

The C1C2: a framework for simultaneous model selection and assessment
- PMID: 18761753
- PMCID: PMC2556350
- DOI: 10.1186/1471-2105-9-360
The C1C2: a framework for simultaneous model selection and assessment
Abstract
Background: There has been recent concern regarding the inability of predictive modeling approaches to generalize to new data. Some of the problems can be attributed to improper methods for model selection and assessment. Here, we have addressed this issue by introducing a novel and general framework, the C1C2, for simultaneous model selection and assessment. The framework relies on a partitioning of the data in order to separate model choice from model assessment in terms of used data. Since the number of conceivable models in general is vast, it was also of interest to investigate the employment of two automatic search methods, a genetic algorithm and a brute-force method, for model choice. As a demonstration, the C1C2 was applied to simulated and real-world datasets. A penalized linear model was assumed to reasonably approximate the true relation between the dependent and independent variables, thus reducing the model choice problem to a matter of variable selection and choice of penalizing parameter. We also studied the impact of assuming prior knowledge about the number of relevant variables on model choice and generalization error estimates. The results obtained with the C1C2 were compared to those obtained by employing repeated K-fold cross-validation for choosing and assessing a model.
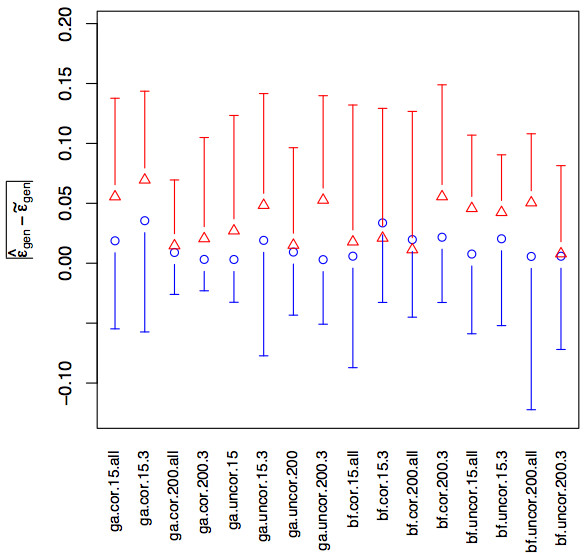
Results: The C1C2 framework performed well at finding the true model in terms of choosing the correct variable subset and producing reasonable choices for the penalizing parameter, even in situations when the independent variables were highly correlated and when the number of observations was less than the number of variables. The C1C2 framework was also found to give accurate estimates of the generalization error. Prior information about the number of important independent variables improved the variable subset choice but reduced the accuracy of generalization error estimates. Using the genetic algorithm worsened the model choice but not the generalization error estimates, compared to using the brute-force method. The results obtained with repeated K-fold cross-validation were similar to those produced by the C1C2 in terms of model choice, however a lower accuracy of the generalization error estimates was observed.
Conclusion: The C1C2 framework was demonstrated to work well for finding the true model within a penalized linear model class and accurately assess its generalization error, even for datasets with many highly correlated independent variables, a low observation-to-variable ratio, and model assumption deviations. A complete separation of the model choice and the model assessment in terms of data used for each task improves the estimates of the generalization error.
Figures

Similar articles
-
A general approach to simultaneous model fitting and variable elimination in response models for biological data with many more variables than observations.BMC Bioinformatics. 2008 Apr 15;9:195. doi: 10.1186/1471-2105-9-195. BMC Bioinformatics. 2008. PMID: 18410693 Free PMC article.
-
A fast algorithm for learning a ranking function from large-scale data sets.IEEE Trans Pattern Anal Mach Intell. 2008 Jul;30(7):1158-70. doi: 10.1109/TPAMI.2007.70776. IEEE Trans Pattern Anal Mach Intell. 2008. PMID: 18550900
-
Bias in error estimation when using cross-validation for model selection.BMC Bioinformatics. 2006 Feb 23;7:91. doi: 10.1186/1471-2105-7-91. BMC Bioinformatics. 2006. PMID: 16504092 Free PMC article.
-
Classification based upon gene expression data: bias and precision of error rates.Bioinformatics. 2007 Jun 1;23(11):1363-70. doi: 10.1093/bioinformatics/btm117. Epub 2007 Mar 28. Bioinformatics. 2007. PMID: 17392326 Review.
-
All that Glitters Is not Gold: Type-I Error Controlled Variable Selection from Clinical Trial Data.Clin Pharmacol Ther. 2024 Apr;115(4):774-785. doi: 10.1002/cpt.3211. Epub 2024 Feb 28. Clin Pharmacol Ther. 2024. PMID: 38419357 Review.
Cited by
-
Towards interoperable and reproducible QSAR analyses: Exchange of datasets.J Cheminform. 2010 Jun 30;2(1):5. doi: 10.1186/1758-2946-2-5. J Cheminform. 2010. PMID: 20591161 Free PMC article.
-
QSAR with experimental and predictive distributions: an information theoretic approach for assessing model quality.J Comput Aided Mol Des. 2013 Mar;27(3):203-19. doi: 10.1007/s10822-013-9639-5. Epub 2013 Mar 16. J Comput Aided Mol Des. 2013. PMID: 23504478 Free PMC article.
-
Reliable estimation of prediction errors for QSAR models under model uncertainty using double cross-validation.J Cheminform. 2014 Nov 26;6(1):47. doi: 10.1186/s13321-014-0047-1. eCollection 2014. J Cheminform. 2014. PMID: 25506400 Free PMC article.
-
RRegrs: an R package for computer-aided model selection with multiple regression models.J Cheminform. 2015 Sep 15;7:46. doi: 10.1186/s13321-015-0094-2. eCollection 2015. J Cheminform. 2015. PMID: 26379782 Free PMC article.
References
-
- Wikberg JES, Lapinsh M, Prusis P. Proteochemometrics: A tool for modelling the molecular interaction space. In: Kubinyi H, Müller G, editor. Chemogenomics in Drug Discovery - A Medicinal Chemistry Perspective. Weinheim , Wiley-VCH; 2004. pp. 289–309.
-
- Hansch C. A Quantitative Approach to Biochemical Structure-Activity Relationships. Accounts of Chemical Research. 1969;2:232–239. doi: 10.1021/ar50020a002. - DOI
-
- van't Veer LJ, Dai H, van de Vijver MJ, He YD, Hart AA, Mao M, Peterse HL, van der Kooy K, Marton MJ, Witteveen AT, Schreiber GJ, Kerkhoven RM, Roberts C, Linsley PS, Bernards R, Friend SH. Gene expression profiling predicts clinical outcome of breast cancer. Nature. 2002;415:530–536. doi: 10.1038/415530a. - DOI - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
