

PlantTribes: a gene and gene family resource for comparative genomics in plants
- PMID: 18073194
- PMCID: PMC2238917
- DOI: 10.1093/nar/gkm972
PlantTribes: a gene and gene family resource for comparative genomics in plants
Abstract
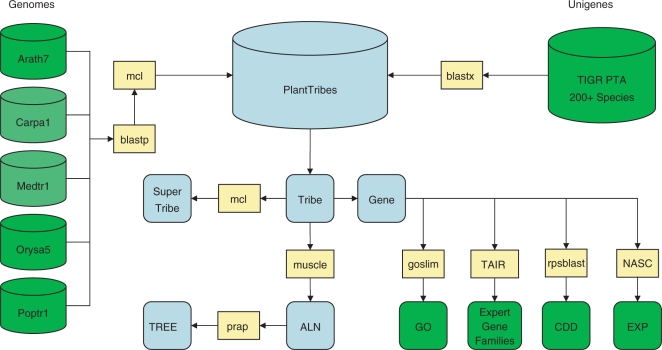
The PlantTribes database (http://fgp.huck.psu.edu/tribe.html) is a plant gene family database based on the inferred proteomes of five sequenced plant species: Arabidopsis thaliana, Carica papaya, Medicago truncatula, Oryza sativa and Populus trichocarpa. We used the graph-based clustering algorithm MCL [Van Dongen (Technical Report INS-R0010 2000) and Enright et al. (Nucleic Acids Res. 2002; 30: 1575-1584)] to classify all of these species' protein-coding genes into putative gene families, called tribes, using three clustering stringencies (low, medium and high). For all tribes, we have generated protein and DNA alignments and maximum-likelihood phylogenetic trees. A parallel database of microarray experimental results is linked to the genes, which lets researchers identify groups of related genes and their expression patterns. Unified nomenclatures were developed, and tribes can be related to traditional gene families and conserved domain identifiers. SuperTribes, constructed through a second iteration of MCL clustering, connect distant, but potentially related gene clusters. The global classification of nearly 200 000 plant proteins was used as a scaffold for sorting approximately 4 million additional cDNA sequences from over 200 plant species. All data and analyses are accessible through a flexible interface allowing users to explore the classification, to place query sequences within the classification, and to download results for further study.
Figures

References
-
- Van Dongen S. Technical Report INS-R0010. 2000. A cluster algorithm for graphs.
