

Automated protein subfamily identification and classification
- PMID: 17708678
- PMCID: PMC1950344
- DOI: 10.1371/journal.pcbi.0030160
Automated protein subfamily identification and classification
Abstract
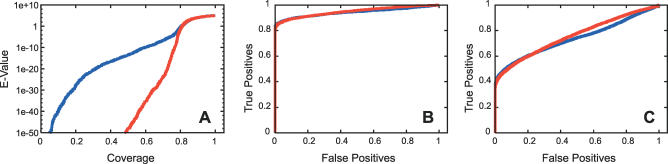
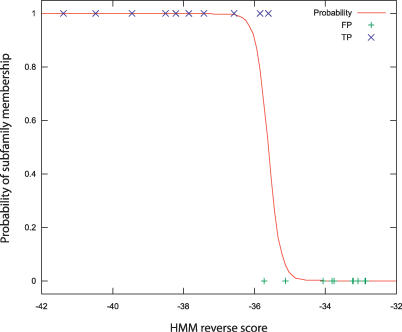
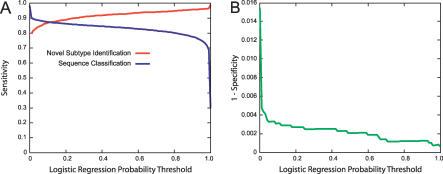
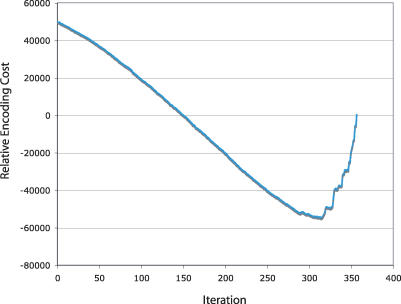
Function prediction by homology is widely used to provide preliminary functional annotations for genes for which experimental evidence of function is unavailable or limited. This approach has been shown to be prone to systematic error, including percolation of annotation errors through sequence databases. Phylogenomic analysis avoids these errors in function prediction but has been difficult to automate for high-throughput application. To address this limitation, we present a computationally efficient pipeline for phylogenomic classification of proteins. This pipeline uses the SCI-PHY (Subfamily Classification in Phylogenomics) algorithm for automatic subfamily identification, followed by subfamily hidden Markov model (HMM) construction. A simple and computationally efficient scoring scheme using family and subfamily HMMs enables classification of novel sequences to protein families and subfamilies. Sequences representing entirely novel subfamilies are differentiated from those that can be classified to subfamilies in the input training set using logistic regression. Subfamily HMM parameters are estimated using an information-sharing protocol, enabling subfamilies containing even a single sequence to benefit from conservation patterns defining the family as a whole or in related subfamilies. SCI-PHY subfamilies correspond closely to functional subtypes defined by experts and to conserved clades found by phylogenetic analysis. Extensive comparisons of subfamily and family HMM performances show that subfamily HMMs dramatically improve the separation between homologous and non-homologous proteins in sequence database searches. Subfamily HMMs also provide extremely high specificity of classification and can be used to predict entirely novel subtypes. The SCI-PHY Web server at http://phylogenomics.berkeley.edu/SCI-PHY/ allows users to upload a multiple sequence alignment for subfamily identification and subfamily HMM construction. Biologists wishing to provide their own subfamily definitions can do so. Source code is available on the Web page. The Berkeley Phylogenomics Group PhyloFacts resource contains pre-calculated subfamily predictions and subfamily HMMs for more than 40,000 protein families and domains at http://phylogenomics.berkeley.edu/phylofacts/.
Conflict of interest statement
Figures

References
-
- Friedberg I. Automated protein function prediction—The genomic challenge. Brief Bioinform. 2006;7:225–242. - PubMed
-
- Soro S, Tramontano A. The prediction of protein function at CASP6. Proteins. 2005;61(Supplement 7):201–213. - PubMed
-
- Andrade MA, Brown NP, Leroy C, et al. Automated genome sequence analysis and annotation. Bioinformatics. 1999;15:391–412. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
