

Genome information management and integrated data analysis with HaloLex
- PMID: 18592220
- PMCID: PMC2516542
- DOI: 10.1007/s00203-008-0389-z
Genome information management and integrated data analysis with HaloLex
Abstract
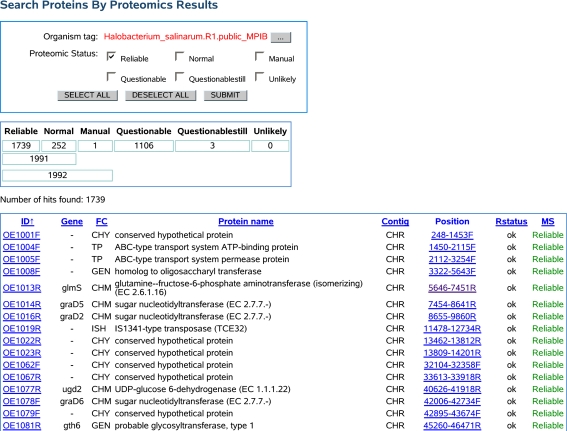
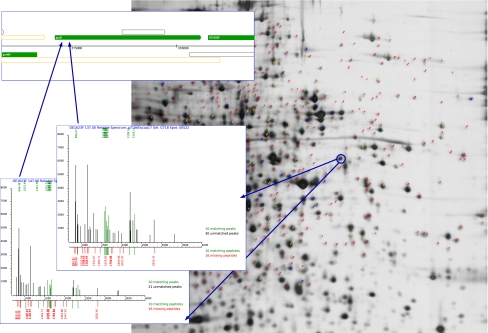
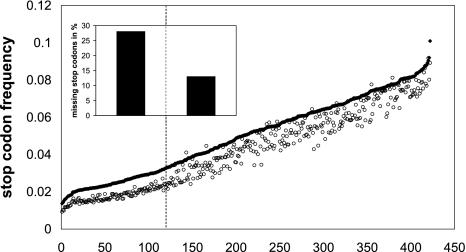
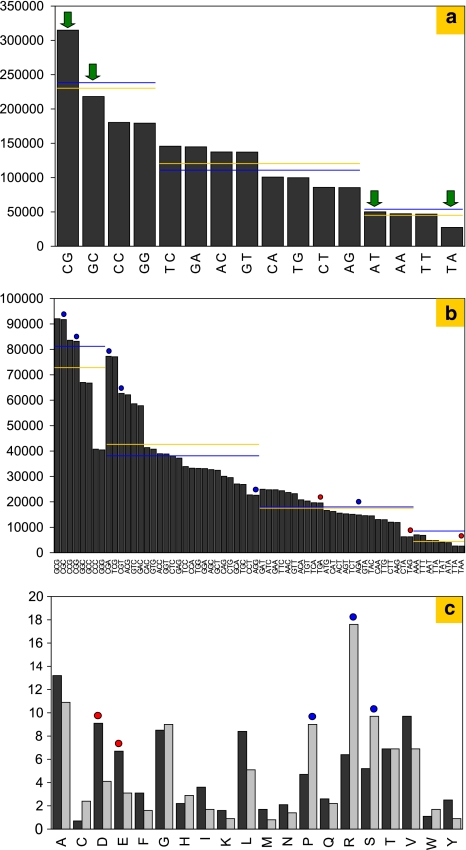
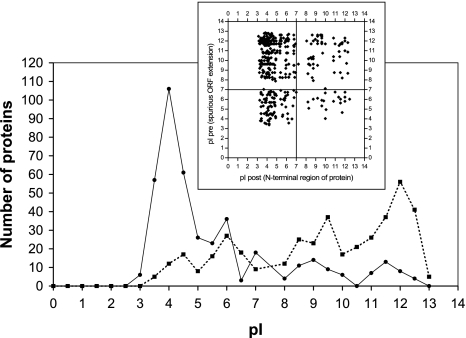
HaloLex is a software system for the central management, integration, curation, and web-based visualization of genomic and other -omics data for any given microorganism. The system has been employed for the manual curation of three haloarchaeal genomes, namely Halobacterium salinarum (strain R1), Natronomonas pharaonis, and Haloquadratum walsbyi. HaloLex, in particular, enables the integrated analysis of genome-wide proteomic results with the underlying genomic data. This has proven indispensable to generate reliable gene predictions for GC-rich genomes, which, due to their characteristically low abundance of stop codons, are known to be hard targets for standard gene finders, especially concerning start codon assignment. The proteomic identification of more than 600 N-terminal peptides has greatly increased the reliability of the start codon assignment for Halobacterium salinarum. Application of homology-based methods to the published genome of Haloarcula marismortui allowed to detect 47 previously unidentified genes (a problem that is particularly serious for short protein sequences) and to correct more than 300 start codon misassignments.
Figures


References
-
- Aivaliotis M, Gevaert K, Falb M, Tebbe A, Konstantinidis K, Bisle B, Klein C, Martens L, Staes A, Timmerman E, Van Damme J, Siedler F, Pfeiffer F, Vandekerckhove J, Oesterhelt D. Large-scale identification of N-terminal peptides in the halophilic archaea Halobacterium salinarum and Natronomonas pharaonis. J Proteome Res. 2007;6:2195–2204. doi: 10.1021/pr0700347. - DOI - PubMed
-
- Baliga NS, Bonneau R, Facciotti MT, Pan M, Glusman G, Deutsch EW, Shannon P, Chiu Y, Weng RS, Gan RR, Hung P, Date SV, Marcotte E, Hood L, Ng WV. Genome sequence of Haloarcula marismortui: a halophilic archaeon from the Dead Sea. Genome Res. 2004;14:2221–2234. doi: 10.1101/gr.2700304. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
