

A BAC end view of the Musa acuminata genome
- PMID: 17562019
- PMCID: PMC1904220
- DOI: 10.1186/1471-2229-7-29
A BAC end view of the Musa acuminata genome
Abstract
Background: Musa species contain the fourth most important crop in developing countries. Here, we report the analysis of 6,252 BAC end-sequences, in order to view the sequence composition of the Musa acuminata genome in a cost effective and efficient manner.
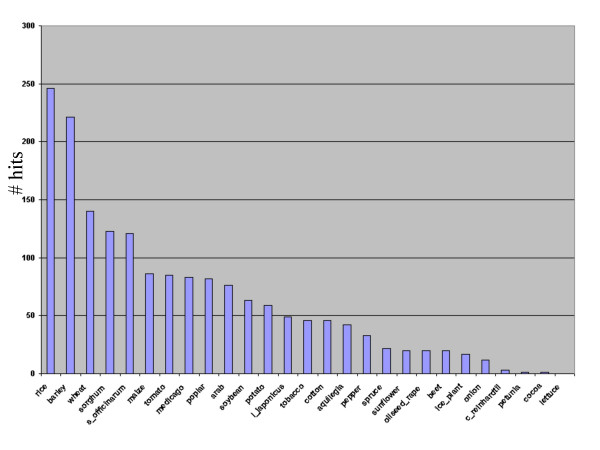
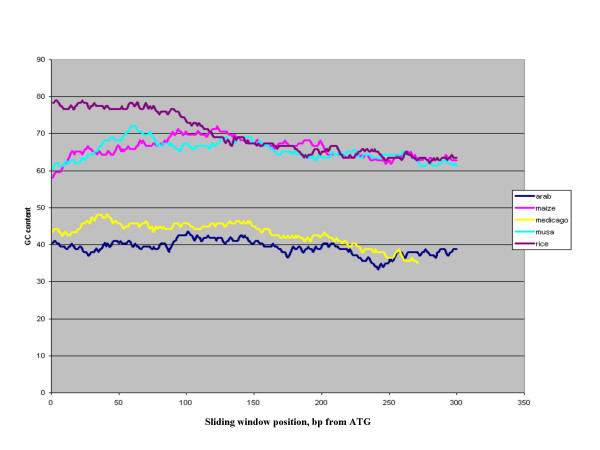
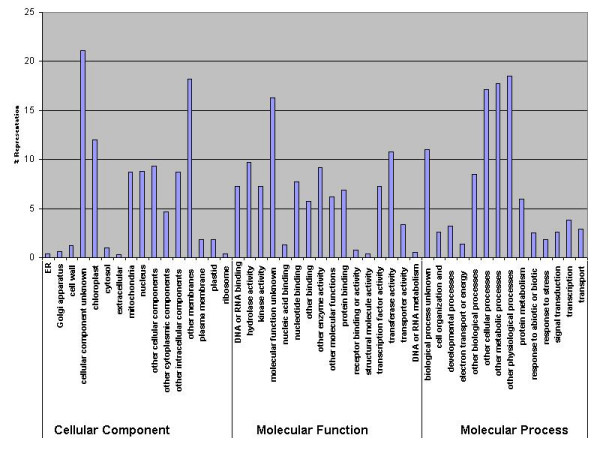
Results: BAC end sequencing generated 6,252 reads representing 4,420,944 bp, including 2,979 clone pairs with an average read length after cleaning and filtering of 707 bp. All sequences have been submitted to GenBank, with the accession numbers DX451975-DX458350. The BAC end-sequences, were searched against several databases and significant homology was found to mitochondria and chloroplast (2.6%), transposons and repetitive sequences (36%) and proteins (11%). Functional interpretation of the protein matches was carried out by Gene Ontology assignments from matches to Arabidopsis and was shown to cover a broad range of categories. From protein matching regions of Musa BAC end-sequences, it was determined that the GC content of coding regions was 47%. Where protein matches encompassed a start codon, GC content as a function of position (5' to 3') across 129 bp sliding windows generates a "rice-like" gradient. A total of 352 potential SSR markers were discovered. The most abundant simple sequence repeats in four size categories were AT-rich. After filtering mitochondria and chloroplast matches, thousands of BAC end-sequences had a significant BLASTN match to the Oryza sativa and Arabidopsis genome sequence. Of these, a small number of BAC end-sequence pairs were shown to map to neighboring regions of the Oryza sativa genome representing regions of potential microsynteny.
Conclusion: Database searches with the BAC end-sequences and ab initio analysis identified those reads likely to contain transposons, repeat sequences, proteins and simple sequence repeats. Approximately 600 BAC end-sequences contained protein sequences that were not found in the existing available Musa expressed sequence tags, repeat or transposon databases. In addition, gene statistics, GC content and profile could also be estimated based on the region matching the top protein hit. A small number of BAC end pair sequences can be mapped to neighboring regions of the Oryza sativa representing regions of potential microsynteny. These results suggest that a large-scale BAC end sequencing strategy has the potential to anchor a small proportion of the genome of Musa acuminata to the genomes of Oryza sativa and possibly Arabidopsis.
Figures
References
-
- Meinke DW, Cherry JM, Dean C, Rounsley SD, Koornneef M. Arabidopsis thaliana: a model plant for genome analysis. Science. 1998;662:679–682. - PubMed
-
- Zhao W, Wang J, He X, Huang X, Jiao Y, Dai M, Wei S, Fu J, Chen Y, Ren X, Zhang Y, Ni P, Zhang J, Li S, Wang J, Wong GK, Zhao H, Yu J, Yang H, Wang J. BGI-RIS, An integrated information resource and comparative analysis workbench for rice genomics. Nucleic Acids Res. 2004;32:D377–82. doi: 10.1093/nar/gkh085. - DOI - PMC - PubMed
-
- Lysak MA, Dolezelova M, Horry JP, Swennen R, Dolezel J. Flow cytometric analysis of nuclear DNA content in Musa. Theor Appl Genet. 1999;98:1344–1350. doi: 10.1007/s001220051201. - DOI
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
