

Transcript-based redefinition of grouped oligonucleotide probe sets using AceView: high-resolution annotation for microarrays
- PMID: 17394657
- PMCID: PMC1853115
- DOI: 10.1186/1471-2105-8-108
Transcript-based redefinition of grouped oligonucleotide probe sets using AceView: high-resolution annotation for microarrays
Abstract
Background: Extracting biological information from high-density Affymetrix arrays is a multi-step process that begins with the accurate annotation of microarray probes. Shortfalls in the original Affymetrix probe annotation have been described; however, few studies have provided rigorous solutions for routine data analysis.
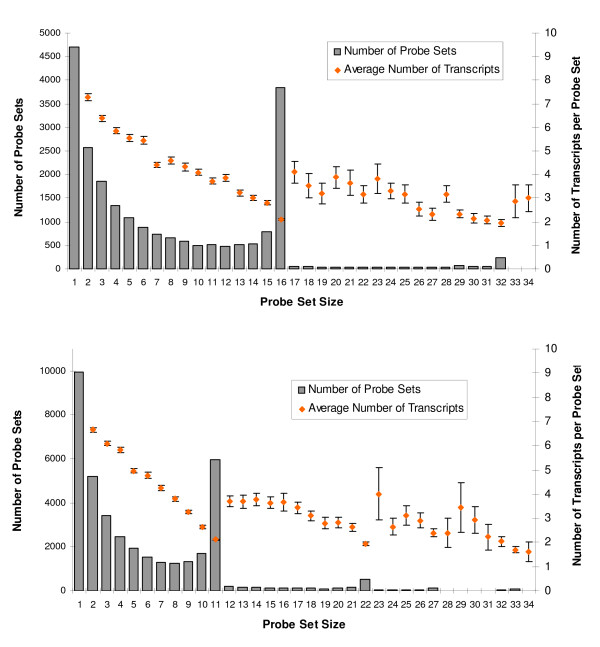
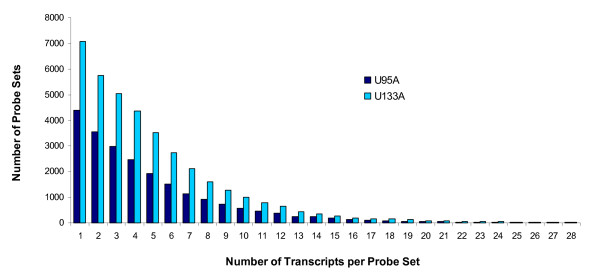
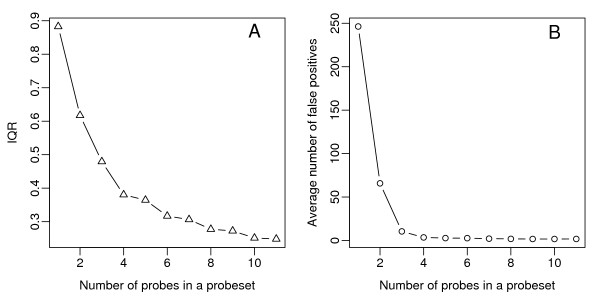
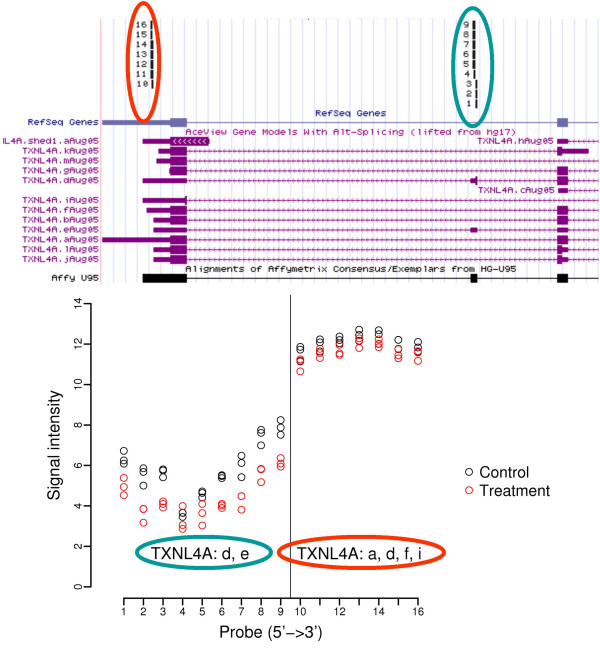
Results: Using AceView, a comprehensive human transcript database, we have reannotated the probes by matching them to RNA transcripts instead of genes. Based on this transcript-level annotation, a new probe set definition was created in which every probe in a probe set maps to a common set of AceView gene transcripts. In addition, using artificial data sets we identified that a minimal probe set size of 4 is necessary for reliable statistical summarization. We further demonstrate that applying the new probe set definition can detect specific transcript variants contributing to differential expression and it also improves cross-platform concordance.
Conclusion: We conclude that our transcript-level reannotation and redefinition of probe sets complement the original Affymetrix design. Redefinitions introduce probe sets whose sizes may not support reliable statistical summarization; therefore, we advocate using our transcript-level mapping redefinition in a secondary analysis step rather than as a replacement. Knowing which specific transcripts are differentially expressed is important to properly design probe/primer pairs for validation purposes. For convenience, we have created custom chip-description-files (CDFs) and annotation files for our new probe set definitions that are compatible with Bioconductor, Affymetrix Expression Console or third party software.
Figures


References
-
- Affymetrix MAS5 algorithm. 2006. http://www.affymetrix.com/support/technical/manual/expression_manual.affx
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
