

DAVID Knowledgebase: a gene-centered database integrating heterogeneous gene annotation resources to facilitate high-throughput gene functional analysis
- PMID: 17980028
- PMCID: PMC2186358
- DOI: 10.1186/1471-2105-8-426
DAVID Knowledgebase: a gene-centered database integrating heterogeneous gene annotation resources to facilitate high-throughput gene functional analysis
Abstract
Background: Due to the complex and distributed nature of biological research, our current biological knowledge is spread over many redundant annotation databases maintained by many independent groups. Analysts usually need to visit many of these bioinformatics databases in order to integrate comprehensive annotation information for their genes, which becomes one of the bottlenecks, particularly for the analytic task associated with a large gene list. Thus, a highly centralized and ready-to-use gene-annotation knowledgebase is in demand for high throughput gene functional analysis.
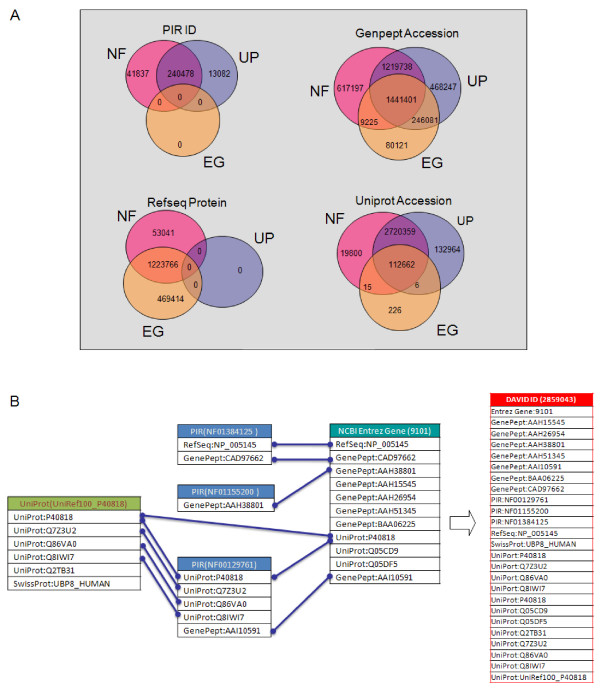
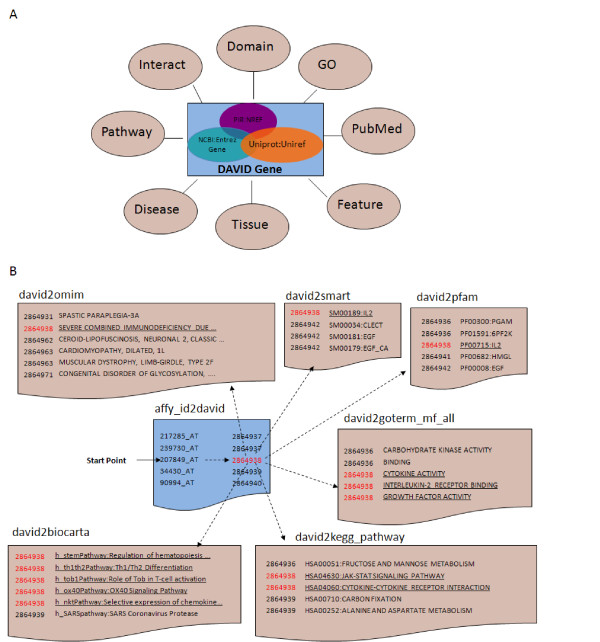
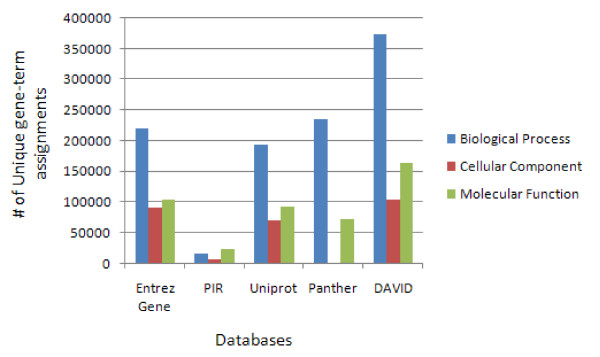
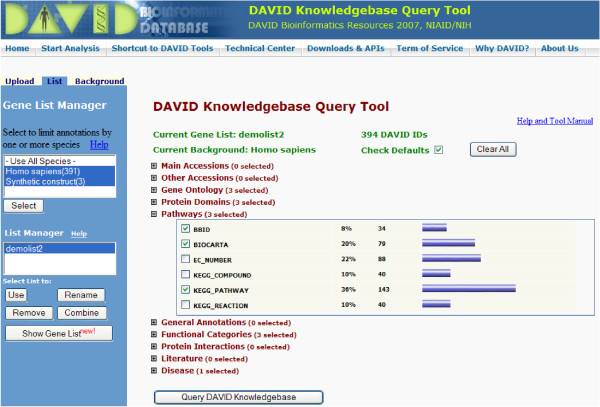
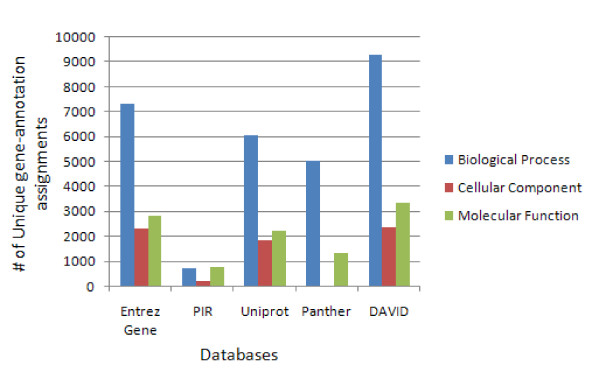
Description: The DAVID Knowledgebase is built around the DAVID Gene Concept, a single-linkage method to agglomerate tens of millions of gene/protein identifiers from a variety of public genomic resources into DAVID gene clusters. The grouping of such identifiers improves the cross-reference capability, particularly across NCBI and UniProt systems, enabling more than 40 publicly available functional annotation sources to be comprehensively integrated and centralized by the DAVID gene clusters. The simple, pair-wise, text format files which make up the DAVID Knowledgebase are freely downloadable for various data analysis uses. In addition, a well organized web interface allows users to query different types of heterogeneous annotations in a high-throughput manner.
Conclusion: The DAVID Knowledgebase is designed to facilitate high throughput gene functional analysis. For a given gene list, it not only provides the quick accessibility to a wide range of heterogeneous annotation data in a centralized location, but also enriches the level of biological information for an individual gene. Moreover, the entire DAVID Knowledgebase is freely downloadable or searchable at http://david.abcc.ncifcrf.gov/knowledgebase/.
Figures
References
-
- Diehn M, Sherlock G, Binkley G, Jin H, Matese JC, Hernandez-Boussard T, Rees CA, Cherry JM, Botstein D, Brown PO, Alizadeh AA. SOURCE: a unified genomic resource of functional annotations, ontologies, and gene expression data. Nucleic Acids Res. 2003;31:219–223. doi: 10.1093/nar/gkg014. - DOI - PMC - PubMed
-
- Tsai J, Sultana R, Lee Y, Pertea G, Karamycheva S, Antonescu V, Cho J, Parvizi B, Cheung F, Quackenbush J. RESOURCERER: a database for annotating and linking microarray resources within and across species. Genome Biol. 2001;2:SOFTWARE0002. doi: 10.1186/gb-2001-2-11-software0002. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
