

GISSD: Group I Intron Sequence and Structure Database
- PMID: 17942415
- PMCID: PMC2238919
- DOI: 10.1093/nar/gkm766
GISSD: Group I Intron Sequence and Structure Database
Abstract
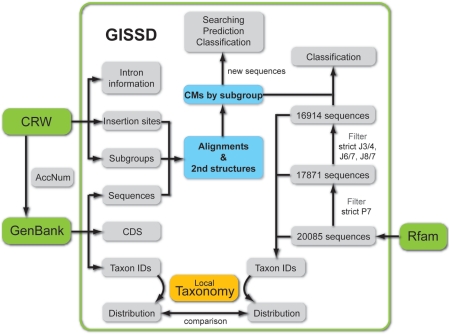
Group I Intron Sequence and Structure Database (GISSD) is a specialized and comprehensive database for group I introns, focusing on the integration of useful group I intron information from available databases and providing de novo data that is essential for understanding these introns at a systematic level. This database presents 1789 complete intron records, including the nucleotide sequence of each annotated intron plus 15 nt of the upstream and downstream exons, and the pseudoknots-containing secondary structures predicted by integrating comparative sequence analyses and minimal free energy algorithms. These introns represent all 14 subgroups, with their structure-based alignments being separately provided. Both structure predictions and alignments were done manually and iteratively adjusted, which yielded a reliable consensus structure for each subgroup. These consensus structures allowed us to judge the confidence of 20 085 group I introns previously found by the INFERNAL program and to classify them into subgroups automatically. The database provides intron-associated taxonomy information from GenBank, allowing one to view the detailed distribution of all group I introns. CDSs residing in introns and 3D structure information are also integrated if available. About 17 000 group I introns have been validated in this database; approximately 95% of them belong to the IC3 subgroup and reside in the chloroplast tRNA(Leu) gene. The GISSD database can be accessed at http://www.rna.whu.edu.cn/gissd/
Figures


Similar articles
-
The IDB and IEDB: intron sequence and evolution databases.Nucleic Acids Res. 2000 Jan 1;28(1):181-4. doi: 10.1093/nar/28.1.181. Nucleic Acids Res. 2000. PMID: 10592220 Free PMC article.
-
Rfam: an RNA family database.Nucleic Acids Res. 2003 Jan 1;31(1):439-41. doi: 10.1093/nar/gkg006. Nucleic Acids Res. 2003. PMID: 12520045 Free PMC article.
-
The tmRNA Website: invasion by an intron.Nucleic Acids Res. 2002 Jan 1;30(1):179-82. doi: 10.1093/nar/30.1.179. Nucleic Acids Res. 2002. PMID: 11752287 Free PMC article.
-
Advances in the Exon-Intron Database (EID).Brief Bioinform. 2006 Jun;7(2):178-85. doi: 10.1093/bib/bbl003. Epub 2006 Mar 9. Brief Bioinform. 2006. PMID: 16772261 Review.
-
Comparative and functional anatomy of group II catalytic introns--a review.Gene. 1989 Oct 15;82(1):5-30. doi: 10.1016/0378-1119(89)90026-7. Gene. 1989. PMID: 2684776 Review.
Cited by
-
A Phylogenetic Approach to Structural Variation in Organization of Nuclear Group I Introns and Their Ribozymes.Noncoding RNA. 2021 Jul 22;7(3):43. doi: 10.3390/ncrna7030043. Noncoding RNA. 2021. PMID: 34449660 Free PMC article.
-
LAHEDES: the LAGLIDADG homing endonuclease database and engineering server.Nucleic Acids Res. 2012 Jul;40(Web Server issue):W110-6. doi: 10.1093/nar/gks365. Epub 2012 May 8. Nucleic Acids Res. 2012. PMID: 22570419 Free PMC article.
-
RNArchitecture: a database and a classification system of RNA families, with a focus on structural information.Nucleic Acids Res. 2018 Jan 4;46(D1):D202-D205. doi: 10.1093/nar/gkx966. Nucleic Acids Res. 2018. PMID: 29069520 Free PMC article.
-
Single molecule fluorescence approaches shed light on intracellular RNAs.Chem Rev. 2014 Mar 26;114(6):3224-65. doi: 10.1021/cr400496q. Epub 2014 Jan 8. Chem Rev. 2014. PMID: 24417544 Free PMC article. Review. No abstract available.
-
Convergent evolution of twintron-like configurations: One is never enough.RNA Biol. 2015;12(12):1275-88. doi: 10.1080/15476286.2015.1103427. RNA Biol. 2015. PMID: 26513606 Free PMC article. Review.
References
-
- Cech T.R. Self-splicing of group I introns. Annu. Rev. Biochem. 1990;59:543–568. - PubMed
-
- Vicens Q., Cech T.R. Atomic level architecture of group I introns revealed. Trends Biochem. Sci. 2006;31:41–51. - PubMed
-
- Michel F., Westhof E. Modelling of the three-dimensional architecture of group I catalytic introns based on comparative sequence analysis. J. Mol. Biol. 1990;216:585–610. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
