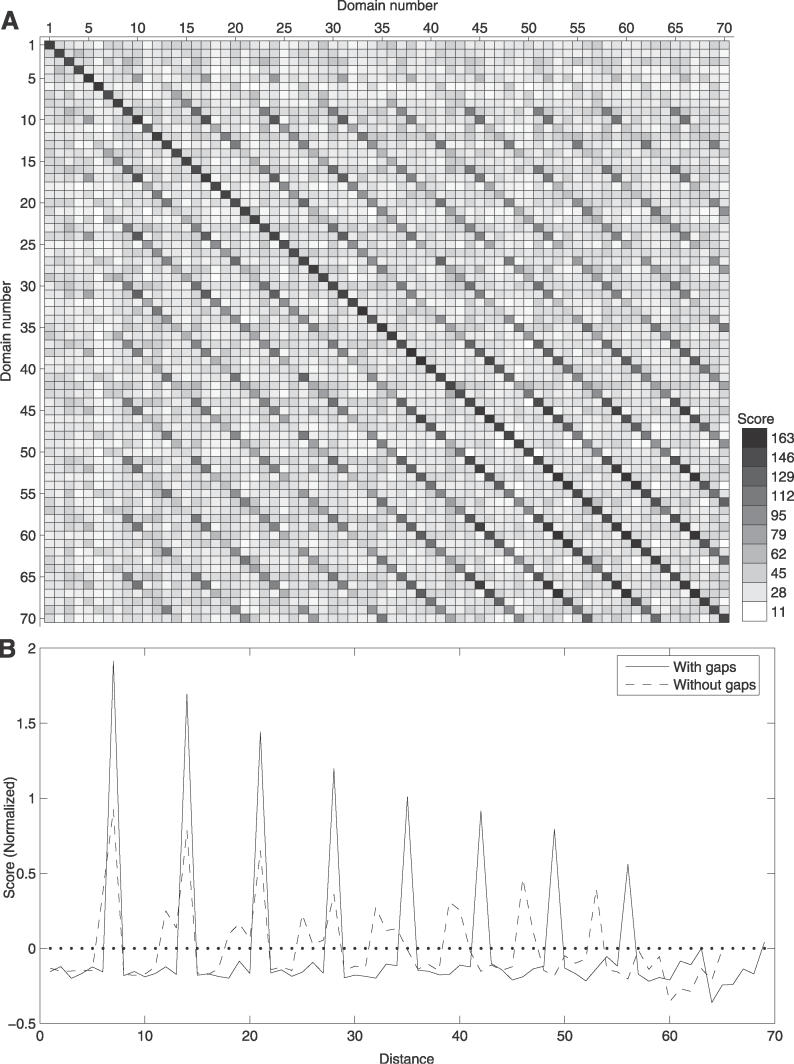
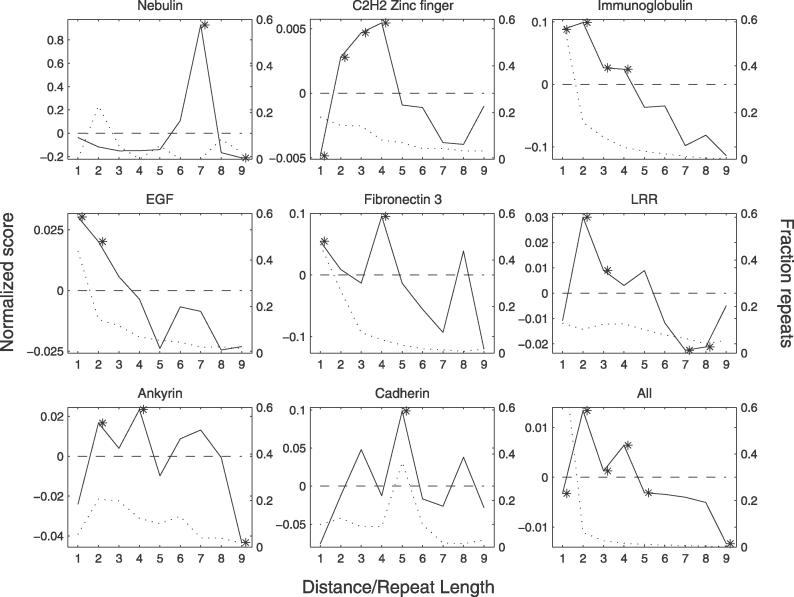
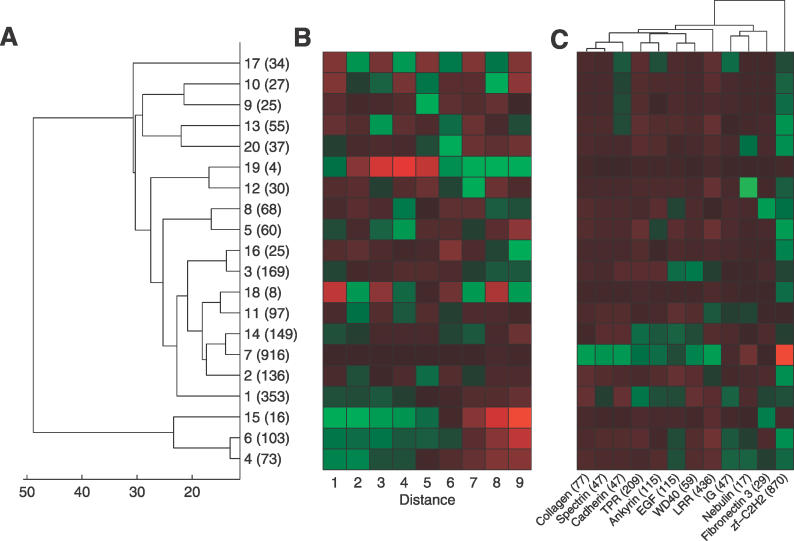
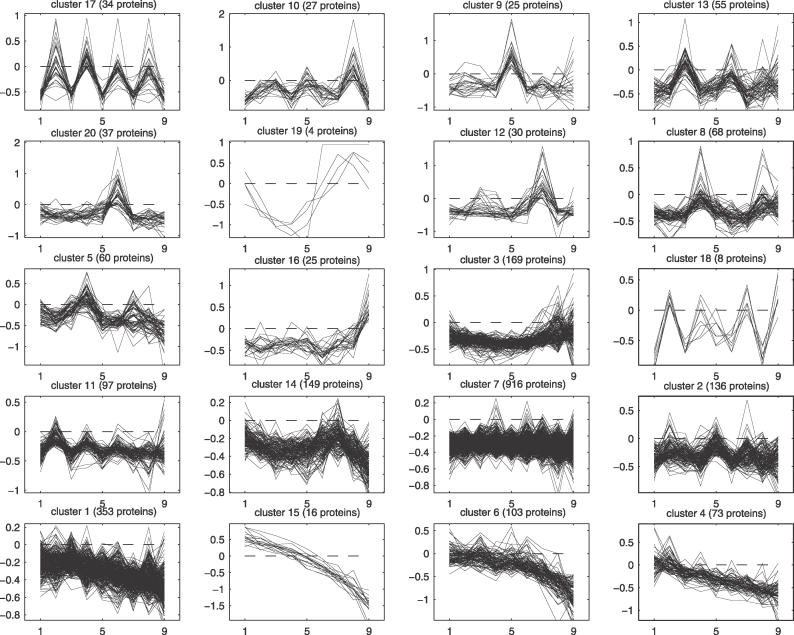
Many proteins, especially in eukaryotes, contain tandem repeats of several domains from the same family. These repeats have a variety of binding properties and are involved in protein-protein interactions as well as binding to other ligands such as DNA and RNA. The rapid expansion of protein domain repeats is assumed to have evolved through internal tandem duplications. However, the exact mechanisms behind these tandem duplications are not well-understood. Here, we have studied the evolution, function, protein structure, gene structure, and phylogenetic distribution of domain repeats. For this purpose we have assigned Pfam-A domain families to 24 proteomes with more sensitive domain assignments in the repeat regions. These assignments confirmed previous findings that eukaryotes, and in particular vertebrates, contain a much higher fraction of proteins with repeats compared with prokaryotes. The internal sequence similarity in each protein revealed that the domain repeats are often expanded through duplications of several domains at a time, while the duplication of one domain is less common. Many of the repeats appear to have been duplicated in the middle of the repeat region. This is in strong contrast to the evolution of other proteins that mainly works through additions of single domains at either terminus. Further, we found that some domain families show distinct duplication patterns, e.g., nebulin domains have mainly been expanded with a unit of seven domains at a time, while duplications of other domain families involve varying numbers of domains. Finally, no common mechanism for the expansion of all repeats could be detected. We found that the duplication patterns show no dependence on the size of the domains. Further, repeat expansion in some families can possibly be explained by shuffling of exons. However, exon shuffling could not have created all repeats.
