

Determinants of protein abundance and translation efficiency in S. cerevisiae
- PMID: 18159940
- PMCID: PMC2230678
- DOI: 10.1371/journal.pcbi.0030248
Determinants of protein abundance and translation efficiency in S. cerevisiae
Abstract
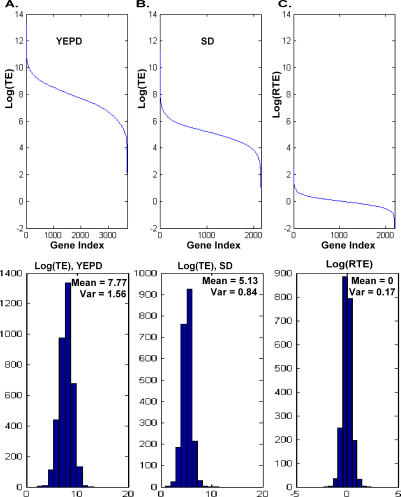
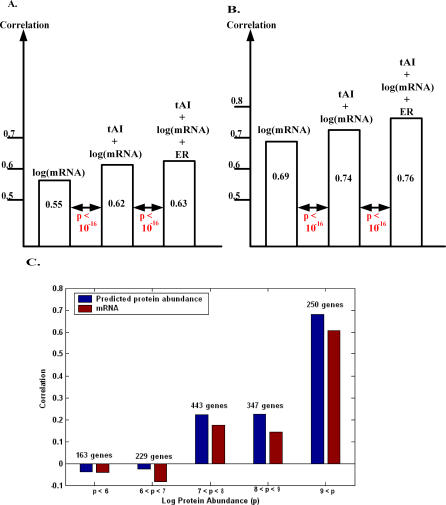
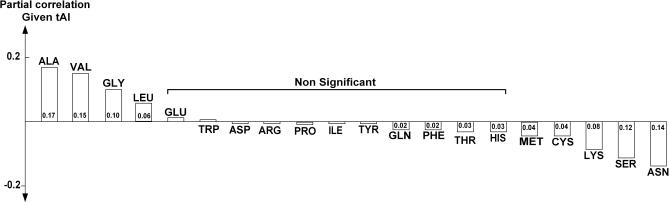
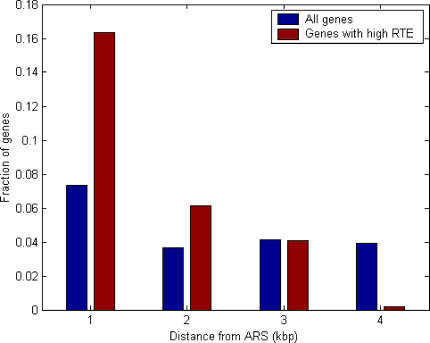
The translation efficiency of most Saccharomyces cerevisiae genes remains fairly constant across poor and rich growth media. This observation has led us to revisit the available data and to examine the potential utility of a protein abundance predictor in reinterpreting existing mRNA expression data. Our predictor is based on large-scale data of mRNA levels, the tRNA adaptation index, and the evolutionary rate. It attains a correlation of 0.76 with experimentally determined protein abundance levels on unseen data and successfully cross-predicts protein abundance levels in another yeast species (Schizosaccharomyces pombe). The predicted abundance levels of proteins in known S. cerevisiae complexes, and of interacting proteins, are significantly more coherent than their corresponding mRNA expression levels. Analysis of gene expression measurement experiments using the predicted protein abundance levels yields new insights that are not readily discernable when clustering the corresponding mRNA expression levels. Comparing protein abundance levels across poor and rich media, we find a general trend for homeostatic regulation where transcription and translation change in a reciprocal manner. This phenomenon is more prominent near origins of replications. Our analysis shows that in parallel to the adaptation occurring at the tRNA level via the codon bias, proteins do undergo a complementary adaptation at the amino acid level to further increase their abundance.
Conflict of interest statement
Figures
References
-
- Ghaemmaghami S, Huh WK, Bower K, Howson RW, Belle A, et al. Global analysis of protein expression in yeast. Nature. 2003;425:737–741. - PubMed
-
- Greenbaum D, Jansen R, Gerstein M. Analysis of mRNA expression and protein abundance data: An approach for the comparison of the enrichment of features in the cellular population of proteins and transcripts. Bioinformatics. 2002;18:585–596. - PubMed
-
- Newman JRS, Ghaemmaghami S, Ihmels J, Breslow DK, Noble M, et al. Single-cell proteomic analysis of S. Cerevisiae reveals the architecture of biological noise. Nature. 2006;441:840–846. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
