

A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning
- PMID: 18477713
- PMCID: PMC2493394
- DOI: 10.1101/gr.076463.108
A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning
Abstract
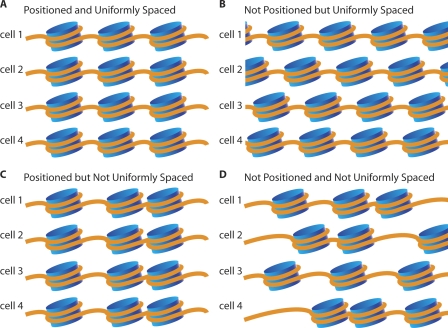
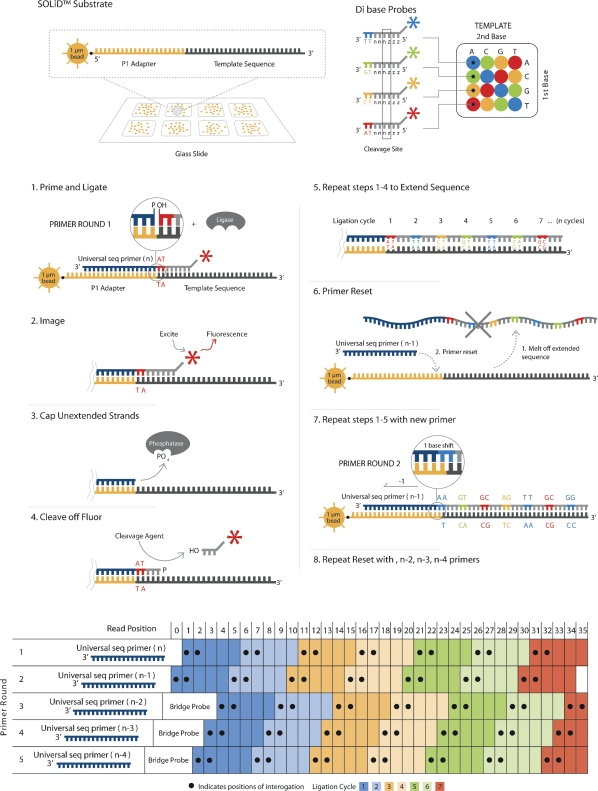
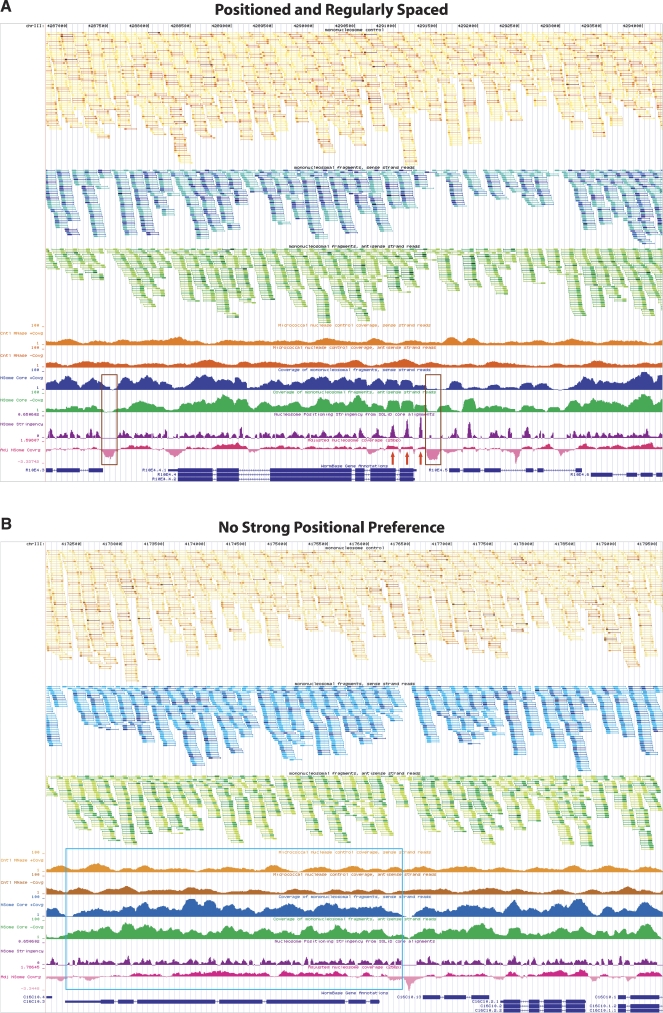
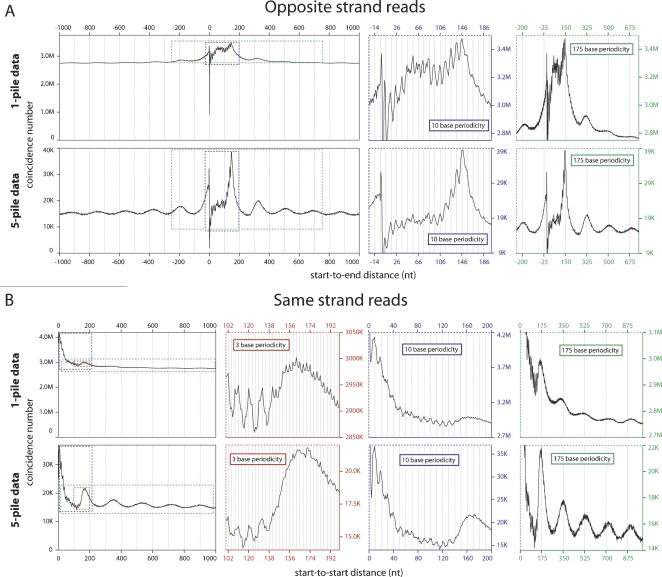
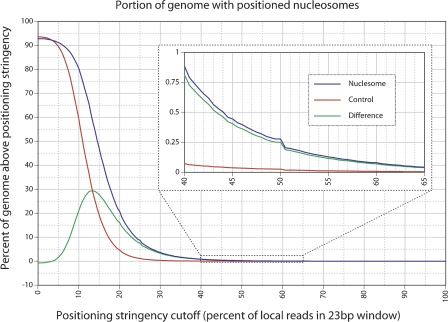
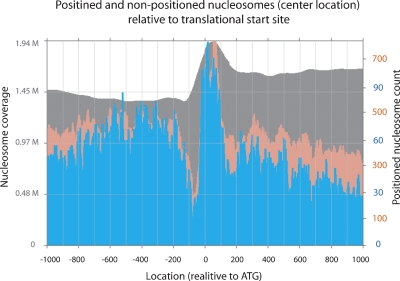
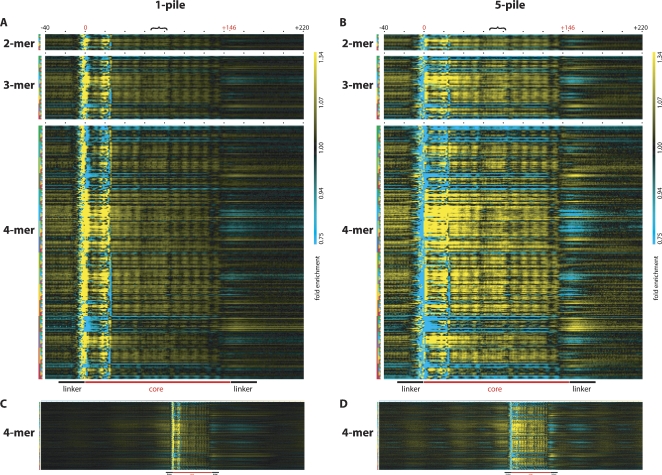
Using the massively parallel technique of sequencing by oligonucleotide ligation and detection (SOLiD; Applied Biosystems), we have assessed the in vivo positions of more than 44 million putative nucleosome cores in the multicellular genetic model organism Caenorhabditis elegans. These analyses provide a global view of the chromatin architecture of a multicellular animal at extremely high density and resolution. While we observe some degree of reproducible positioning throughout the genome in our mixed stage population of animals, we note that the major chromatin feature in the worm is a diversity of allowed nucleosome positions at the vast majority of individual loci. While absolute positioning of nucleosomes can vary substantially, relative positioning of nucleosomes (in a repeated array structure likely to be maintained at least in part by steric constraints) appears to be a significant property of chromatin structure. The high density of nucleosomal reads enabled a substantial extension of previous analysis describing the usage of individual oligonucleotide sequences along the span of the nucleosome core and linker. We release this data set, via the UCSC Genome Browser, as a resource for the high-resolution analysis of chromatin conformation and DNA accessibility at individual loci within the C. elegans genome.
Figures
References
-
- Albert I., Mavrich T.N., Tomsho L.P., Qi J., Zanton S.J., Schuster S.C., Pugh B.F. Translational and rotational settings of H2A.Z nucleosomes across the Saccharomyces cerevisiae genome. Nature. 2007;446:572–576. - PubMed
-
- Blumenthal T. Trans-splicing and polycistronic transcription in Caenohabditis elegans. Trends Genet. 1995;11:132–136. - PubMed
-
- Davey C.A., Sargent D.F., Luger K., Maeder A.W., Richmond T.J. Solvent mediated interactions in the structure of the nucleosome core particle at 1.9 Å resolution. J. Mol. Biol. 2002;319:1097–1113. - PubMed
-
- Dixon D.K., Jones D., Candido E.P. The differentially expressed 16-kD heat shock genes of Caenorhabditis elegans exhibit differential changes in chromatin structure during heat shock. DNA Cell Biol. 1990;9:177–191. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources