

Visually-guided attention enhances target identification in a complex auditory scene
- PMID: 17453308
- PMCID: PMC2538357
- DOI: 10.1007/s10162-007-0073-z
Visually-guided attention enhances target identification in a complex auditory scene
Abstract
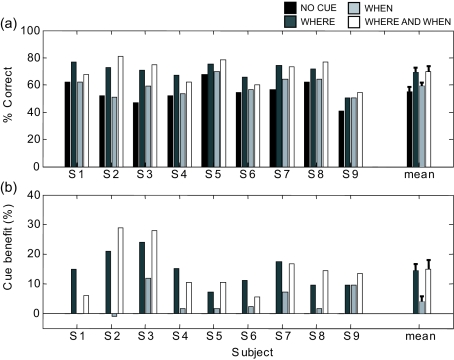
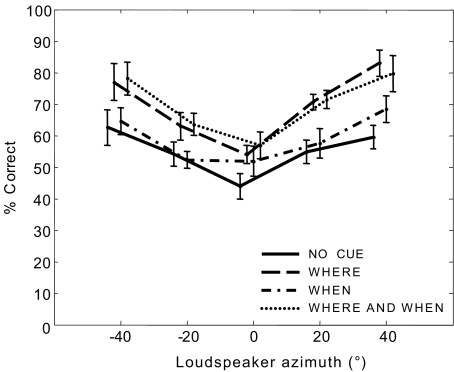
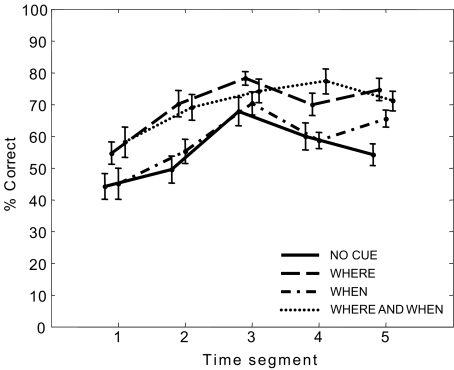
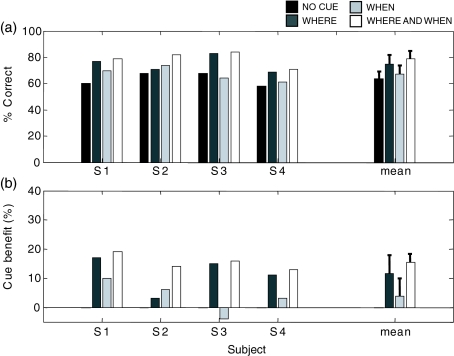
In auditory scenes containing many similar sound sources, sorting of acoustic information into streams becomes difficult, which can lead to disruptions in the identification of behaviorally relevant targets. This study investigated the benefit of providing simple visual cues for when and/or where a target would occur in a complex acoustic mixture. Importantly, the visual cues provided no information about the target content. In separate experiments, human subjects either identified learned birdsongs in the presence of a chorus of unlearned songs or recalled strings of spoken digits in the presence of speech maskers. A visual cue indicating which loudspeaker (from an array of five) would contain the target improved accuracy for both kinds of stimuli. A cue indicating which time segment (out of a possible five) would contain the target also improved accuracy, but much more for birdsong than for speech. These results suggest that in real world situations, information about where a target of interest is located can enhance its identification, while information about when to listen can also be helpful when targets are unfamiliar or extremely similar to their competitors.