Conflict of interest statement
Figures
Similar articles
-
Nebulin: a study of protein repeat evolution.J Mol Biol. 2010 Sep 10;402(1):38-51. doi: 10.1016/j.jmb.2010.07.011. Epub 2010 Jul 17. J Mol Biol. 2010. PMID: 20643138
-
The evolution of filamin-a protein domain repeat perspective.J Struct Biol. 2012 Sep;179(3):289-98. doi: 10.1016/j.jsb.2012.02.010. Epub 2012 Mar 10. J Struct Biol. 2012. PMID: 22414427 Free PMC article.
-
A census of protein repeats.J Mol Biol. 1999 Oct 15;293(1):151-60. doi: 10.1006/jmbi.1999.3136. J Mol Biol. 1999. PMID: 10512723
-
Evolution of the spectrin repeat.Bioessays. 1997 Sep;19(9):811-7. doi: 10.1002/bies.950190911. Bioessays. 1997. PMID: 9297972 Review.
-
Molecular characteristics of insect vitellogenins and vitellogenin receptors.Insect Biochem Mol Biol. 1998 May-Jun;28(5-6):277-300. doi: 10.1016/s0965-1748(97)00110-0. Insect Biochem Mol Biol. 1998. PMID: 9692232 Review.
Cited by
-
Two immunoglobulin tandem proteins with a linking β-strand reveal unexpected differences in cooperativity and folding pathways.J Mol Biol. 2012 Feb 10;416(1):137-47. doi: 10.1016/j.jmb.2011.12.012. Epub 2011 Dec 13. J Mol Biol. 2012. PMID: 22197372 Free PMC article.
-
Length constraints of multi-domain proteins in metazoans.Bioinformation. 2010 Apr 30;4(10):441-4. doi: 10.6026/97320630004441. Bioinformation. 2010. PMID: 20975906 Free PMC article.
-
A versatile palindromic amphipathic repeat coding sequence horizontally distributed among diverse bacterial and eucaryotic microbes.BMC Genomics. 2010 Jul 13;11:430. doi: 10.1186/1471-2164-11-430. BMC Genomics. 2010. PMID: 20626840 Free PMC article.
-
Deep conservation of human protein tandem repeats within the eukaryotes.Mol Biol Evol. 2014 May;31(5):1132-48. doi: 10.1093/molbev/msu062. Epub 2014 Feb 3. Mol Biol Evol. 2014. PMID: 24497029 Free PMC article.
-
Living Organisms Author Their Read-Write Genomes in Evolution.Biology (Basel). 2017 Dec 6;6(4):42. doi: 10.3390/biology6040042. Biology (Basel). 2017. PMID: 29211049 Free PMC article. Review.
References
-
- Apic G, Gough J, Teichmann SA. Domain combinations in archaeal, eubacterial, and eukaryotic proteomes. J Mol Biol. 2001;310:311–325. - PubMed
-
- Vogel C, Teichmann SA, Pereira-Leal J. The relationship between domain duplication and recombination. J Mol Biol. 2005;346:355–365. - PubMed
-
- Björklund ÅK, Ekman D, Light S, Frey-Skött J, Elofsson A. Domain rearrangements in protein evolution. J Mol Biol. 2005;353:911–923. - PubMed
-
- Weiner J, III, Beaussart F, Bornberg-Bauer E. Domain deletions and substitutions in the modular protein evolution. FEBS J. 2006;273:2037–2047. - PubMed
-
- Andrade M, Perez-Iratxeta C, Ponting C. Protein repeats: Structures, functions, and evolution. J Struct Biol. 2001;134:117–131. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
