

PIE: an online prediction system for protein-protein interactions from text
- PMID: 18508809
- PMCID: PMC2447724
- DOI: 10.1093/nar/gkn281
PIE: an online prediction system for protein-protein interactions from text
Abstract
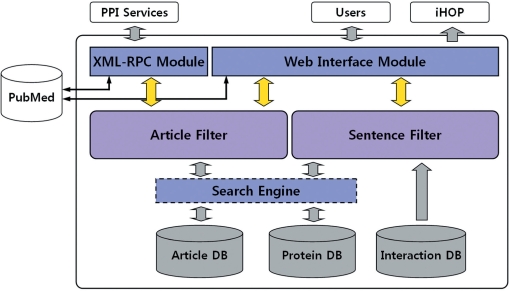
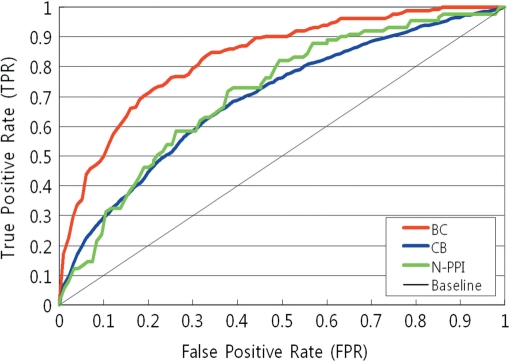
Protein-protein interaction (PPI) extraction has been an important research topic in bio-text mining area, since the PPI information is critical for understanding biological processes. However, there are very few open systems available on the Web and most of the systems focus on keyword searching based on predefined PPIs. PIE (Protein Interaction information Extraction system) is a configurable Web service to extract PPIs from literature, including user-provided papers as well as PubMed articles. After providing abstracts or papers, the prediction results are displayed in an easily readable form with essential, yet compact features. The PIE interface supports more features such as PDF file extraction, PubMed search tool and network communication, which are useful for biologists and bio-system developers. The PIE system utilizes natural language processing techniques and machine learning methodologies to predict PPI sentences, which results in high precision performance for Web users. PIE is freely available at http://bi.snu.ac.kr/pie/.
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
