

ChemBank: a small-molecule screening and cheminformatics resource database
- PMID: 17947324
- PMCID: PMC2238881
- DOI: 10.1093/nar/gkm843
ChemBank: a small-molecule screening and cheminformatics resource database
Abstract
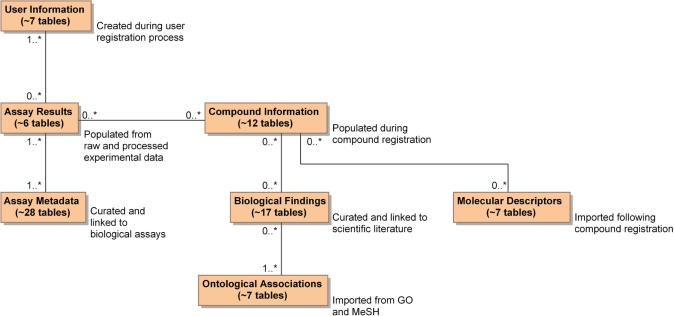
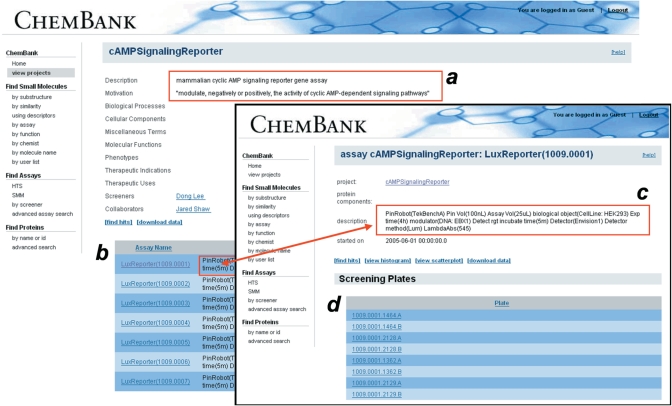
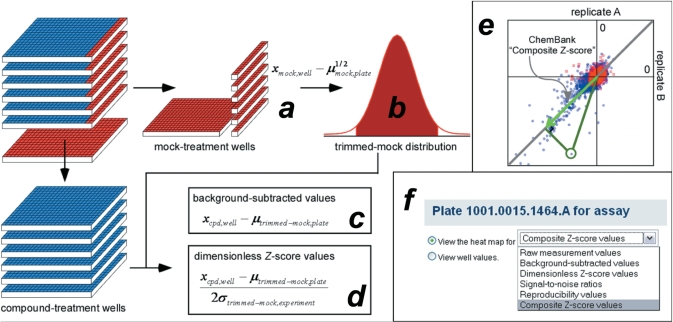
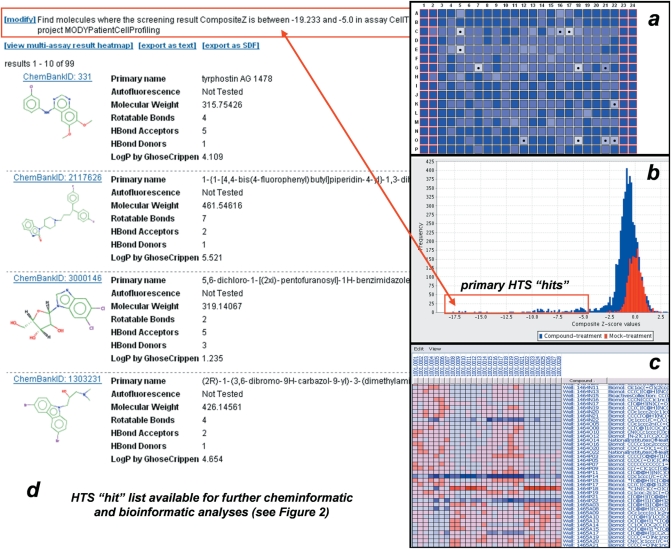
ChemBank (http://chembank.broad.harvard.edu/) is a public, web-based informatics environment developed through a collaboration between the Chemical Biology Program and Platform at the Broad Institute of Harvard and MIT. This knowledge environment includes freely available data derived from small molecules and small-molecule screens and resources for studying these data. ChemBank is unique among small-molecule databases in its dedication to the storage of raw screening data, its rigorous definition of screening experiments in terms of statistical hypothesis testing, and its metadata-based organization of screening experiments into projects involving collections of related assays. ChemBank stores an increasingly varied set of measurements derived from cells and other biological assay systems treated with small molecules. Analysis tools are available and are continuously being developed that allow the relationships between small molecules, cell measurements, and cell states to be studied. Currently, ChemBank stores information on hundreds of thousands of small molecules and hundreds of biomedically relevant assays that have been performed at the Broad Institute by collaborators from the worldwide research community. The goal of ChemBank is to provide life scientists unfettered access to biomedically relevant data and tools heretofore available primarily in the private sector.
Figures

References
-
- Strausberg RL, Schreiber SL. From knowing to controlling: a path from genomics to drugs using small molecule probes. Science. 2003;300:294–295. - PubMed
-
- Tolliday N, Clemons PA, Ferraiolo P, Koehler AN, Lewis TA, Li X, Schreiber SL, Gerhard DS, Eliasof S. Small molecules, big players: the National Cancer Institute's Initiative for Chemical Genetics. Cancer Res. 2006;66:8935–8942. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
