

Much ado about nothing: A comparison of missing data methods and software to fit incomplete data regression models
- PMID: 17401454
- PMCID: PMC1839993
- DOI: 10.1198/000313007X172556
Much ado about nothing: A comparison of missing data methods and software to fit incomplete data regression models
Abstract
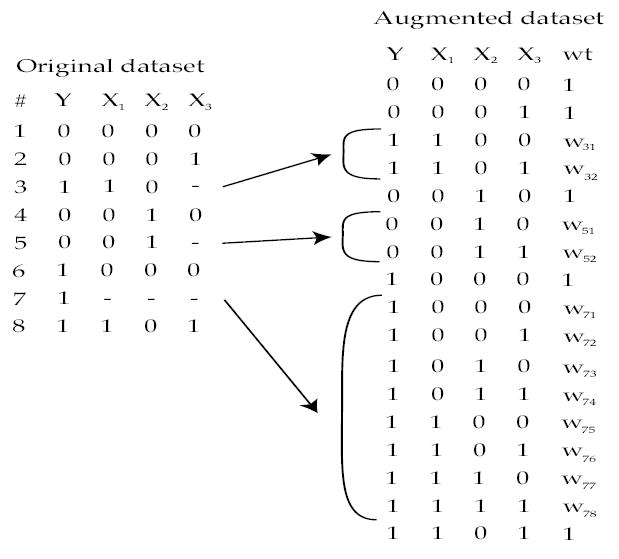
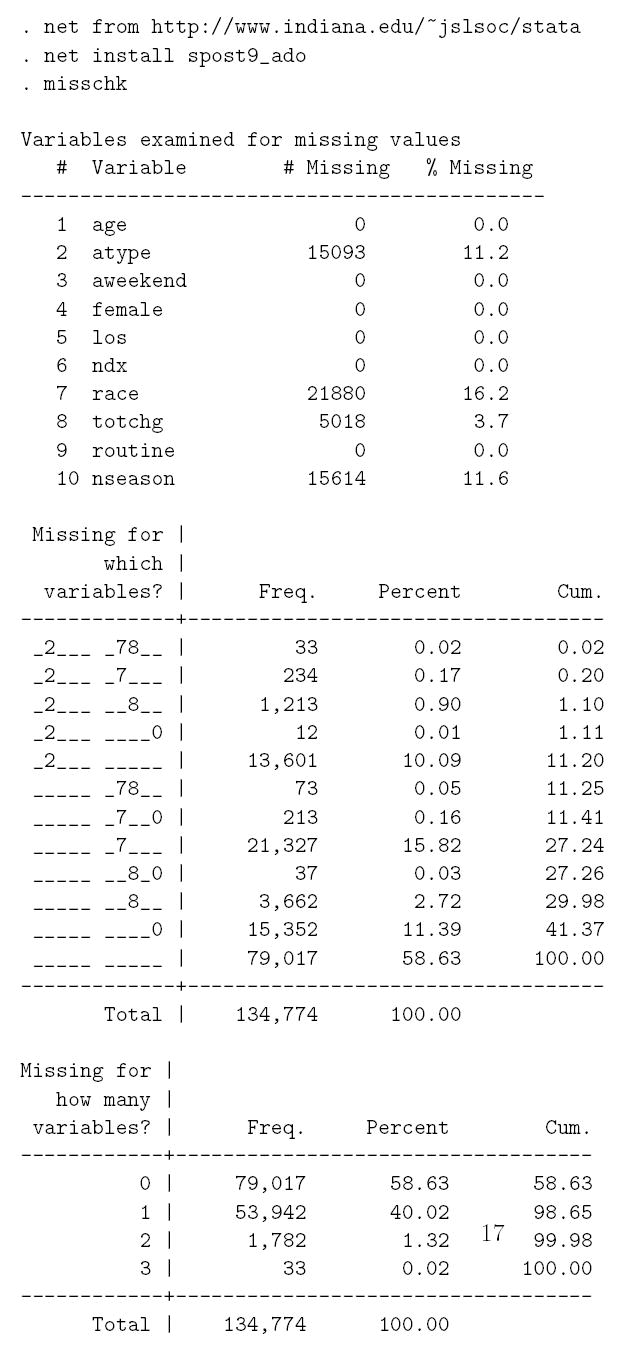
Missing data are a recurring problem that can cause bias or lead to inefficient analyses. Development of statistical methods to address missingness have been actively pursued in recent years, including imputation, likelihood and weighting approaches. Each approach is more complicated when there are many patterns of missing values, or when both categorical and continuous random variables are involved. Implementations of routines to incorporate observations with incomplete variables in regression models are now widely available. We review these routines in the context of a motivating example from a large health services research dataset. While there are still limitations to the current implementations, and additional efforts are required of the analyst, it is feasible to incorporate partially observed values, and these methods should be utilized in practice.
Figures


References
-
- Allison PD. Multiple imputation for missing data: a cautionary tale. Sociological Methods and Research. 2000;28:301–309.
-
- Allison PD. Missing data. SAGE University Papers; 2002.
-
- Allison PD. Imputation of categorical variables with PROC MI. 2005. [accessed July 30, 2006]. http://www2.sas.com/proceedings/sugi30/113-30.pdf.
-
- Barnard J, Meng XL. Applications of multiple imputation in medical studies: from AIDS to NHANES. Statistical Methods in Medical Research. 1999;8:17–36. - PubMed
-
- Bernaards CA, Belin TR, Schafer JL. Robustness of a multivariate normal approximation for imputation of incomplete binary data. Statistics in Medicine (In press) - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources