

Shaping embodied neural networks for adaptive goal-directed behavior
- PMID: 18369432
- PMCID: PMC2265558
- DOI: 10.1371/journal.pcbi.1000042
Shaping embodied neural networks for adaptive goal-directed behavior
Abstract
The acts of learning and memory are thought to emerge from the modifications of synaptic connections between neurons, as guided by sensory feedback during behavior. However, much is unknown about how such synaptic processes can sculpt and are sculpted by neuronal population dynamics and an interaction with the environment. Here, we embodied a simulated network, inspired by dissociated cortical neuronal cultures, with an artificial animal (an animat) through a sensory-motor loop consisting of structured stimuli, detailed activity metrics incorporating spatial information, and an adaptive training algorithm that takes advantage of spike timing dependent plasticity. By using our design, we demonstrated that the network was capable of learning associations between multiple sensory inputs and motor outputs, and the animat was able to adapt to a new sensory mapping to restore its goal behavior: move toward and stay within a user-defined area. We further showed that successful learning required proper selections of stimuli to encode sensory inputs and a variety of training stimuli with adaptive selection contingent on the animat's behavior. We also found that an individual network had the flexibility to achieve different multi-task goals, and the same goal behavior could be exhibited with different sets of network synaptic strengths. While lacking the characteristic layered structure of in vivo cortical tissue, the biologically inspired simulated networks could tune their activity in behaviorally relevant manners, demonstrating that leaky integrate-and-fire neural networks have an innate ability to process information. This closed-loop hybrid system is a useful tool to study the network properties intermediating synaptic plasticity and behavioral adaptation. The training algorithm provides a stepping stone towards designing future control systems, whether with artificial neural networks or biological animats themselves.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures

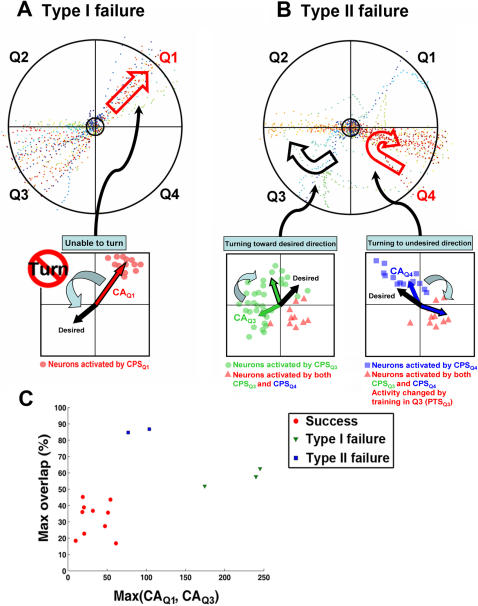
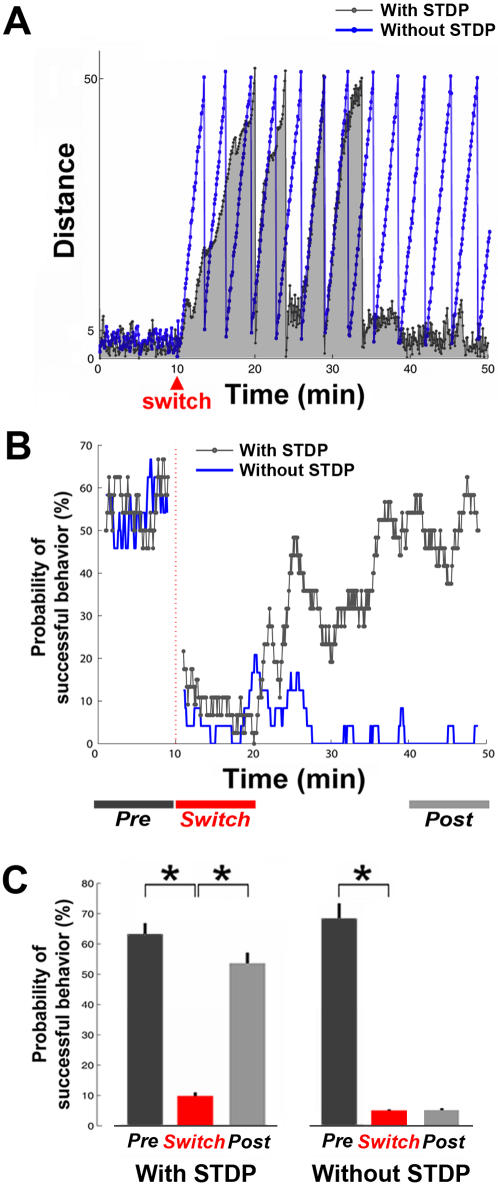
 for each CPS was created so that the average movement in each quadrant would be the desired movement with a magnitude of 1 unit (MQ1–MQ4).
for each CPS was created so that the average movement in each quadrant would be the desired movement with a magnitude of 1 unit (MQ1–MQ4).






References
-
- Potter SM, Fraser SE, Pine J. Animat in a petri dish: Cultured neural networks for studying neural computation. Proc 4th Joint Symposium on Neural Computation, UCSD. 1997:167–174.
-
- Potter SM, Wagenaar DA, DeMarse TB. Closing the loop: Stimulation feedback Systems for embodied MEA cultures. In: Taketani M, Baudry M, editors. Advances in network electrophysiology using multi-electrode arrays. New York: Springer; 2006. pp. 215–242.
-
- Meyer JA, Wilson SW. From Animals to animats: Proceedings of the First International Conference on Simulation of Adaptive Behavior. Cambridge: MIT Press; 1991.
-
- Shefi O, Golding I, Segev R, Ben-Jacob E, Ayali A. Morphological characterization of in vitro neuronal networks. Phys Rev E. 2002;66:021905. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
