

Towards completion of the Earth's proteome
- PMID: 18059312
- PMCID: PMC2267224
- DOI: 10.1038/sj.embor.7401117
Towards completion of the Earth's proteome
Abstract
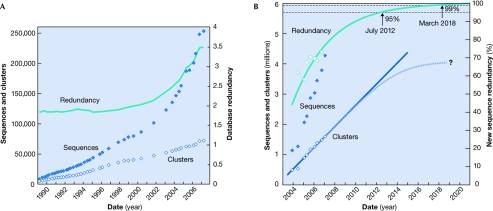
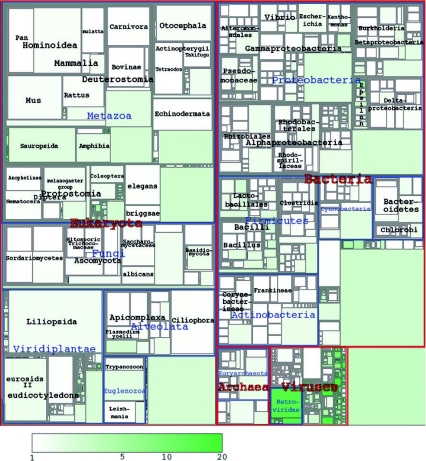
New protein sequences are deposited in databases at an accelerating pace; however, many of these are homologous to known proteins and could be considered redundant. If all historical releases of the protein database are analysed using the original sequence-clustering procedure described here, the fraction of newly sequenced proteins that are redundant is increasing. We interpret this as an indication that the sequencing of the Earth's proteome--the complete set of proteins on Earth--is approaching completion. We estimate the approximate size of the Earth's proteome to be 5 million sequences, most of which will be identified during the next 5 years. As the Earth's proteome nears completion, cluster analysis of the protein database will become essential to identify under-explored taxa to which future sequencing efforts should be directed and to focus research on protein families without experimental characterization.
Figures



References
-
- Adam GC, Sorensen EJ, Cravatt BF (2002) Chemical strategies for functional proteomics. Mol Cell Proteomics 1: 781–790 - PubMed
-
- Adams MD, Dubnick M, Kerlavage AR, Moreno R, Kelley JM, Utterback TR, Nagle JW, Fields C, Venter JC (1992) Sequence identification of 2,375 human brain genes. Nature 355: 632–634 - PubMed
-
- Casari G, Andrade MA, Bork P, Boyle J, Daruvar A, Ouzounis C, Schneider R, Tamames J, Valencia A, Sander C (1995) Challenging times for bioinformatics. Nature 376: 647–648 - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
