

Evolution of the genetic code: partial optimization of a random code for robustness to translation error in a rugged fitness landscape
- PMID: 17956616
- PMCID: PMC2211284
- DOI: 10.1186/1745-6150-2-24
Evolution of the genetic code: partial optimization of a random code for robustness to translation error in a rugged fitness landscape
Abstract
Background: The standard genetic code table has a distinctly non-random structure, with similar amino acids often encoded by codons series that differ by a single nucleotide substitution, typically, in the third or the first position of the codon. It has been repeatedly argued that this structure of the code results from selective optimization for robustness to translation errors such that translational misreading has the minimal adverse effect. Indeed, it has been shown in several studies that the standard code is more robust than a substantial majority of random codes. However, it remains unclear how much evolution the standard code underwent, what is the level of optimization, and what is the likely starting point.
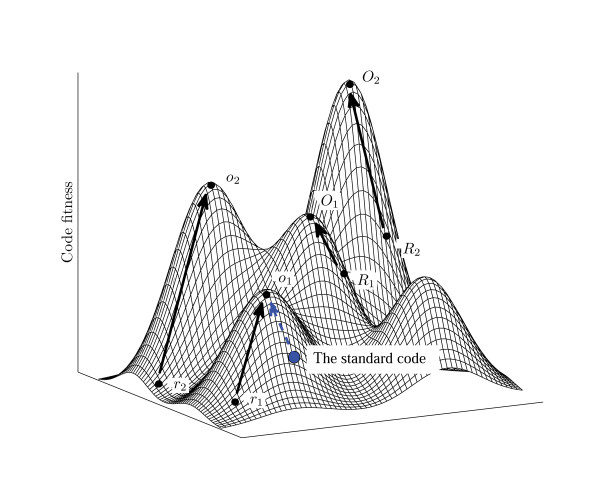
Results: We explored possible evolutionary trajectories of the genetic code within a limited domain of the vast space of possible codes. Only those codes were analyzed for robustness to translation error that possess the same block structure and the same degree of degeneracy as the standard code. This choice of a small part of the vast space of possible codes is based on the notion that the block structure of the standard code is a consequence of the structure of the complex between the cognate tRNA and the codon in mRNA where the third base of the codon plays a minimum role as a specificity determinant. Within this part of the fitness landscape, a simple evolutionary algorithm, with elementary evolutionary steps comprising swaps of four-codon or two-codon series, was employed to investigate the optimization of codes for the maximum attainable robustness. The properties of the standard code were compared to the properties of four sets of codes, namely, purely random codes, random codes that are more robust than the standard code, and two sets of codes that resulted from optimization of the first two sets. The comparison of these sets of codes with the standard code and its locally optimized version showed that, on average, optimization of random codes yielded evolutionary trajectories that converged at the same level of robustness to translation errors as the optimization path of the standard code; however, the standard code required considerably fewer steps to reach that level than an average random code. When evolution starts from random codes whose fitness is comparable to that of the standard code, they typically reach much higher level of optimization than the standard code, i.e., the standard code is much closer to its local minimum (fitness peak) than most of the random codes with similar levels of robustness. Thus, the standard genetic code appears to be a point on an evolutionary trajectory from a random point (code) about half the way to the summit of the local peak. The fitness landscape of code evolution appears to be extremely rugged, containing numerous peaks with a broad distribution of heights, and the standard code is relatively unremarkable, being located on the slope of a moderate-height peak.
Conclusion: The standard code appears to be the result of partial optimization of a random code for robustness to errors of translation. The reason the code is not fully optimized could be the trade-off between the beneficial effect of increasing robustness to translation errors and the deleterious effect of codon series reassignment that becomes increasingly severe with growing complexity of the evolving system. Thus, evolution of the code can be represented as a combination of adaptation and frozen accident.
Figures
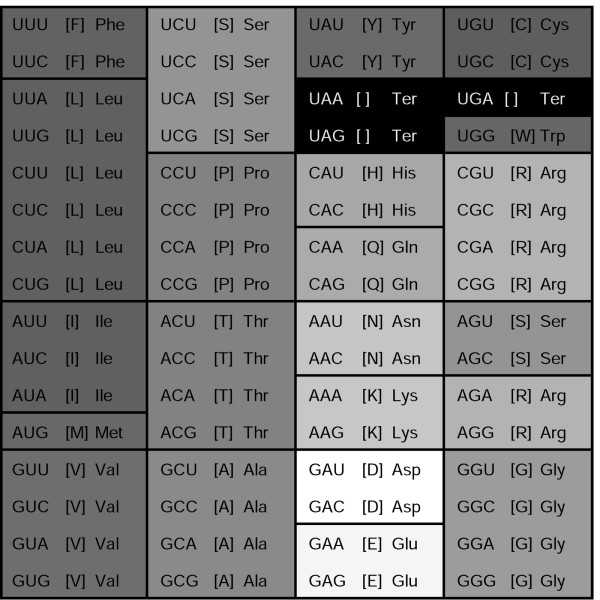
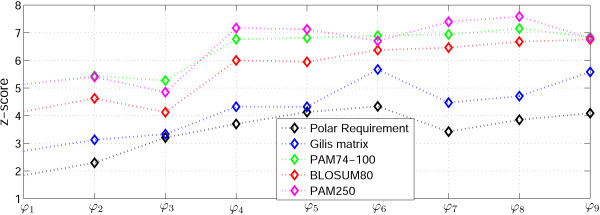
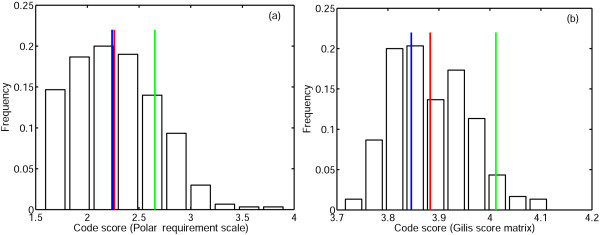
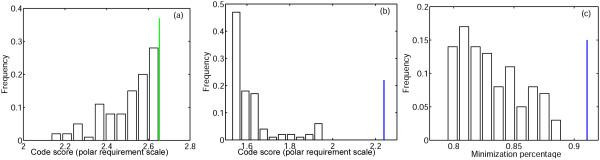
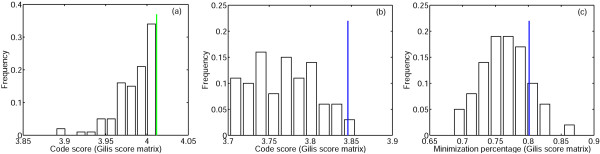
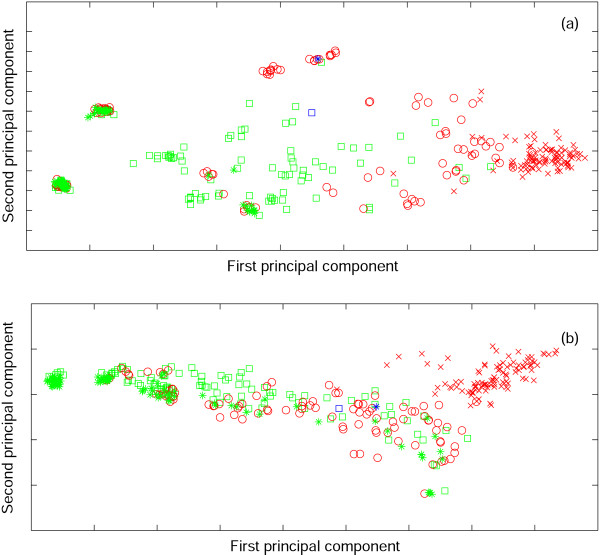
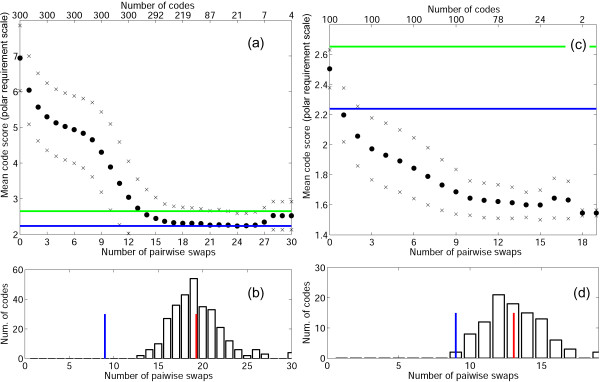
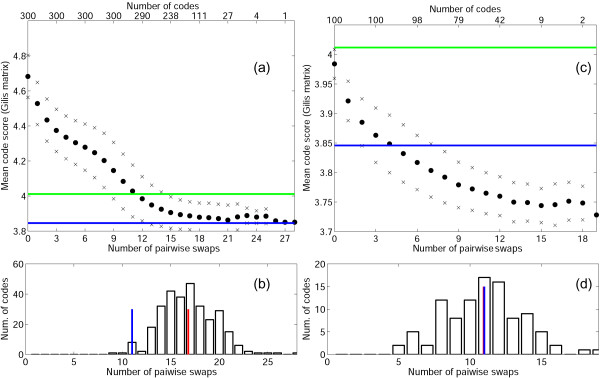
References
-
- Nirenberg MW, Jones W, Leder P, Clark BFC, Sly WS, Pestka S. On the Coding of Genetic Information. Cold Spring Harb Symp Quant Biol. 1963;28:549–558.
-
- Crick FH. Codon--anticodon pairing: the wobble hypothesis. J Mol Biol. 1966;19:548–555. - PubMed
-
- Woese C. The genetic code: the molecular basis for genetic expression. New York , Harper & Row; 1967.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
