

doi: 10.1186/gb-2007-8-2-r23.
Clustering of phosphorylation site recognition motifs can be exploited to predict the targets of cyclin-dependent kinase
Affiliations
- PMID: 17316440
- PMCID: PMC1852407
- DOI: 10.1186/gb-2007-8-2-r23
Item in Clipboard
Clustering of phosphorylation site recognition motifs can be exploited to predict the targets of cyclin-dependent kinase
Genome Biol.
2007.
Abstract
Protein kinases are critical to cellular signalling and post-translational gene regulation, but their biological substrates are difficult to identify. We show that cyclin-dependent kinase (CDK) consensus motifs are frequently clustered in CDK substrate proteins. Based on this, we introduce a new computational strategy to predict the targets of CDKs and use it to identify new biologically interesting candidates. Our data suggest that regulatory modules may exist in protein sequence as clusters of short sequence motifs.
Figures
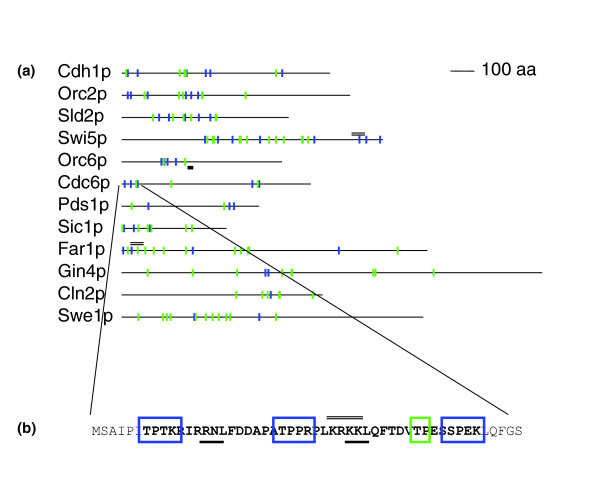
Clustering of consensus motifs in S. cerevisiae CDK targets. (a) Schematics of characterized S. cerevisiae CDK targets. Blue and green symbols indicate matches to the strong and weak CDK consensus, respectively. The thick black bar below indicates the characterized cy motif in Orc6. The double lines above indicate characterized nuclear localization signals. (b) Sequence of the amino-terminus of Cdc6. Blue and green boxes indicate matches to the strong and weak CDK consensus, respectively. Bold letters indicate the region with the maximal scoring cluster according to SBN. We suggest that this region may be regarded as a regulatory module (see text for details). Thick bars below the sequence indicate matches to the 'cy' motif and thin double lines above the sequence indicate characterized nuclear localization signals. aa, amino acid; CDK, cyclin-dependent kinase.
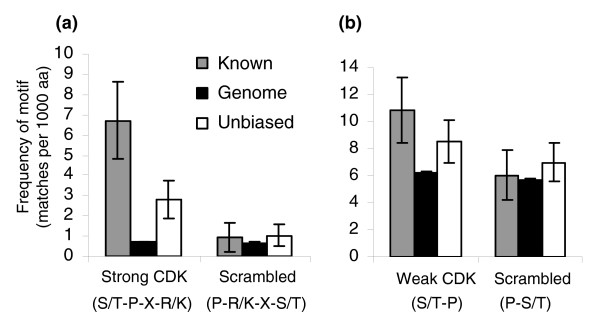
Enrichment of matches to the CDK consensus in CDK substrates. (a) The protein sequences of well characterized ('known') CDK targets (gray bars) are highly enriched for matches to the CDK strong consensus relative to the genome (black bars) but not for a scrambled version of the consensus. Similar results hold for the 'unbiased positives' from a high-throughput study (unfilled bars). (b) 'Known' and 'unbiased positives' are also somewhat enriched for the weak consensus but not for a scrambled version of it. See text for details. Frequencies are number of matches per 1000 amino acid (aa) residues. Error bars represent plus or minus two times the standard error. CDK, cyclin dependent kinase.
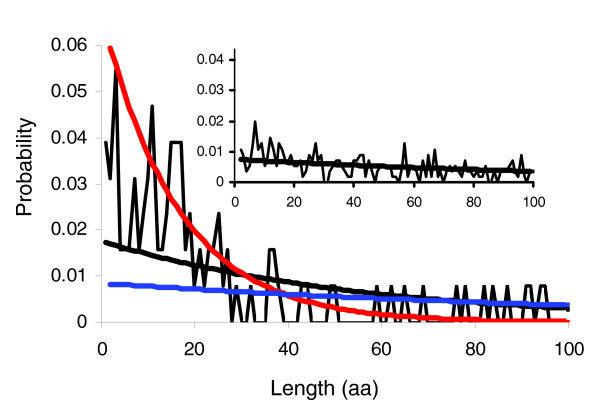
Modeling the distribution of spacing distances between matches to the CDK consensus. Fit of one (black trace) or two multivariate geometric components (blue and red traces) to the observed spacings (thin black trace) in the 'known' targets. The 'known' targets exhibit an excess of short spacings over what would be expected under the single geometric. The inset shows the geometric fit (black trace) to the spacings observed (thin black trace) in the 'unbiased negatives' and shows much better agreement. See text for details. CDK, cyclin-dependent kinase.
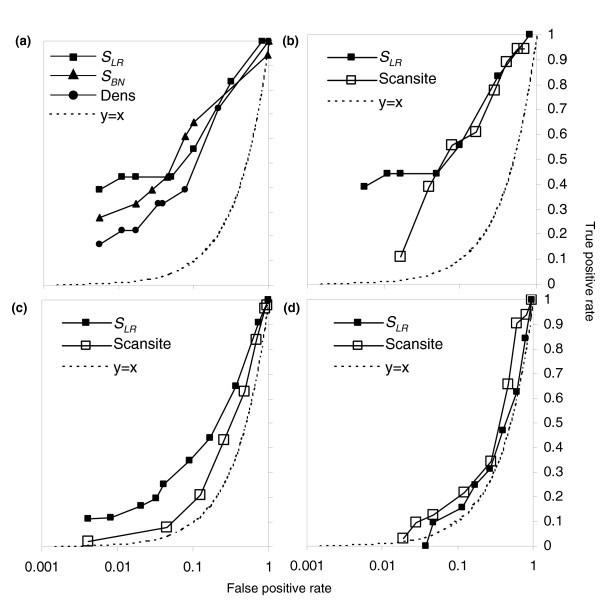
ROC curves for prediction of CDK substrate proteins. (a) Comparison of classifiers suggests that cluster based methods SLR and SBN (filled squares and triangles, respectively) perform better than the density of strong matches (filled circles). (b-d) comparison of cluster-based method SLR (filled squares) with Scansite, a matrix-based method (unfilled squares). See text for details. Plotted is the fraction of positives versus the fraction of negatives passing as the threshold is varied in the three datasets a, b ('unbiased' proteins, which were randomly chosen), c ('2+' proteins, which contain two or more matches to the strong CDK consensus), and d ('1cc' proteins containing one match to the strong CDK consensus and whose transcripts exhibit cell-cycle regulation). Note that the unlike conventional ROC curves, we plot the false-positive rate on a log scale, such that the expectation for a random predictor no longer falls on the diagonal. The expectation for a random predictor is indicated in each panel by the dotted trace. CDK, cyclin-dependent kinase; ROC, receiver operating characteristic.
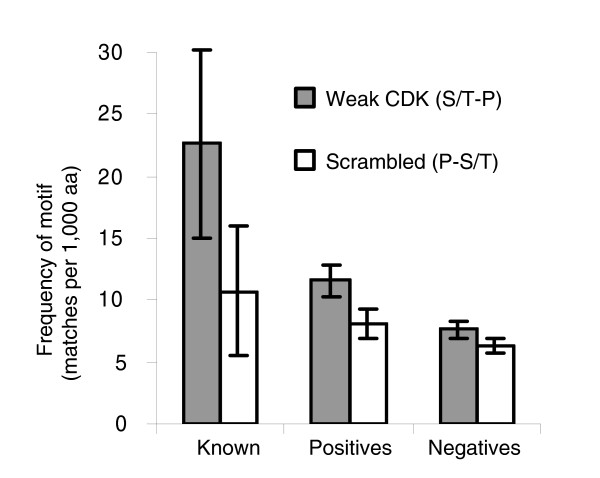
Weak CDK consensus matches co-cluster with strong matches. Gray and unfilled bars indicate frequencies of matches to the weak CDK consensus and to a scrambled version of it within regions identified as optimal clusters based on only strong matches. 'Known' are well characterized CDK substrates, and 'positives' and 'negatives' are proteins scoring greater than and less than 2 in a high-throughput kinase assay, respectively. See text for details. Frequencies are number of matches per 1,000 amino acid (aa) residues. Error bars represent plus or minus two times the standard error. CDK, cyclin-dependent kinase.
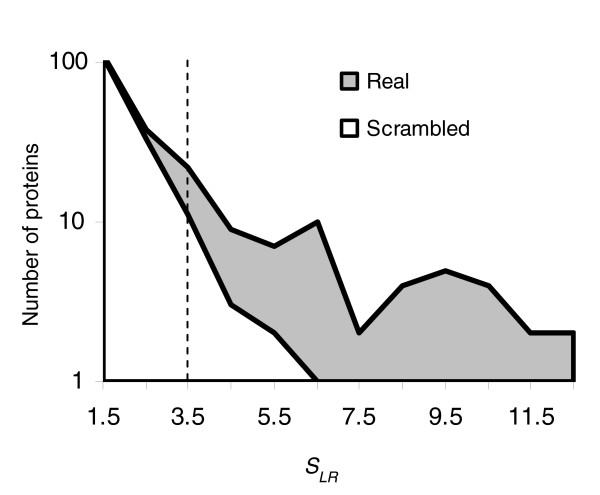
Defining a set of CDK consensus cluster containing proteins. Comparison of the distribution of scores from a search of the S. cerevisiae genome using either the real CDK consensus motifs (gray area) or scrambled versions (unfilled area) suggests a threshold of 3.5 (dotted line). CDK, cyclin-dependent kinase.
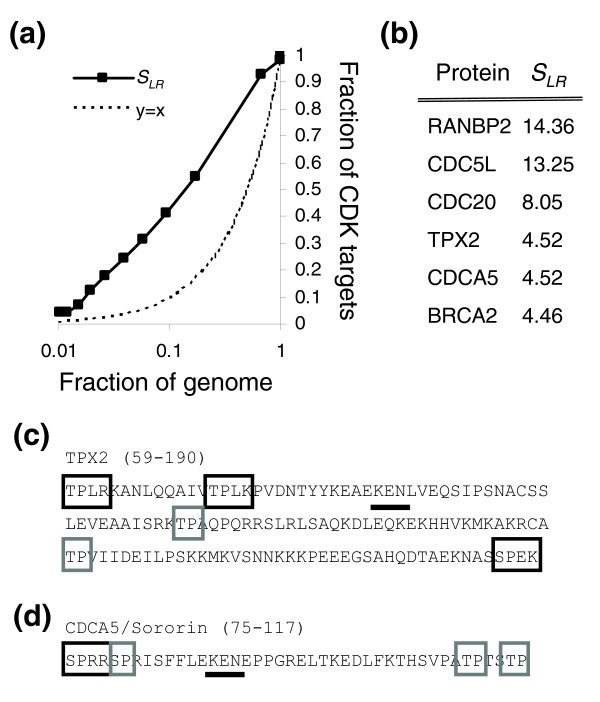
Predicting CDK targets in the human genome. (a) The fraction of proteins in known human CDK targets versus the fraction in the human genome (black bar) as the cutoff is varied. (b) Genes with clusters scoring more than 3.5 from a list of human cell-cycle genes. See text for details. (c,d) The K-E-N box (black underline) degradation signals in TPX2 (panel c) and Sororin (panel d) are found among clustered consensus matches. The entire optimal clusters are not shown. Strong and weak consensus matches are indicated by black and grey boxes, respectively. The regions of the protein shown are indicated in parentheses. CDK, cyclin-dependent kinase.
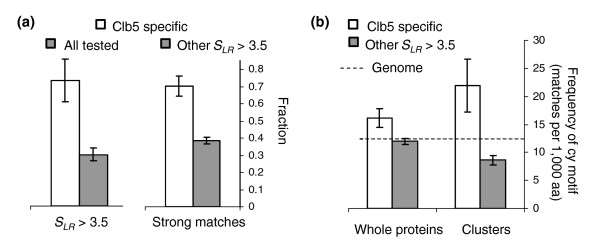
Clustering of CDK consensus matches and cyclin specificity. (a) The left side shows that clb5-specific CDK targets (unfilled bar) are more likely to score above the cutoff than other proteins assayed (gray bar), while the right side of panel a shows that clb5-specific CDK targets (unfilled bar) contain a higher proportion of strong matches than do other high-scoring proteins (gray bar). See text for details (b) CDK targets specific for clb5 (unfilled bars) contain an excess of matches to the cy motif relative to other high-scoring proteins (gray bars) in the entire protein sequence (left side), but this enrichment is more extreme if only regions containing clustered CDK consensus matches are considered (right side). The dotted line represents the genomic frequency of matches to the cy motif. CDK, cyclin-dependent kinase; aa, amino acids.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
