

CDD: a conserved domain database for interactive domain family analysis
- PMID: 17135202
- PMCID: PMC1751546
- DOI: 10.1093/nar/gkl951
CDD: a conserved domain database for interactive domain family analysis
Abstract
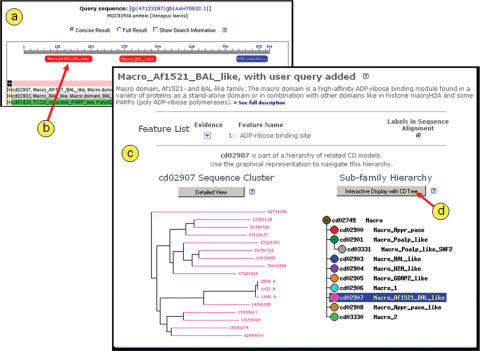
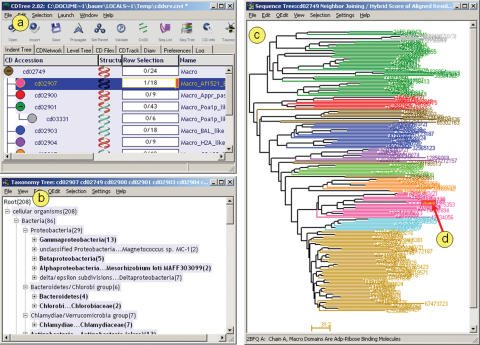
The conserved domain database (CDD) is part of NCBI's Entrez database system and serves as a primary resource for the annotation of conserved domain footprints on protein sequences in Entrez. Entrez's global query interface can be accessed at http://www.ncbi.nlm.nih.gov/Entrez and will search CDD and many other databases. Domain annotation for proteins in Entrez has been pre-computed and is readily available in the form of 'Conserved Domain' links. Novel protein sequences can be scanned against CDD using the CD-Search service; this service searches databases of CDD-derived profile models with protein sequence queries using BLAST heuristics, at http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi. Protein query sequences submitted to NCBI's protein BLAST search service are scanned for conserved domain signatures by default. The CDD collection contains models imported from Pfam, SMART and COG, as well as domain models curated at NCBI. NCBI curated models are organized into hierarchies of domains related by common descent. Here we report on the status of the curation effort and present a novel helper application, CDTree, which enables users of the CDD resource to examine curated hierarchies. More importantly, CDD and CDTree used in concert, serve as a powerful tool in protein classification, as they allow users to analyze protein sequences in the context of domain family hierarchies.
Figures
References
-
- Wang Y., Geer L.Y., Chappey C., Kans J.A., Bryant S.H. Cn3D: sequence and structure views for Entrez. Trends Biochem. Sci. 2000;25:300–302. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
