

A Semantic Web management model for integrative biomedical informatics
- PMID: 18698353
- PMCID: PMC2491554
- DOI: 10.1371/journal.pone.0002946
A Semantic Web management model for integrative biomedical informatics
Abstract
Background: Data, data everywhere. The diversity and magnitude of the data generated in the Life Sciences defies automated articulation among complementary efforts. The additional need in this field for managing property and access permissions compounds the difficulty very significantly. This is particularly the case when the integration involves multiple domains and disciplines, even more so when it includes clinical and high throughput molecular data.
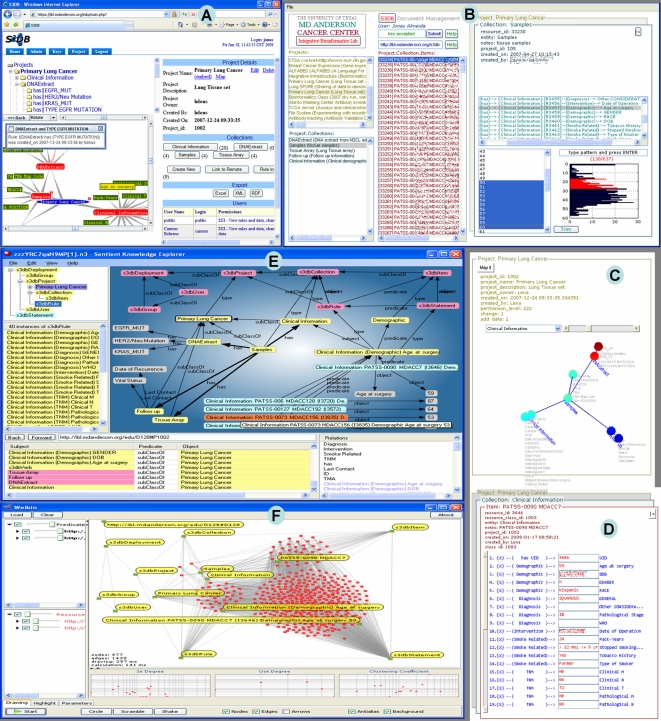
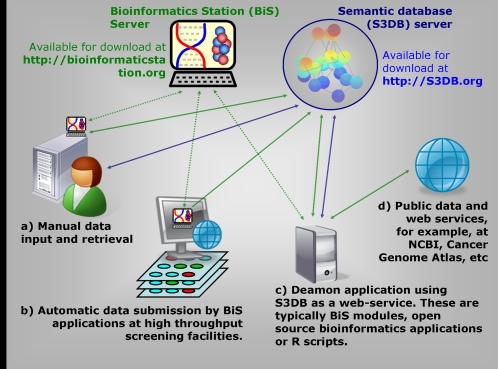
Methodology/principal findings: The emergence of Semantic Web technologies brings the promise of meaningful interoperation between data and analysis resources. In this report we identify a core model for biomedical Knowledge Engineering applications and demonstrate how this new technology can be used to weave a management model where multiple intertwined data structures can be hosted and managed by multiple authorities in a distributed management infrastructure. Specifically, the demonstration is performed by linking data sources associated with the Lung Cancer SPORE awarded to The University of Texas MD Anderson Cancer Center at Houston and the Southwestern Medical Center at Dallas. A software prototype, available with open source at www.s3db.org, was developed and its proposed design has been made publicly available as an open source instrument for shared, distributed data management.
Conclusions/significance: The Semantic Web technologies have the potential to addresses the need for distributed and evolvable representations that are critical for systems Biology and translational biomedical research. As this technology is incorporated into application development we can expect that both general purpose productivity software and domain specific software installed on our personal computers will become increasingly integrated with the relevant remote resources. In this scenario, the acquisition of a new dataset should automatically trigger the delegation of its analysis.
Conflict of interest statement
Figures
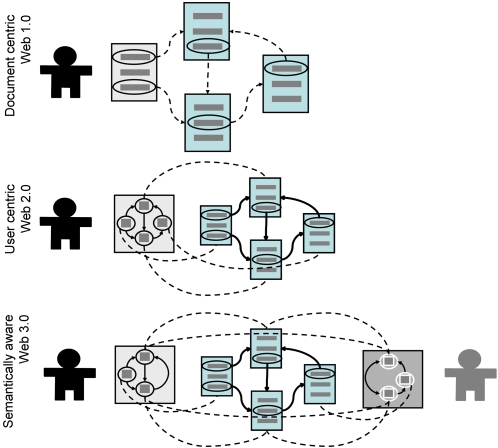
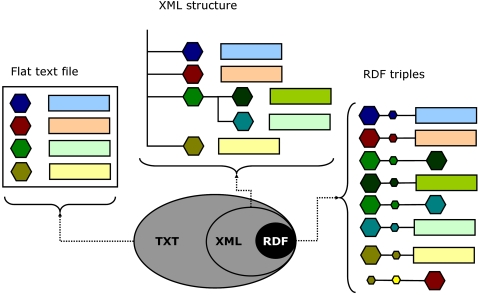
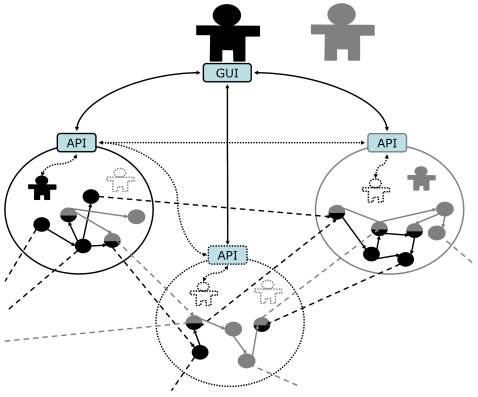
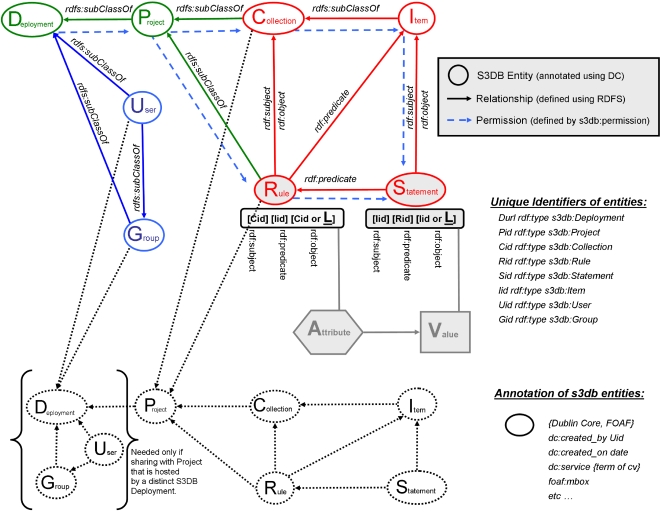
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
