

Including probe-level uncertainty in model-based gene expression clustering
- PMID: 17376221
- PMCID: PMC1847531
- DOI: 10.1186/1471-2105-8-98
Including probe-level uncertainty in model-based gene expression clustering
Abstract
Background: Clustering is an important analysis performed on microarray gene expression data since it groups genes which have similar expression patterns and enables the exploration of unknown gene functions. Microarray experiments are associated with many sources of experimental and biological variation and the resulting gene expression data are therefore very noisy. Many heuristic and model-based clustering approaches have been developed to cluster this noisy data. However, few of them include consideration of probe-level measurement error which provides rich information about technical variability.
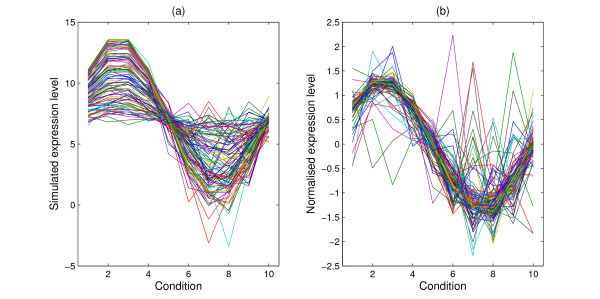
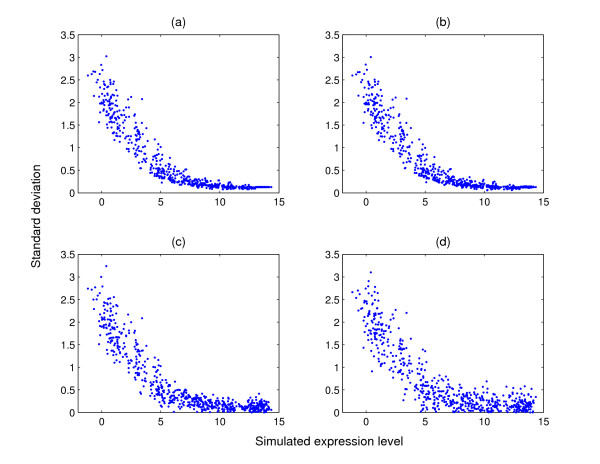
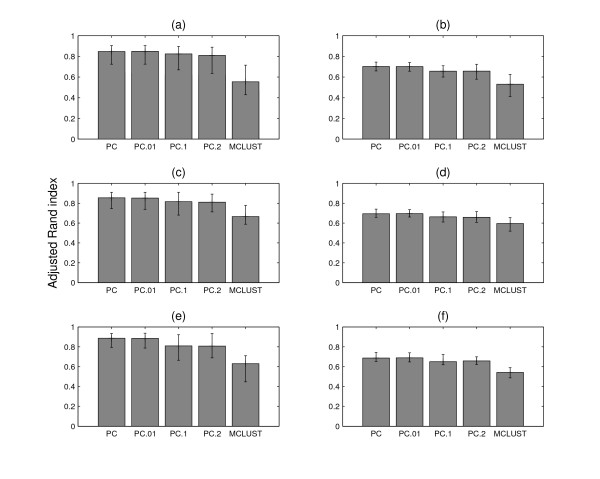
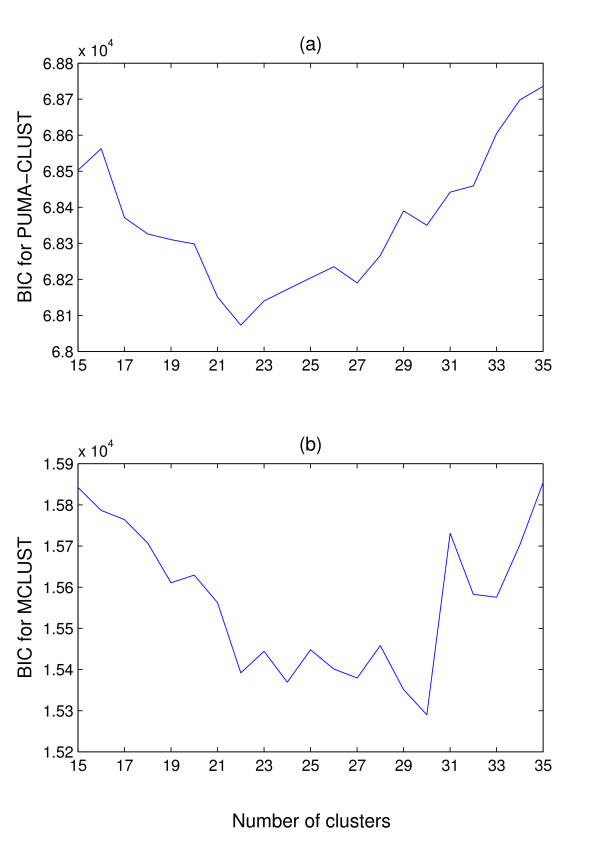
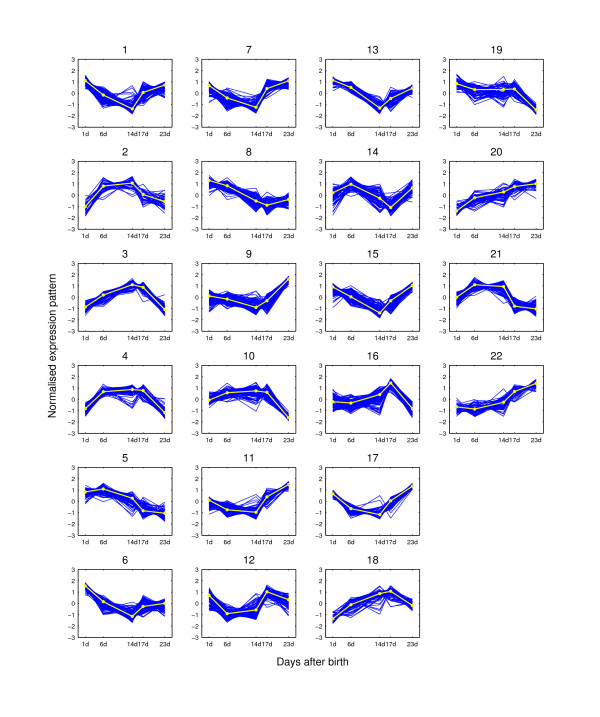
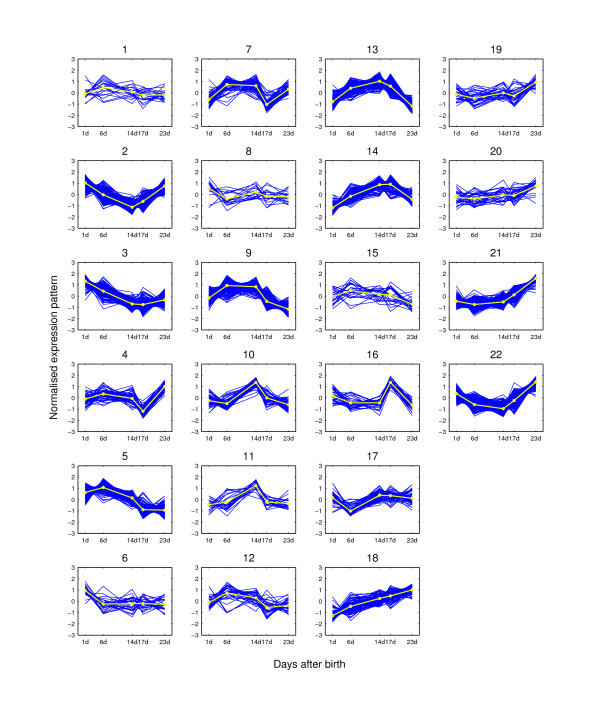
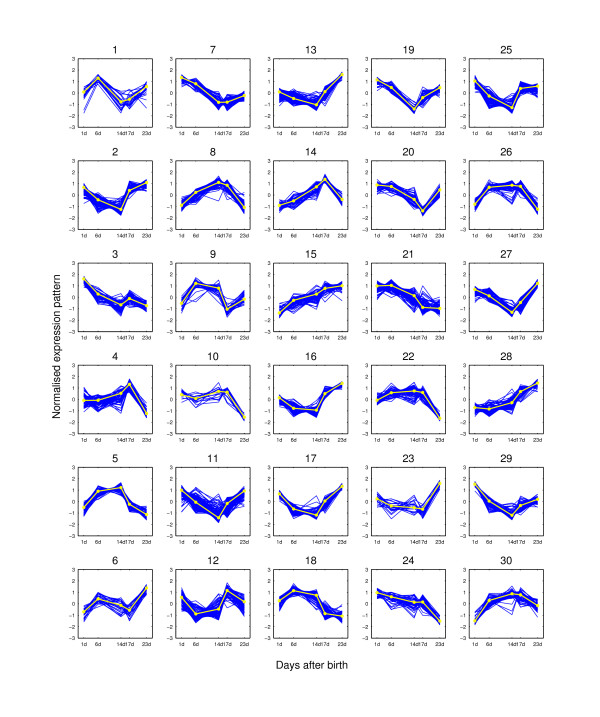
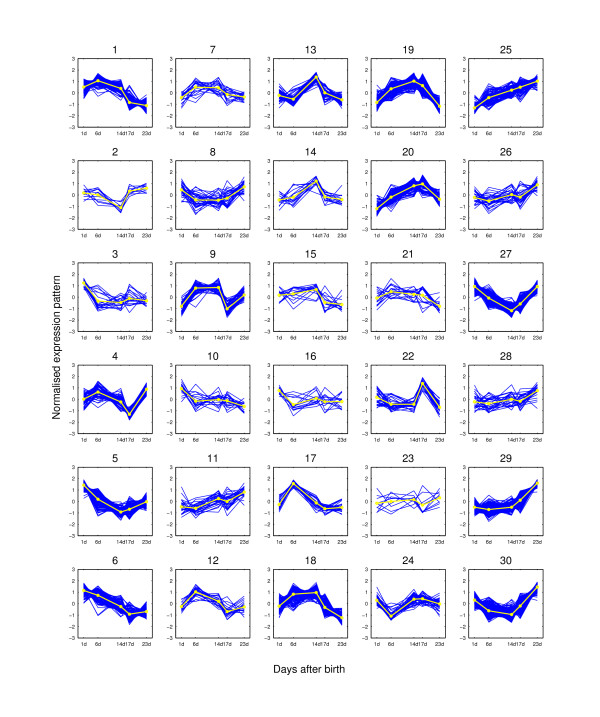
Results: We augment a standard model-based clustering method to incorporate probe-level measurement error. Using probe-level measurements from a recently developed Affymetrix probe-level model, multi-mgMOS, we include the probe-level measurement error directly into the standard Gaussian mixture model. Our augmented model is shown to provide improved clustering performance on simulated datasets and a real mouse time-course dataset.
Conclusion: The performance of model-based clustering of gene expression data is improved by including probe-level measurement error and more biologically meaningful clustering results are obtained.
Figures
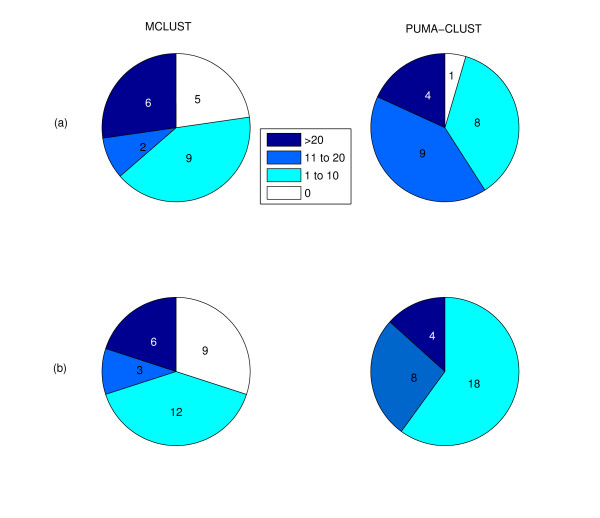
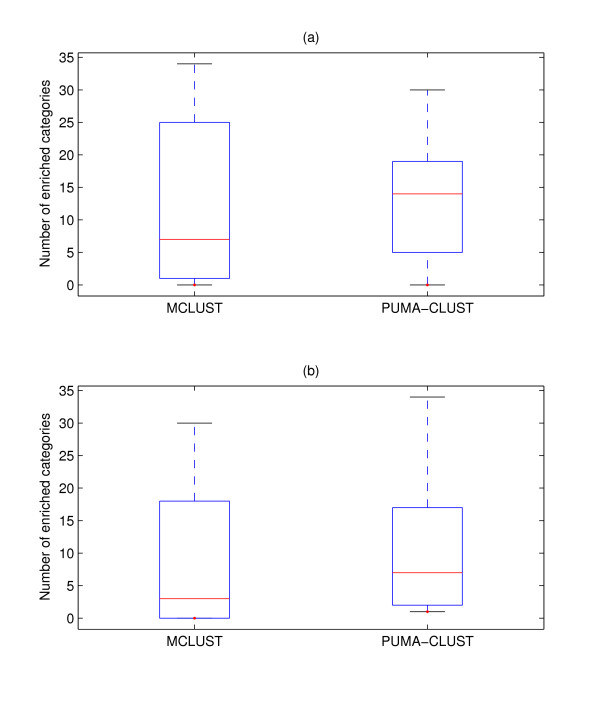
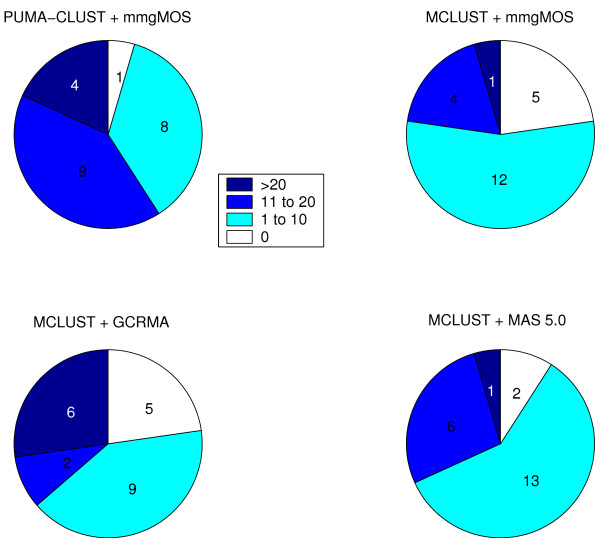
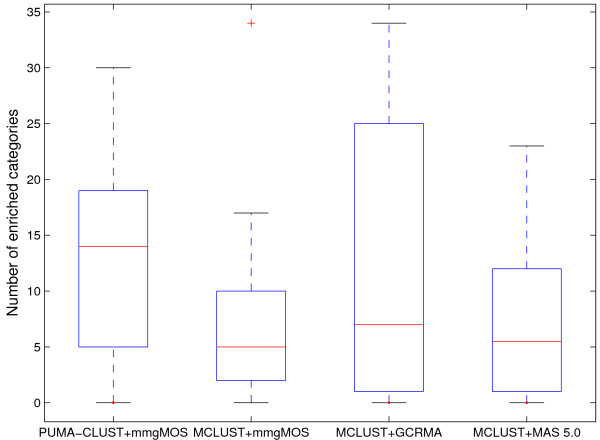
References
Publication types
MeSH terms
Substances
Grants and funding
- BBS/B/0076X/2/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- R01 AR044882/AR/NIAMS NIH HHS/United States
- BBS/B/00778/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- AR44882/AR/NIAMS NIH HHS/United States
- R21 AR052863/AR/NIAMS NIH HHS/United States
