

Evidence of positive selection on a class I ADH locus
- PMID: 17273965
- PMCID: PMC1821113
- DOI: 10.1086/512485
Evidence of positive selection on a class I ADH locus
Abstract
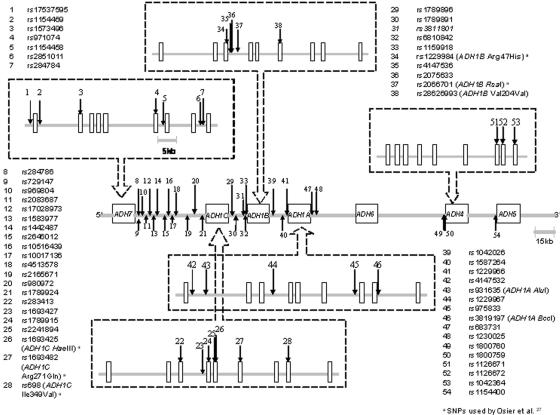
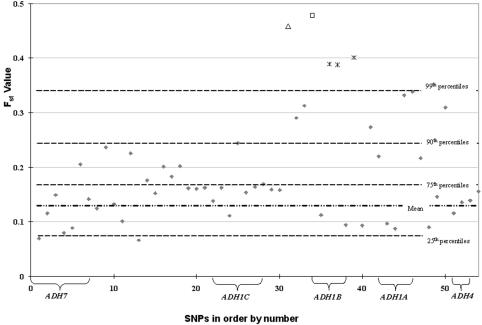
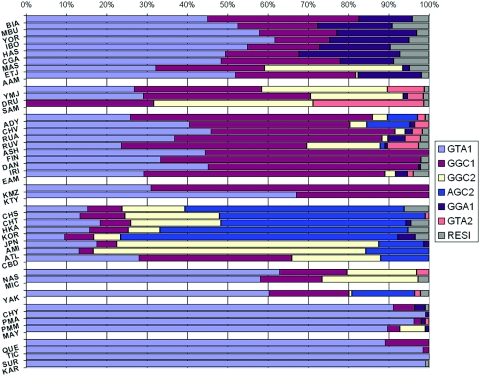
The alcohol dehydrogenase (ADH) family of enzymes catalyzes the reversible oxidation of alcohol to acetaldehyde. Seven ADH genes exist in a segment of ~370 kb on 4q21. Products of the three class I ADH genes that share 95% sequence identity are believed to play the major role in the first step of ethanol metabolism. Because the common belief that selection has operated at the ADH1B*47His allele in East Asian populations lacks direct biological or statistical evidence, we used genomic data to test the hypothesis. Data consisted of 54 single-nucleotide polymorphisms (SNPs) across the ADH clusters in a global sampling of 42 populations. Both the F(st) statistic and the long-range haplotype (LRH) test provided positive evidence of selection in several East Asian populations. The ADH1B Arg47His functional polymorphism has the highest F(st) of the 54 SNPs in the ADH cluster, and it is significantly above the mean F(st) of 382 presumably neutral sites tested on the same 42 population samples. The LRH test that uses cores including that site and extending on both sides also gives significant evidence of positive selection in some East Asian populations for a specific haplotype carrying the ADH1B*47His allele. Interestingly, this haplotype is present at a high frequency in only some East Asian populations, whereas the specific allele also exists in other East Asian populations and in the Near East and Europe but does not show evidence of selection with use of the LRH test. Although the ADH1B*47His allele conveys a well-confirmed protection against alcoholism, that modern phenotypic manifestation does not easily translate into a positive selective force, and the nature of that selective force, in the past and/or currently, remains speculative.
Figures








References
Web Resources
-
- ALFRED, http://alfred.med.yale.edu/
-
- Online Mendelian Inheritance in Man (OMIM), http://www.ncbi.nlm.nih.gov/Omim/ (for alcohol dependence, ADH1B, ADH1C, ALDH2, ADH1A, ADH4, ADH5, ADH7, and ADH6)
-
- UCSC Genome Browser, http://genome.ucsc.edu/cgi-bin/hgGateway
References
-
- Ramchandani VA, Bosron WF, Li TK (2001) Research advances in ethanol metabolism. Pathol Biol (Paris) 49:676–682 - PubMed
-
- Yoshida A, Hsu LC, Yasunami M (1991) Genetics of human alcohol-metabolizing enzymes. Prog Nucleic Acid Res Mol Biol 40:255–287 - PubMed
-
- Osier MV, Pakstis AJ, Goldman D, Edenberg HJ, Kidd JR, Kidd KK (2002) A proline-threonine substitution in codon 351 of ADH1C is common in Native Americans. Alcohol Clin Exp Res 26:1759–1763 - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
