

Compact, universal DNA microarrays to comprehensively determine transcription-factor binding site specificities
- PMID: 16998473
- PMCID: PMC4419707
- DOI: 10.1038/nbt1246
Compact, universal DNA microarrays to comprehensively determine transcription-factor binding site specificities
Abstract
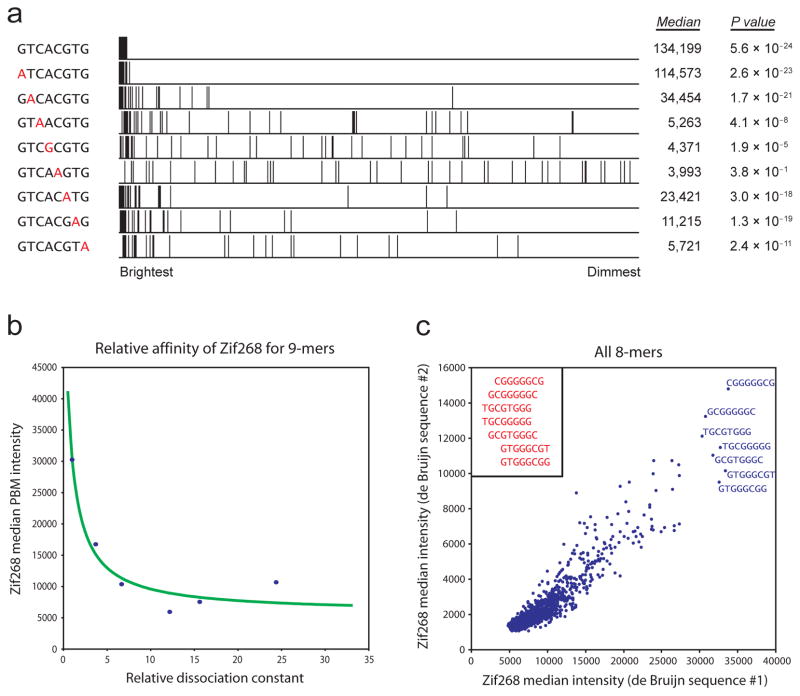
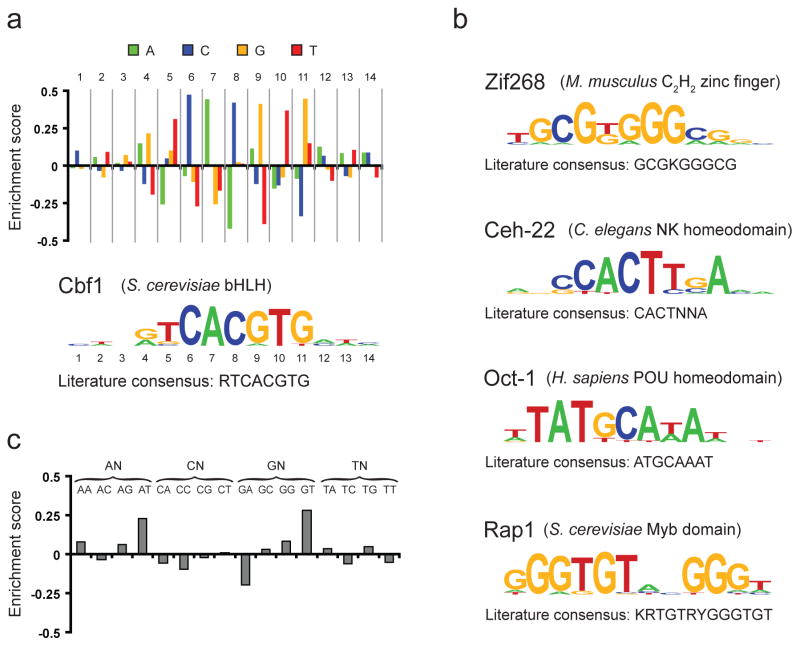
Transcription factors (TFs) interact with specific DNA regulatory sequences to control gene expression throughout myriad cellular processes. However, the DNA binding specificities of only a small fraction of TFs are sufficiently characterized to predict the sequences that they can and cannot bind. We present a maximally compact, synthetic DNA sequence design for protein binding microarray (PBM) experiments that represents all possible DNA sequence variants of a given length k (that is, all 'k-mers') on a single, universal microarray. We constructed such all k-mer microarrays covering all 10-base pair (bp) binding sites by converting high-density single-stranded oligonucleotide arrays to double-stranded (ds) DNA arrays. Using these microarrays we comprehensively determined the binding specificities over a full range of affinities for five TFs of different structural classes from yeast, worm, mouse and human. The unbiased coverage of all k-mers permits high-throughput interrogation of binding site preferences, including nucleotide interdependencies, at unprecedented resolution.
Figures

References
-
- Golomb S. Shift Register Sequences. Aegean Park Press; Laguna Hills, CA: 1967.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
