

Spectral and temporal cues for speech recognition: implications for auditory prostheses
- PMID: 18249077
- PMCID: PMC2610393
- DOI: 10.1016/j.heares.2007.12.010
Spectral and temporal cues for speech recognition: implications for auditory prostheses
Abstract
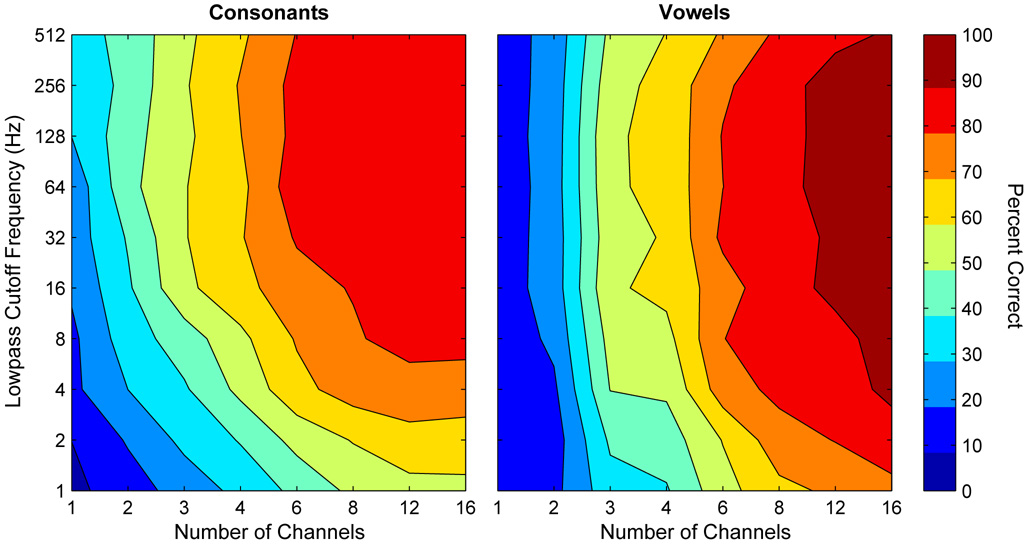
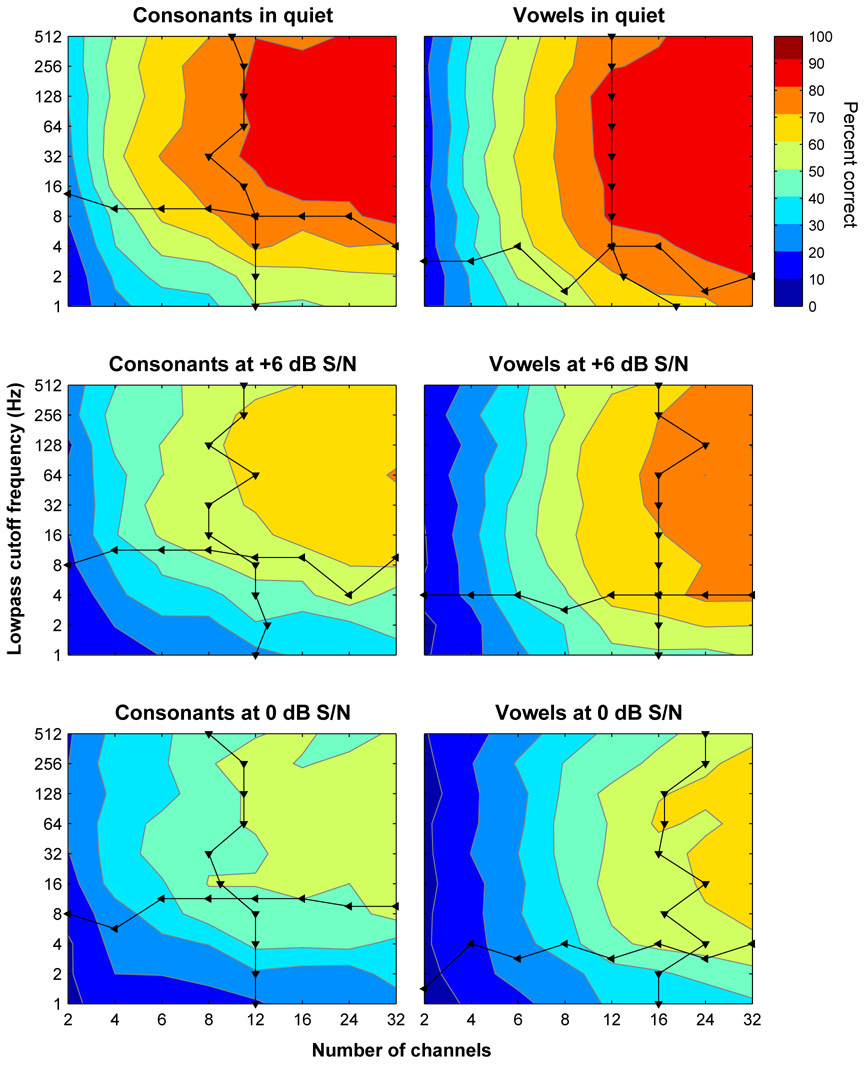
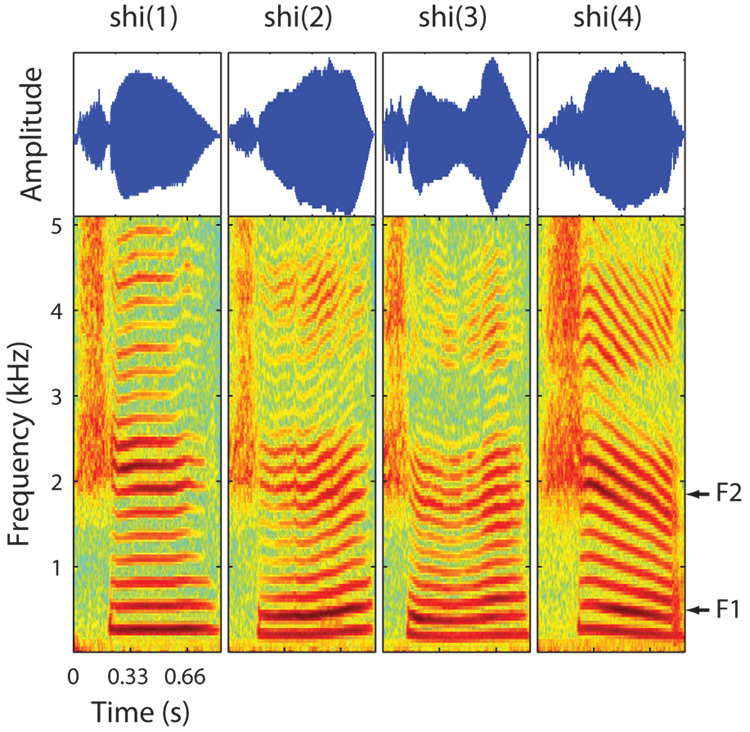
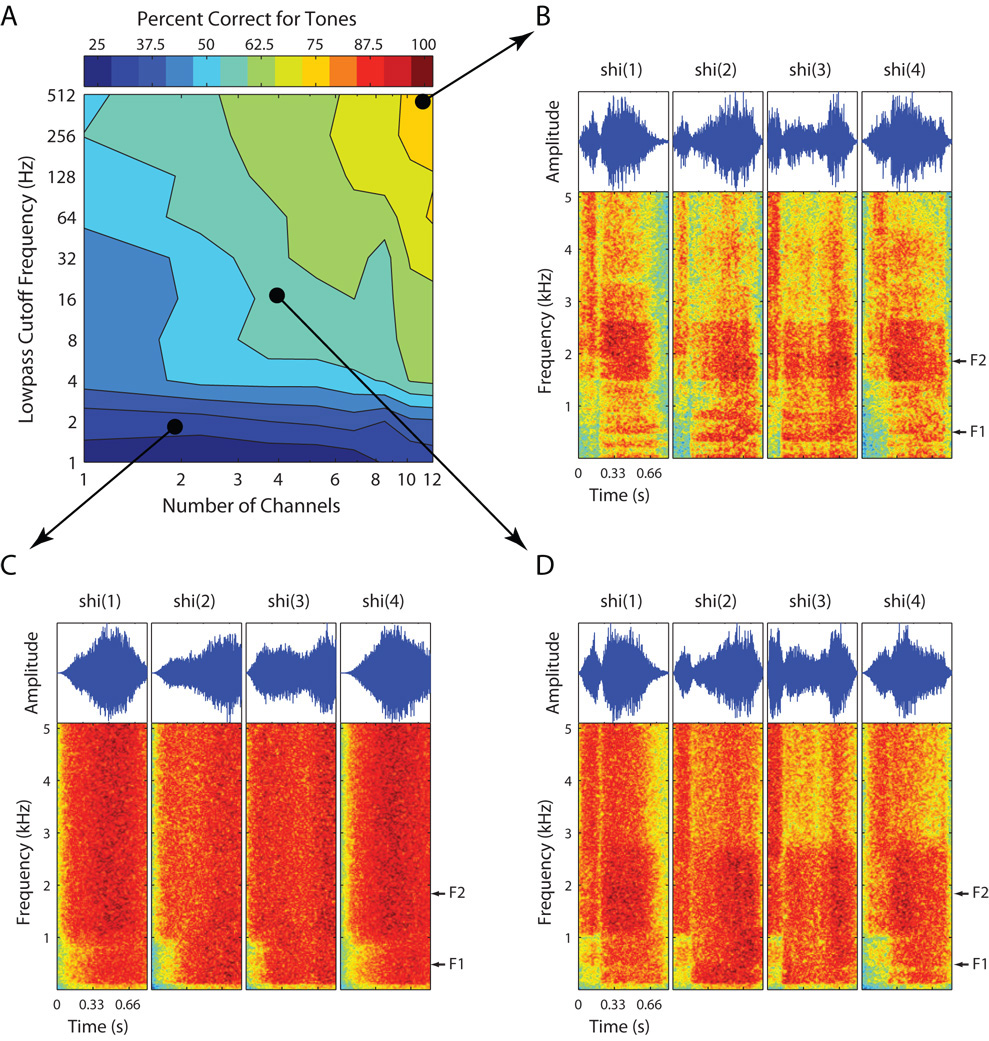
Features of stimulation important for speech recognition in people with normal hearing and in people using implanted auditory prostheses include spectral information represented by place of stimulation along the tonotopic axis and temporal information represented in low-frequency envelopes of the signal. The relative contributions of these features to speech recognition and their interactions have been studied using vocoder-like simulations of cochlear implant speech processors presented to listeners with normal hearing. In these studies, spectral/place information was manipulated by varying the number of channels and the temporal-envelope information was manipulated by varying the lowpass cutoffs of the envelope extractors. Consonant and vowel recognition in quiet reached plateau at 8 and 12 channels and lowpass cutoff frequencies of 16 Hz and 4 Hz, respectively. Phoneme (especially vowel) recognition in noise required larger numbers of channels. Lexical tone recognition required larger numbers of channels and higher lowpass cutoff frequencies. There was a tradeoff between spectral/place and temporal-envelope requirements. Most current auditory prostheses seem to deliver adequate temporal-envelope information, but the number of effective channels is suboptimal, particularly for speech recognition in noise, lexical tone recognition, and music perception.
Figures
References
-
- Baer T, Moore BCJ. Effects of spectral smearing on the intelligibility of sentences in noise. J. Acoust. Soc. Am. 1993;94:1229–1241. - PubMed
-
- Baer T, Moore BCJ. Effects of spectral smearing on the intelligibility of sentences in the presence of interfering speech. J. Acoust. Soc. Am. 1994;95:2277–2280. - PubMed
-
- Baskent D. Speech recognition in normal hearing and sensorineural hearing loss as a function of the number of spectral channels. J. Acoust. Soc. Am. 2006;120:2908–2925. - PubMed
-
- Boersma P, Weenink D. Praat: Doing phonetics by computer (Version 4.6.09) 2007. Retrieved July 10, 2007, from http://www.praat.org/
-
- Boothroyd A, Mulhearn B, Gong J, Ostroff J. Effects of spectral smearing on phoneme and word recognition. J. Acoust. Soc. Am. 1996;100:1807–1818. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
