

In-depth investigation of the soybean seed-filling proteome and comparison with a parallel study of rapeseed
- PMID: 18599654
- PMCID: PMC2528123
- DOI: 10.1104/pp.108.119222
In-depth investigation of the soybean seed-filling proteome and comparison with a parallel study of rapeseed
Abstract
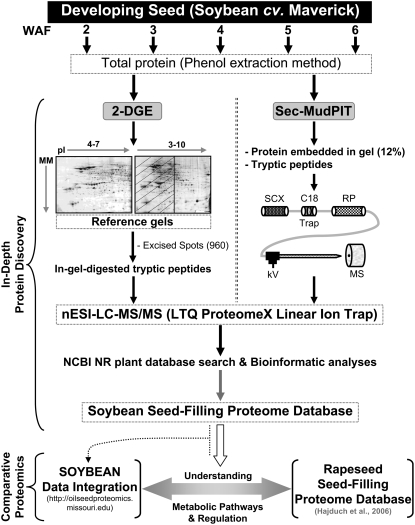
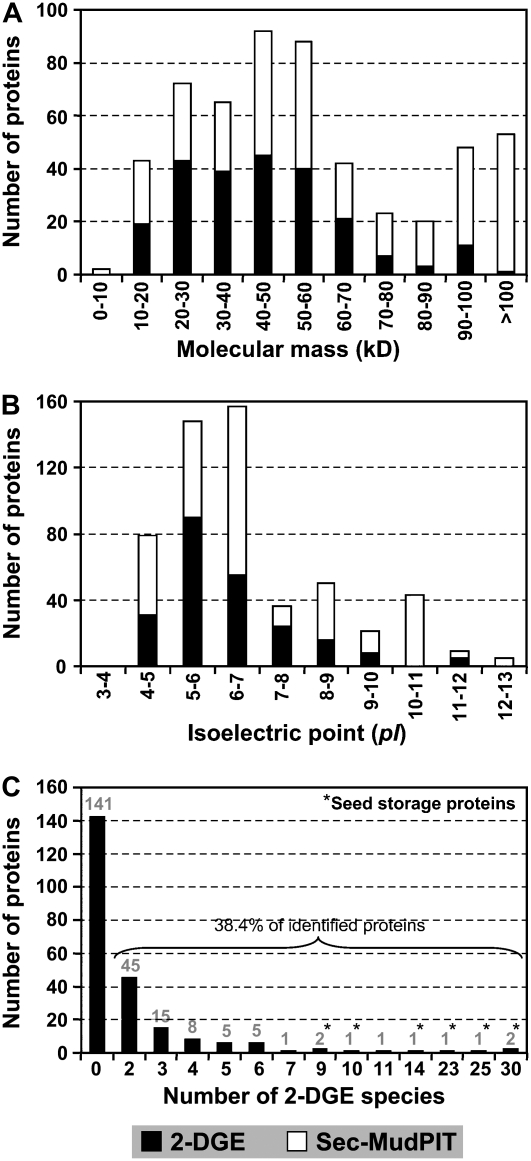
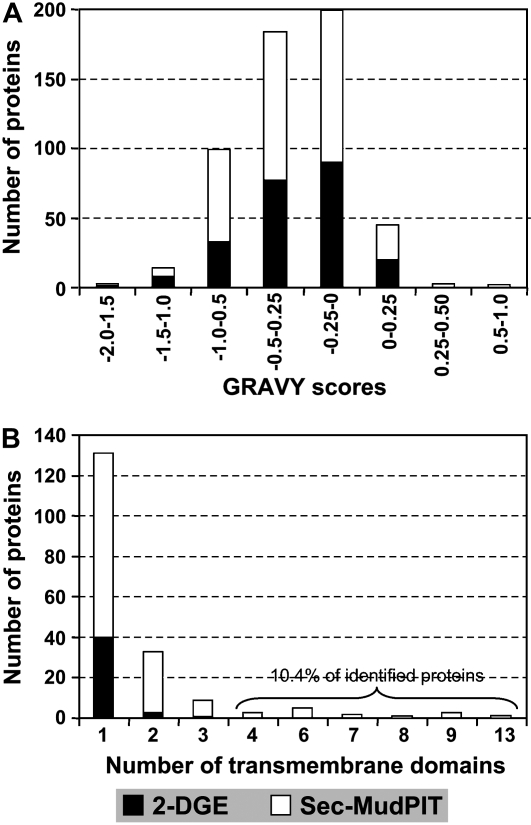
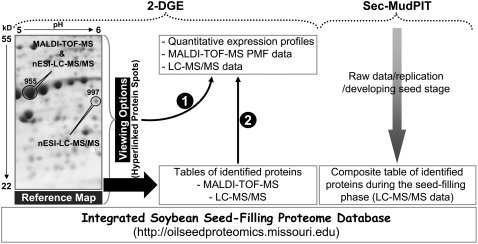
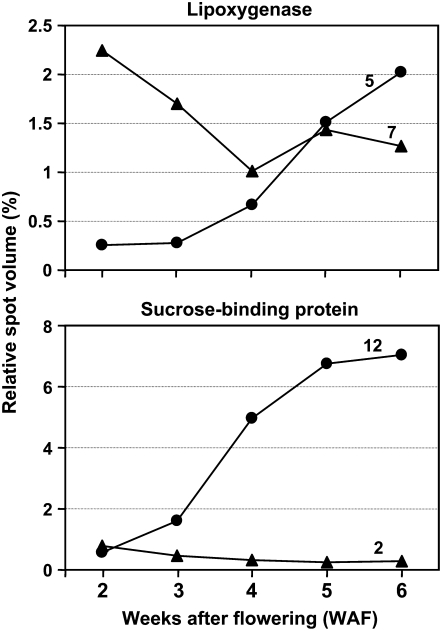
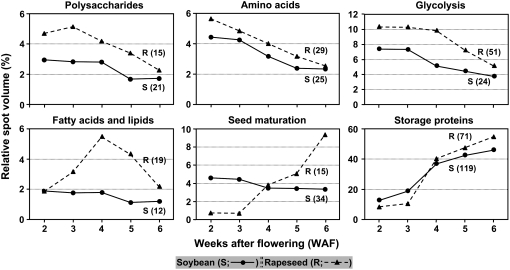
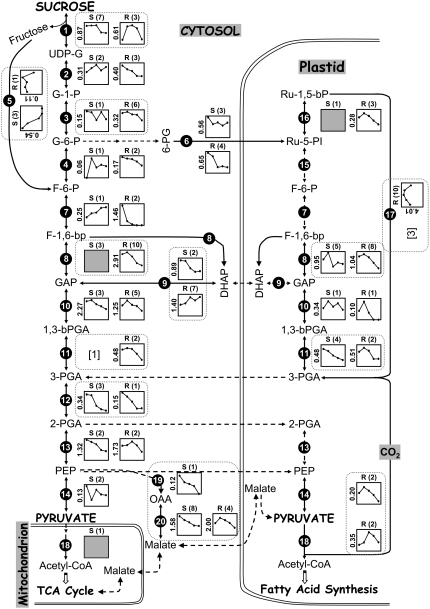
To better understand the metabolic processes of seed filling in soybean (Glycine max), two complementary proteomic approaches, two-dimensional gel electrophoresis (2-DGE) and semicontinuous multidimensional protein identification technology (Sec-MudPIT) coupled with liquid chromatography-mass spectrometry, were employed to analyze whole seed proteins at five developmental stages. 2-DGE and Sec-MudPIT analyses collectively identified 478 nonredundant proteins with only 70 proteins common to both datasets. 2-DGE data revealed that 38% of identified proteins were represented by multiple 2-DGE species. Identified proteins belonged to 13 (2-DGE) and 15 (Sec-MudPIT) functional classes. Proteins involved in metabolism, protein destination and storage, and energy were highly represented, collectively accounting for 61.1% (2-DGE) and 42.2% (Sec-MudPIT) of total identified proteins. Membrane proteins, based upon transmembrane predictions, were 3-fold more prominent in Sec-MudPIT than 2-DGE. Data were integrated into an existing soybean proteome database (www.oilseedproteomics.missouri.edu). The integrated quantitative soybean database was compared to a parallel study of rapeseed (Brassica napus) to further understand the regulation of intermediary metabolism in protein-rich versus oil-rich seeds. Comparative analyses revealed (1) up to 3-fold higher expression of fatty acid biosynthetic proteins during seed filling in rapeseed compared to soybean; and (2) approximately a 48% higher number of protein species and a net 80% higher protein abundance for carbon assimilatory and glycolytic pathways leading to fatty acid synthesis in rapeseed versus soybean. Increased expression of glycolytic and fatty acid biosynthetic proteins in rapeseed compared to soybean suggests that a possible mechanistic basis for higher oil in rapeseed involves the concerted commitment of hexoses to glycolysis and eventual de novo fatty acid synthesis pathways.
Figures
References
-
- Agrawal GK, Thelen JJ (2006) Large scale identification and quantification profiling of phosphoproteins expressed during seed filling in oilseed rape. Mol Cell Proteomics 5 2044–2059 - PubMed
-
- Agrawal GK, Yonekura M, Iwahashi Y, Iwahashi H, Rakwal R (2005) System, trends and perspectives of proteomics in dicot plants. Part I. Technologies in proteome establishment. J Chromatogr B Analyt Technol Biomed Life Sci 815 109–123 - PubMed
-
- Bannai H, Tamada Y, Maruyama O, Nakai K, Miyano S (2002) Extensive feature detection of N-terminal protein sorting signals. Bioinformatics 18 298–305 - PubMed
-
- Bevan M, Bancroft I, Bent E, Love K, Goodman H, Dean C, Bergkamp R, Dirkse W, Van Staveren M, Stiekema W, et al (1998) Analysis of 19 Mb of contiguous sequence from chromosome 4 of Arabidopsis thaliana. Nature 391 485–488 - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
