

Evolutionary conservation of a coding function for D4Z4, the tandem DNA repeat mutated in facioscapulohumeral muscular dystrophy
- PMID: 17668377
- PMCID: PMC1950813
- DOI: 10.1086/519311
Evolutionary conservation of a coding function for D4Z4, the tandem DNA repeat mutated in facioscapulohumeral muscular dystrophy
Abstract
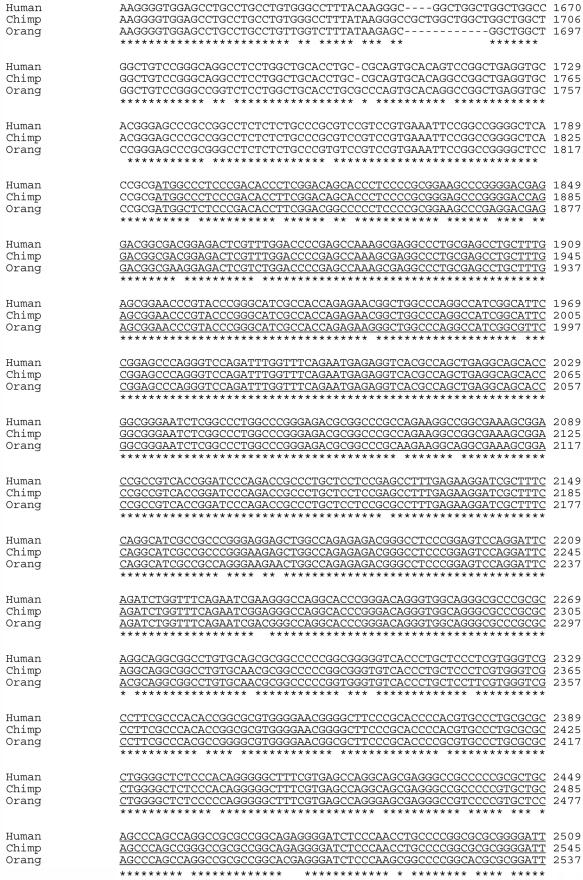
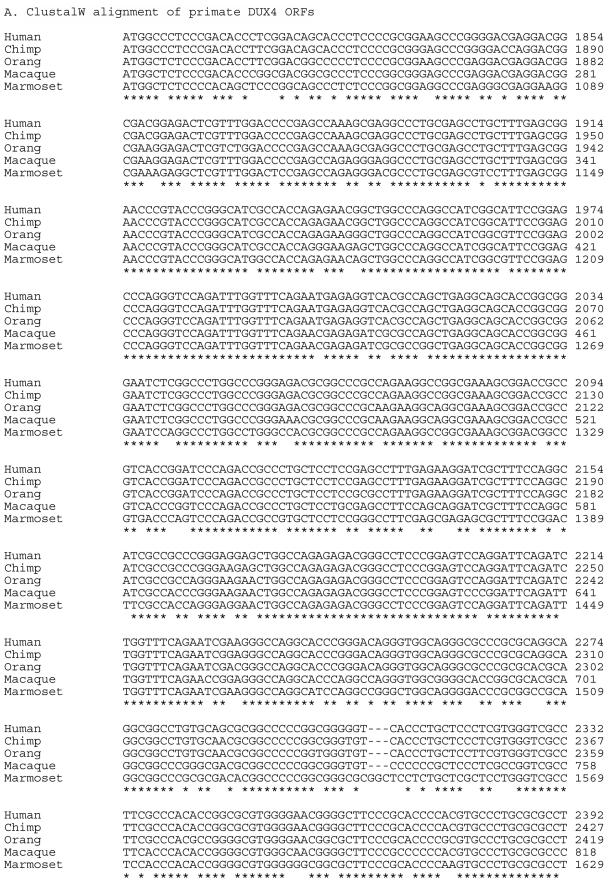
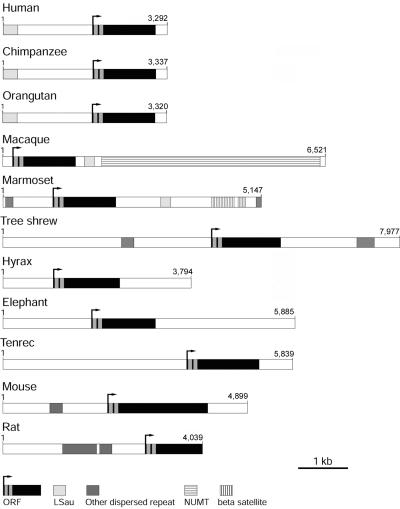
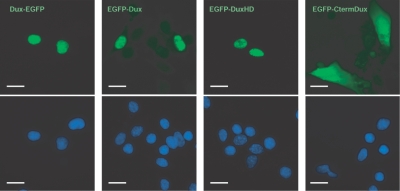
Facioscapulohumeral muscular dystrophy (FSHD) is caused by deletions within the polymorphic DNA tandem array D4Z4. Each D4Z4 repeat unit has an open reading frame (ORF), termed "DUX4," containing two homeobox sequences. Because there has been no evidence of a transcript from the array, these deletions are thought to cause FSHD by a position effect on other genes. Here, we identify D4Z4 homologues in the genomes of rodents, Afrotheria (superorder of elephants and related species), and other species and show that the DUX4 ORF is conserved. Phylogenetic analysis suggests that primate and Afrotherian D4Z4 arrays are orthologous and originated from a retrotransposed copy of an intron-containing DUX gene, DUXC. Reverse-transcriptase polymerase chain reaction and RNA fluorescence and tissue in situ hybridization data indicate transcription of the mouse array. Together with the conservation of the DUX4 ORF for >100 million years, this strongly supports a coding function for D4Z4 and necessitates re-examination of current models of the FSHD disease mechanism.
Figures










References
Web Resources
-
- ClustalW, http://www.ebi.ac.uk/clustalw/
-
- EMBL, http://www.ebi.ac.uk/embl/ (for accession numbers AF117653, AC135091, AM398147–AM398151, BN000980–BN000984, and BN000988–BN000990)
-
- Ensembl, http://www.ensembl.org/index.html
-
- GenBank, http://www.ncbi.nlm.nih.gov/Genbank/ (for accession number NM_027375)
References
-
- Padberg GW (2004) Facioscapulohumeral muscular dystrophy. In: Upadhyaya M, Cooper DN (eds) Facioscapulohumeral muscular dystrophy (FSHD): clinical medicine and molecular cell biology. BIOS Scientific Publishers, Oxford, United Kindgom, pp 41–54
-
- Deidda G, Cacurri S, Grisanti P, Vigneti E, Piazzo N, Felicetti L (1995) Physical mapping evidence for a duplicated region on chromosome 10qter showing high homology with the FSHD locus on chromosome 4qter. Eur J Hum Genet 3:155–167 - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
