

Visual cortex allows prediction of perceptual states during ambiguous structure-from-motion
- PMID: 17267555
- PMCID: PMC6673188
- DOI: 10.1523/JNEUROSCI.4593-06.2007
Visual cortex allows prediction of perceptual states during ambiguous structure-from-motion
Abstract
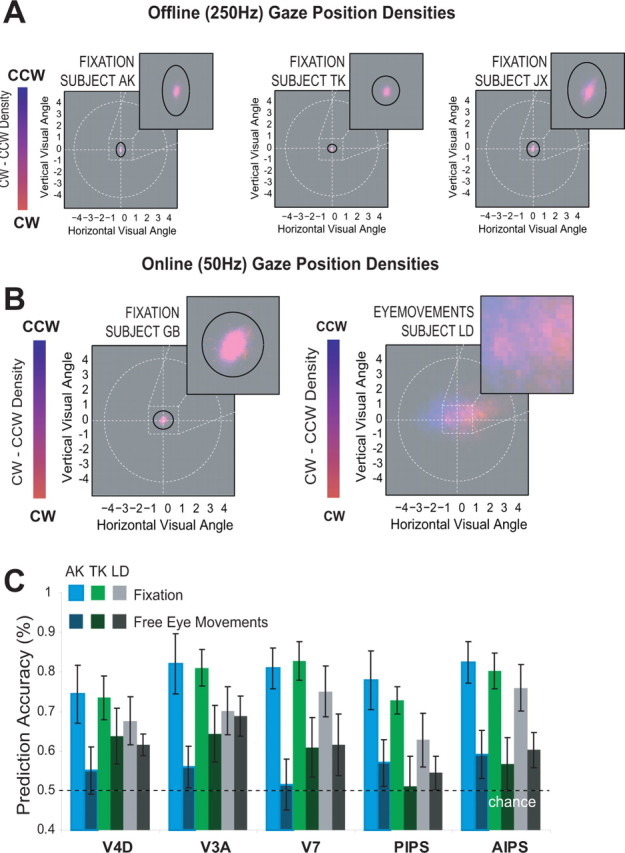
We investigated the role of retinotopic visual cortex and motion-sensitive areas in representing the content of visual awareness during ambiguous structure-from-motion (SFM), using functional magnetic resonance imaging (fMRI) and multivariate statistics (support vector machines). Our results indicate that prediction of perceptual states can be very accurate for data taken from dorsal visual areas V3A, V4D, V7, and MT+ and for parietal areas responsive to SFM, but to a lesser extent for other visual areas. Generalization of prediction was possible, because prediction accuracy was significantly better than chance for both an unambiguous stimulus and a different experimental design. Detailed analysis of eye movements revealed that strategic and even encouraged beneficial eye movements were not the cause of the prediction accuracy based on cortical activation. We conclude that during perceptual rivalry, neural correlates of visual awareness can be found in retinotopic visual cortex, MT+, and parietal cortex. We argue that the organization of specific motion-sensitive neurons creates detectable biases in the preferred direction selectivity of voxels, allowing prediction of perceptual states. During perceptual rivalry, retinotopic visual cortex, in particular higher-tier dorsal areas like V3A and V7, actively represents the content the visual awareness.
Figures





References
-
- Andersen RA, Bradley DC. Perception of three-dimensional structure from motion. Trends Cogn Neurosci. 1998;2:222–228. - PubMed
-
- Blake R, Logothetis NK. Visual competition. Nat Rev Neurosci. 2002;3:13–21. - PubMed
-
- Bradley DC, Qian N, Andersen RA. Encoding of three-dimensional structure-from-motion by primate area MT neurons. Nature. 1998;392:609–611. - PubMed
-
- Brascamp JW, van Ee R, Pestman WR, van den Berg AV. Distributions of alternation rates in various forms of bistable perception. J Vision. 2005;5:287–298. - PubMed
-
- Brouwer GJ, van Ee R. Endogenous influences on perceptual bistability depend on exogenous stimulus characteristics. Vis Res. 2006;46:3393–3402. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources