

SVM clustering
- PMID: 18047717
- PMCID: PMC2099486
- DOI: 10.1186/1471-2105-8-S7-S18
SVM clustering
Abstract
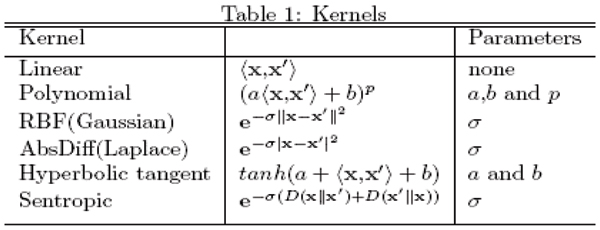
Background: Support Vector Machines (SVMs) provide a powerful method for classification (supervised learning). Use of SVMs for clustering (unsupervised learning) is now being considered in a number of different ways.
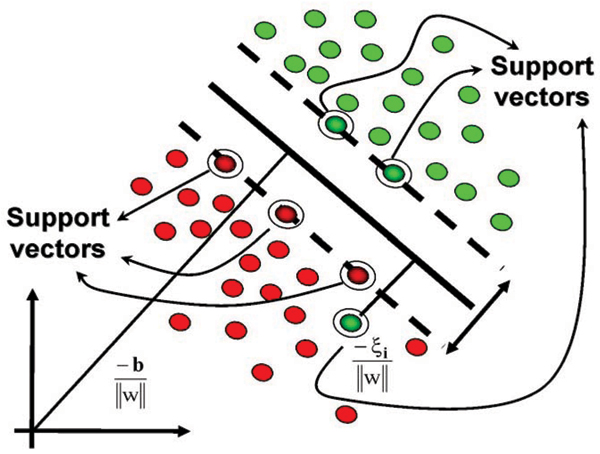
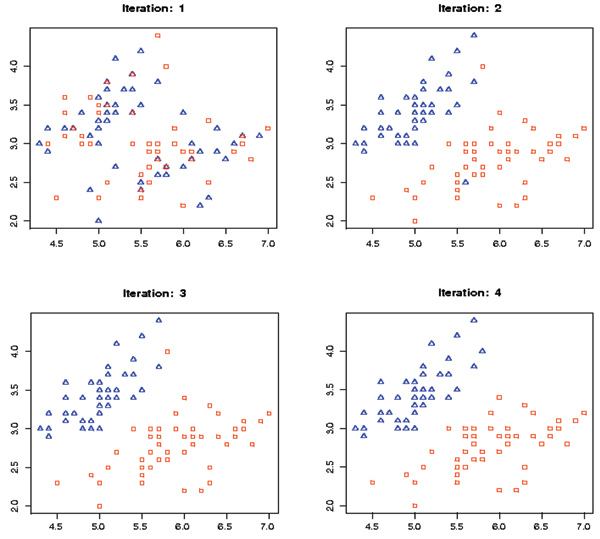
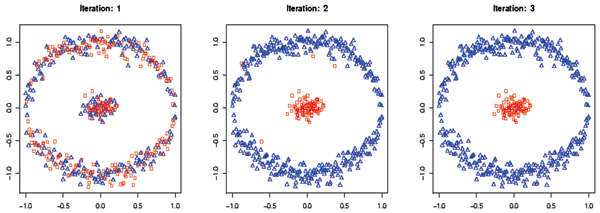
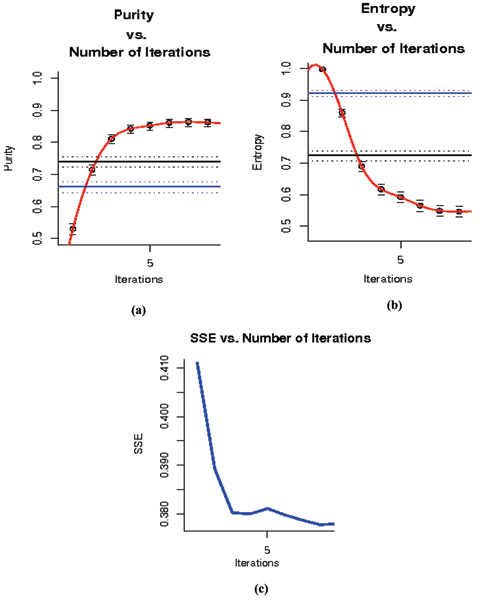
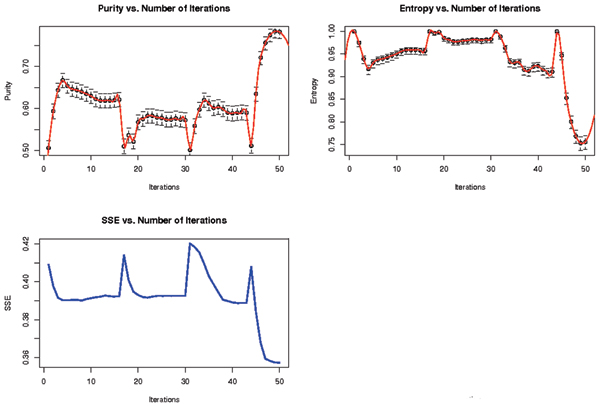
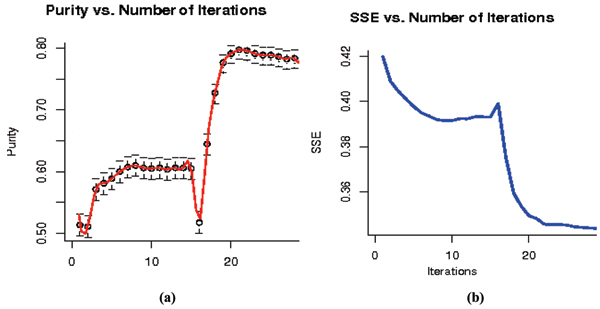
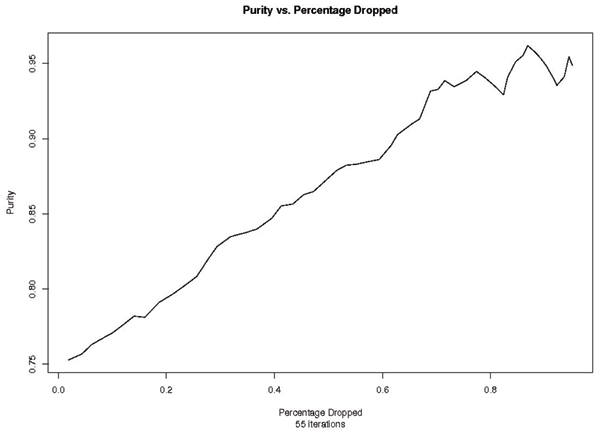
Results: An SVM-based clustering algorithm is introduced that clusters data with no a priori knowledge of input classes. The algorithm initializes by first running a binary SVM classifier against a data set with each vector in the set randomly labelled, this is repeated until an initial convergence occurs. Once this initialization step is complete, the SVM confidence parameters for classification on each of the training instances can be accessed. The lowest confidence data (e.g., the worst of the mislabelled data) then has its' labels switched to the other class label. The SVM is then re-run on the data set (with partly re-labelled data) and is guaranteed to converge in this situation since it converged previously, and now it has fewer data points to carry with mislabelling penalties. This approach appears to limit exposure to the local minima traps that can occur with other approaches. Thus, the algorithm then improves on its weakly convergent result by SVM re-training after each re-labeling on the worst of the misclassified vectors - i.e., those feature vectors with confidence factor values beyond some threshold. The repetition of the above process improves the accuracy, here a measure of separability, until there are no misclassifications. Variations on this type of clustering approach are shown.
Conclusion: Non-parametric SVM-based clustering methods may allow for much improved performance over parametric approaches, particularly if they can be designed to inherit the strengths of their supervised SVM counterparts.
Figures
References
-
- Vapnik VN. The Nature of Statistical Learning Theory. 2. Springer-Verlag, New York; 1998.
-
- Burges CJC. A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov. 1998;2:121–67. doi: 10.1023/A:1009715923555. - DOI
-
- Kumar V, Tan P, Steinbach M. Introduction to data mining. Pearson Education, Inc; 2006.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
