

Functional analysis of gene duplications in Saccharomyces cerevisiae
- PMID: 17151249
- PMCID: PMC1800624
- DOI: 10.1534/genetics.106.064329
Functional analysis of gene duplications in Saccharomyces cerevisiae
Abstract
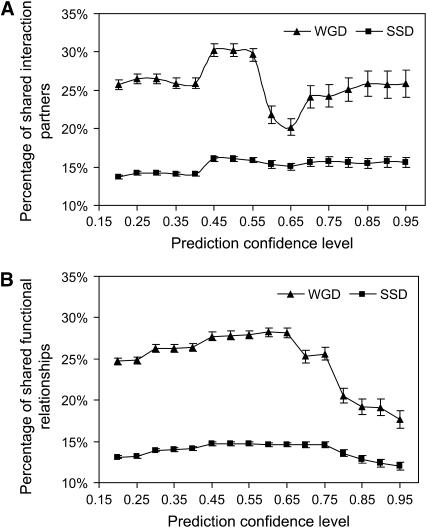
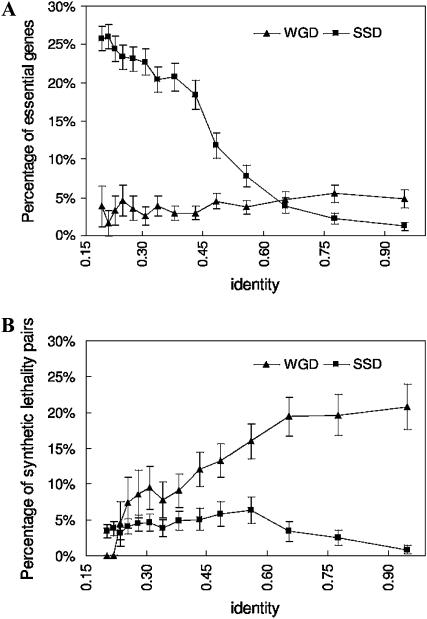
Gene duplication can occur on two scales: whole-genome duplications (WGD) and smaller-scale duplications (SSD) involving individual genes or genomic segments. Duplication may result in functionally redundant genes or diverge in function through neofunctionalization or subfunctionalization. The effect of duplication scale on functional evolution has not yet been explored, probably due to the lack of global knowledge of protein function and different times of duplication events. To address this question, we used integrated Bayesian analysis of diverse functional genomic data to accurately evaluate the extent of functional similarity and divergence between paralogs on a global scale. We found that paralogs resulting from the whole-genome duplication are more likely to share interaction partners and biological functions than smaller-scale duplicates, independent of sequence similarity. In addition, WGD paralogs show lower frequency of essential genes and higher synthetic lethality rate, but instead diverge more in expression pattern and upstream regulatory region. Thus, our analysis demonstrates that WGD paralogs generally have similar compensatory functions but diverging expression patterns, suggesting a potential of distinct evolutionary scenarios for paralogs that arose through different duplication mechanisms. Furthermore, by identifying these functional disparities between the two types of duplicates, we reconcile previous disputes on the relationship between sequence divergence and expression divergence or essentiality.
Figures





References
-
- Altschul, S. F., W. Gish, W. Miller, E. W. Myers and D. J. Lipman, 1990. Basic local alignment search tool. J. Mol. Biol. 215: 403–410. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
