

Cross-modal object recognition is viewpoint-independent
- PMID: 17849019
- PMCID: PMC1964535
- DOI: 10.1371/journal.pone.0000890
Cross-modal object recognition is viewpoint-independent
Abstract
Background: Previous research suggests that visual and haptic object recognition are viewpoint-dependent both within- and cross-modally. However, this conclusion may not be generally valid as it was reached using objects oriented along their extended y-axis, resulting in differential surface processing in vision and touch. In the present study, we removed this differential by presenting objects along the z-axis, thus making all object surfaces more equally available to vision and touch.
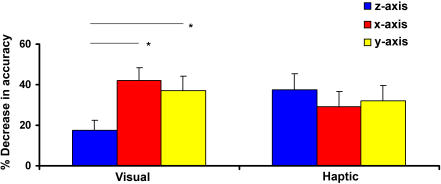
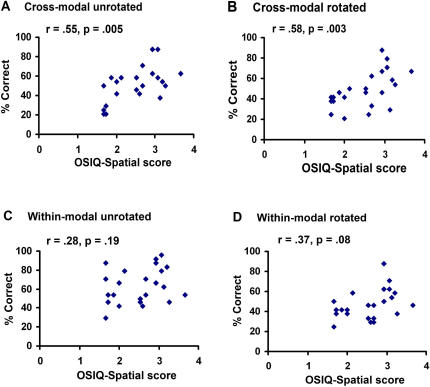
Methodology/principal findings: Participants studied previously unfamiliar objects, in groups of four, using either vision or touch. Subsequently, they performed a four-alternative forced-choice object identification task with the studied objects presented in both unrotated and rotated (180 degrees about the x-, y-, and z-axes) orientations. Rotation impaired within-modal recognition accuracy in both vision and touch, but not cross-modal recognition accuracy. Within-modally, visual recognition accuracy was reduced by rotation about the x- and y-axes more than the z-axis, whilst haptic recognition was equally affected by rotation about all three axes. Cross-modal (but not within-modal) accuracy correlated with spatial (but not object) imagery scores.
Conclusions/significance: The viewpoint-independence of cross-modal object identification points to its mediation by a high-level abstract representation. The correlation between spatial imagery scores and cross-modal performance suggest that construction of this high-level representation is linked to the ability to perform spatial transformations. Within-modal viewpoint-dependence appears to have a different basis in vision than in touch, possibly due to surface occlusion being important in vision but not touch.
Conflict of interest statement
Figures



References
-
- Jolicoeur P. The time to name disoriented objects. Mem Cognition, 1985;13:289–303. - PubMed
-
- Newell FN, Ernst MO, Tjan BS, Bulthoff HH. Viewpoint dependence in visual and haptic object recognition. Psychol Sci, 2001;12:37–42. - PubMed
-
- Klatzky RL, Lederman S, Reed C. There's more to touch than meets the eye: The salience of object attributes for haptics with and without vision. J Exp Psychol: Gen, 1987;116:356–369.
-
- Reales JM, Ballesteros S. Implicit and explicit memory for visual and haptic objects: Cross-modal priming depends on structural descriptions. J Exp Psychol: Learn, 1999;25:644–663.
-
- Heller MA, Brackett DD, Scroggs E, Steffen H, Heatherly K, et al. Tangible pictures: Viewpoint effects and linear perspective in visually impaired people. Perception, 2002;31:747–769. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
