

Semiparametric bayesian inference for multilevel repeated measurement data
- PMID: 17447954
- PMCID: PMC3074472
- DOI: 10.1111/j.1541-0420.2006.00668.x
Semiparametric bayesian inference for multilevel repeated measurement data
Abstract
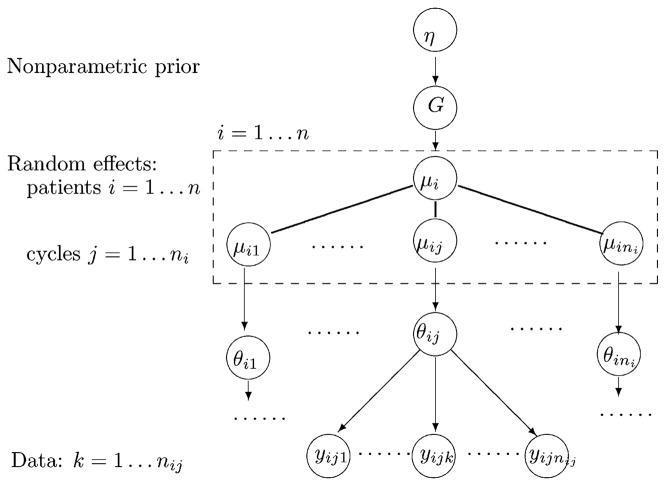
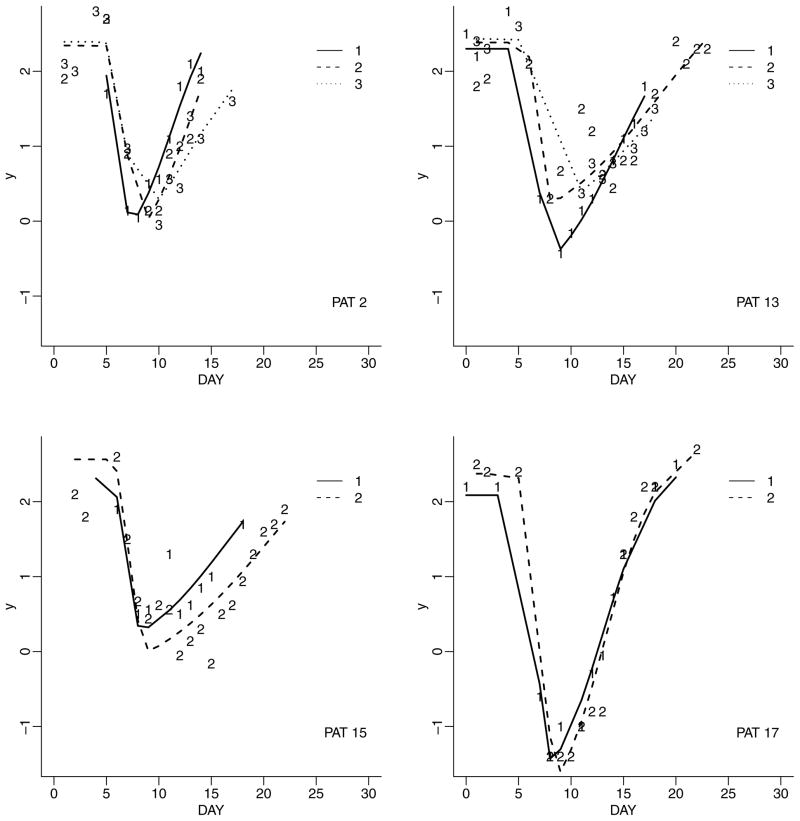
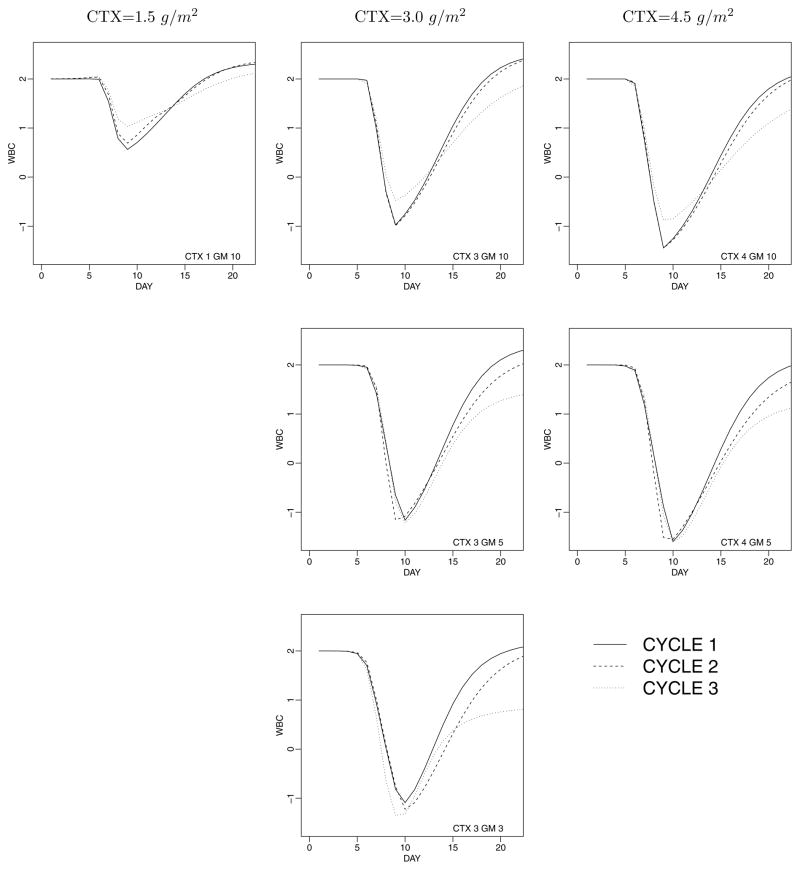
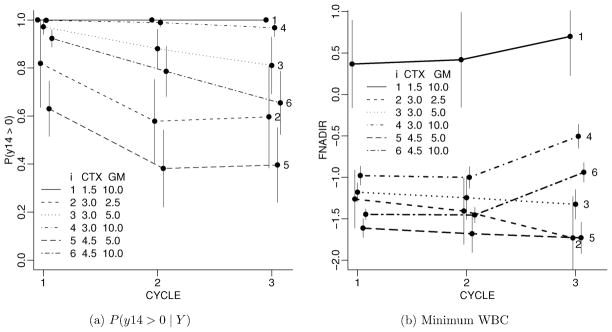
We discuss inference for data with repeated measurements at multiple levels. The motivating example is data with blood counts from cancer patients undergoing multiple cycles of chemotherapy, with days nested within cycles. Some inference questions relate to repeated measurements over days within cycle, while other questions are concerned with the dependence across cycles. When the desired inference relates to both levels of repetition, it becomes important to reflect the data structure in the model. We develop a semiparametric Bayesian modeling approach, restricting attention to two levels of repeated measurements. For the top-level longitudinal sampling model we use random effects to introduce the desired dependence across repeated measurements. We use a nonparametric prior for the random effects distribution. Inference about dependence across second-level repetition is implemented by the clustering implied in the nonparametric random effects model. Practical use of the model requires that the posterior distribution on the latent random effects be reasonably precise.
Figures
References
-
- Antoniak CE. Mixtures of Dirichlet processes with applications to Bayesian nonparametric problems. Annals of Statistics. 1974;2:1152–1174.
-
- Browne WJ, Draper D, Goldstein H, Rasbash J. Bayesian and likelihood methods for fitting multilevel models with complex level-1 variation. Computational Statistics and Data Analysis. 2002;39:203–225.
-
- Bush CA, MacEachern SN. A semiparametric Bayesian model for randomised block designs. Biometrika. 1996;83:275–285.
-
- Denison D, Holmes C, Mallick B, Smith A. Bayesian Methods for Nonlinear Classification and Regression. New York: Wiley; 2002.
-
- Ferguson TS. A Bayesian analysis of some nonparametric problems. Annals of Statistics. 1973;1:209–230.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
