

Query-dependent banding (QDB) for faster RNA similarity searches
- PMID: 17397253
- PMCID: PMC1847999
- DOI: 10.1371/journal.pcbi.0030056
Query-dependent banding (QDB) for faster RNA similarity searches
Abstract
When searching sequence databases for RNAs, it is desirable to score both primary sequence and RNA secondary structure similarity. Covariance models (CMs) are probabilistic models well-suited for RNA similarity search applications. However, the computational complexity of CM dynamic programming alignment algorithms has limited their practical application. Here we describe an acceleration method called query-dependent banding (QDB), which uses the probabilistic query CM to precalculate regions of the dynamic programming lattice that have negligible probability, independently of the target database. We have implemented QDB in the freely available Infernal software package. QDB reduces the average case time complexity of CM alignment from LN(2.4) to LN(1.3) for a query RNA of N residues and a target database of L residues, resulting in a 4-fold speedup for typical RNA queries. Combined with other improvements to Infernal, including informative mixture Dirichlet priors on model parameters, benchmarks also show increased sensitivity and specificity resulting from improved parameterization.
Conflict of interest statement
Figures

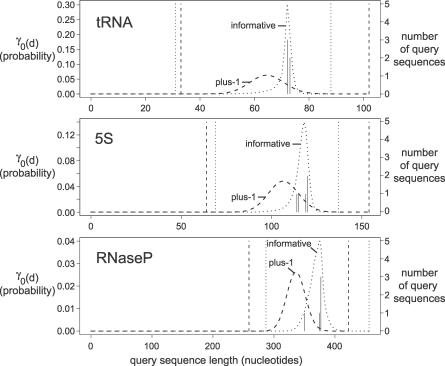
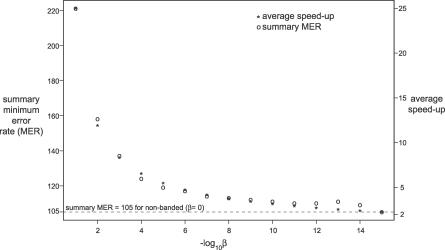

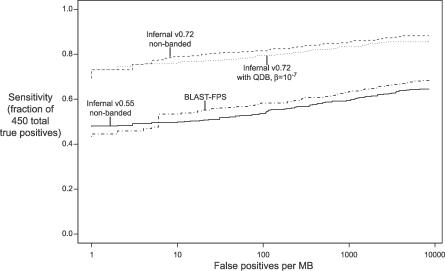
References
-
- Lowe TM, Eddy SR. A computational screen for methylation guide snoRNAs in yeast. Science. 1999;283:1168–1171. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
