

Protein function assignment through mining cross-species protein-protein interactions
- PMID: 18253506
- PMCID: PMC2216687
- DOI: 10.1371/journal.pone.0001562
Protein function assignment through mining cross-species protein-protein interactions
Abstract
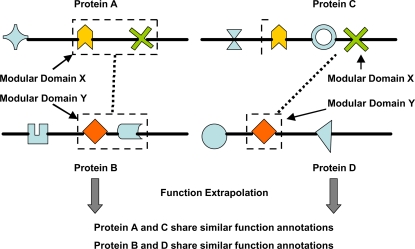
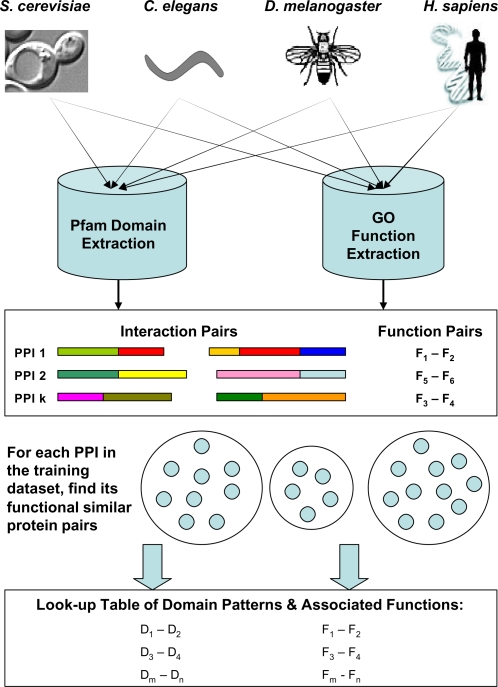
Background: As we move into the post genome-sequencing era, an immediate challenge is how to make best use of the large amount of high-throughput experimental data to assign functions to currently uncharacterized proteins. We here describe CSIDOP, a new method for protein function assignment based on shared interacting domain patterns extracted from cross-species protein-protein interaction data.
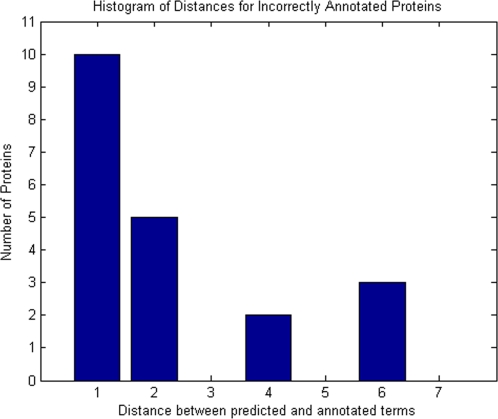
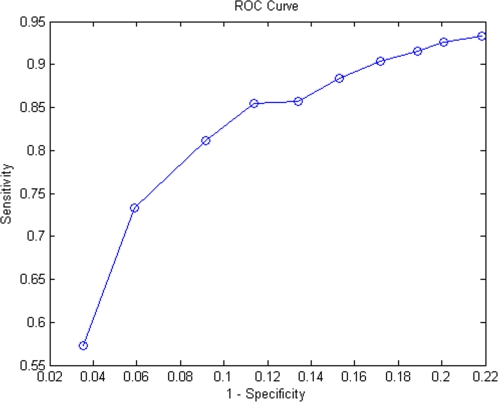
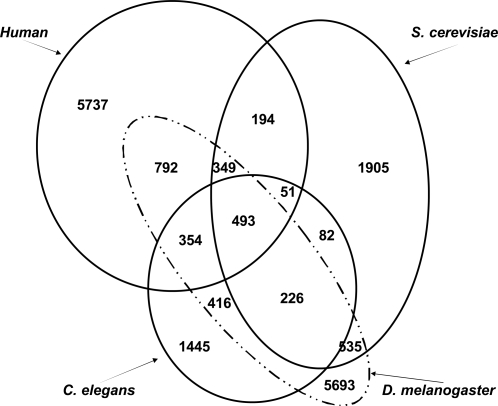
Methodology/principal findings: The proposed method is assessed both biologically and statistically over the genome of H. sapiens. The CSIDOP method is capable of making protein function prediction with accuracy of 95.42% using 2,972 gene ontology (GO) functional categories. In addition, we are able to assign novel functional annotations for 181 previously uncharacterized proteins in H. sapiens. Furthermore, we demonstrate that for proteins that are characterized by GO, the CSIDOP may predict extra functions. This is attractive as a protein normally executes a variety of functions in different processes and its current GO annotation may be incomplete.
Conclusions/significance: It can be shown through experimental results that the CSIDOP method is reliable and practical in use. The method will continue to improve as more high quality interaction data becomes available and is readily scalable to a genome-wide application.
Conflict of interest statement
Figures
References
-
- Galperin MY, Koonin EV. Who's your neighbor? New computational approaches for functional genomics. Nat Biotechnol. 2000;18:609–613. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