Figures
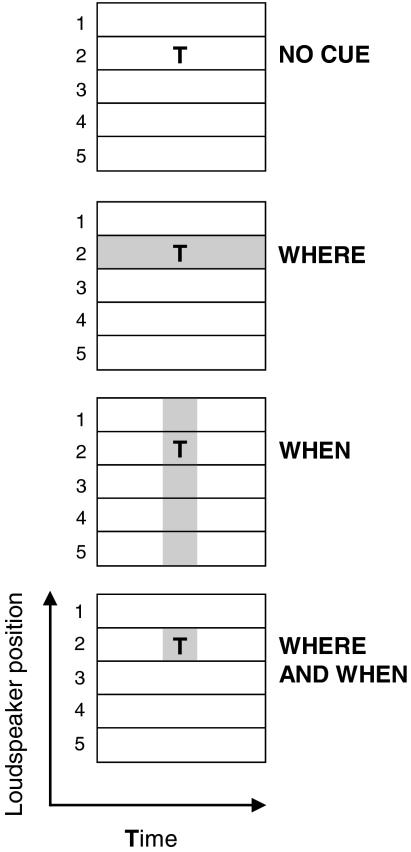
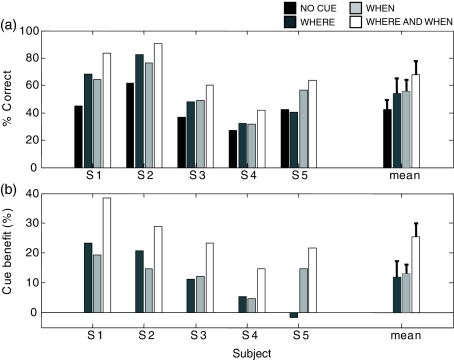
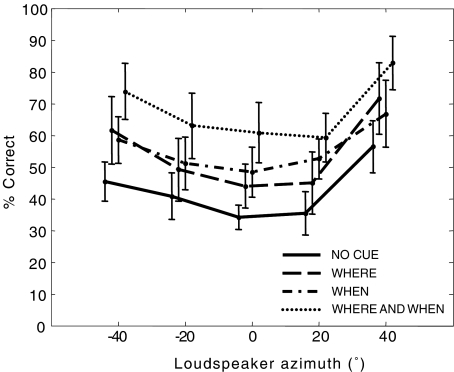
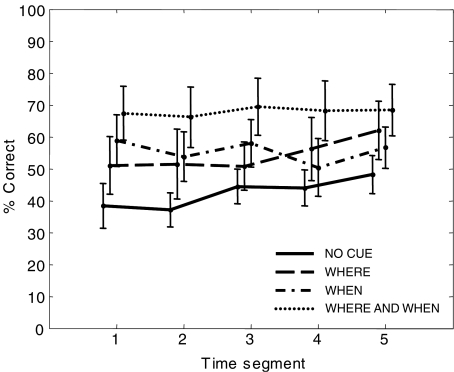
References
-
- {'text': '', 'ref_index': 1, 'ids': [{'type': 'DOI', 'value': '10.1121/1.1289366', 'is_inner': False, 'url': 'https://doi.org/10.1121/1.1289366'}, {'type': 'PubMed', 'value': '11051506', 'is_inner': True, 'url': 'https://pubmed.ncbi.nlm.nih.gov/11051506/'}]}
- Arbogast TL, Kidd G Jr. Evidence for spatial tuning in informational masking using the probe-signal method. J. Acoust. Soc. Am. 108:1803–1810, 2000. - PubMed
-
- {'text': '', 'ref_index': 1, 'ids': [{'type': 'DOI', 'value': '10.1250/ast.24.145', 'is_inner': False, 'url': 'https://doi.org/10.1250/ast.24.145'}]}
- Asemi N, Sugita Y, Suzuki Y. Auditory search asymmetry between normal Japanese speech sounds and time-reversed speech sounds distributed on the frontal-horizontal plane. Acoust. Sci. Technol. 24:145–147, 2003.
-
- {'text': '', 'ref_index': 1, 'ids': [{'type': 'DOI', 'value': '10.1038/nn1501', 'is_inner': False, 'url': 'https://doi.org/10.1038/nn1501'}, {'type': 'PMC', 'value': 'PMC1444938', 'is_inner': False, 'url': 'https://pmc.ncbi.nlm.nih.gov/articles/PMC1444938/'}, {'type': 'PubMed', 'value': '16007082', 'is_inner': True, 'url': 'https://pubmed.ncbi.nlm.nih.gov/16007082/'}]}
- Beck DM, Kastner S. Stimulus context modulates competition in human extrastriate cortex. Nat. Neurosci. 8:1110–1116, 2005. - PMC - PubMed
-
- {'text': '', 'ref_index': 1, 'ids': [{'type': 'DOI', 'value': '10.1121/1.2130949', 'is_inner': False, 'url': 'https://doi.org/10.1121/1.2130949'}, {'type': 'PubMed', 'value': '16419821', 'is_inner': True, 'url': 'https://pubmed.ncbi.nlm.nih.gov/16419821/'}]}
- Best V, Ozmeral E, Gallun FJ, Sen K, Shinn-Cunningham BG. Spatial unmasking of birdsong in human listeners: energetic and informational factors. J. Acoust. Soc. Am. 118:3766–3773, 2005. - PubMed
-
- Brungart DS, Simpson BD. Cocktail party listening in a dynamic multitalker environment. Percept. Psychophys., 2007, in press. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
