

A robust statistical method for case-control association testing with copy number variation
- PMID: 18776912
- PMCID: PMC2784596
- DOI: 10.1038/ng.206
A robust statistical method for case-control association testing with copy number variation
Abstract
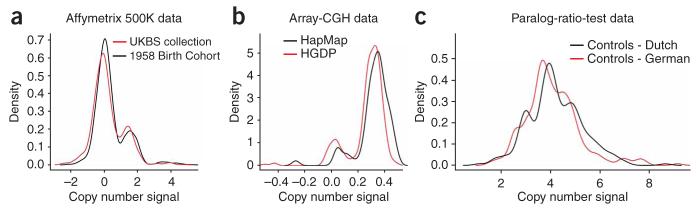
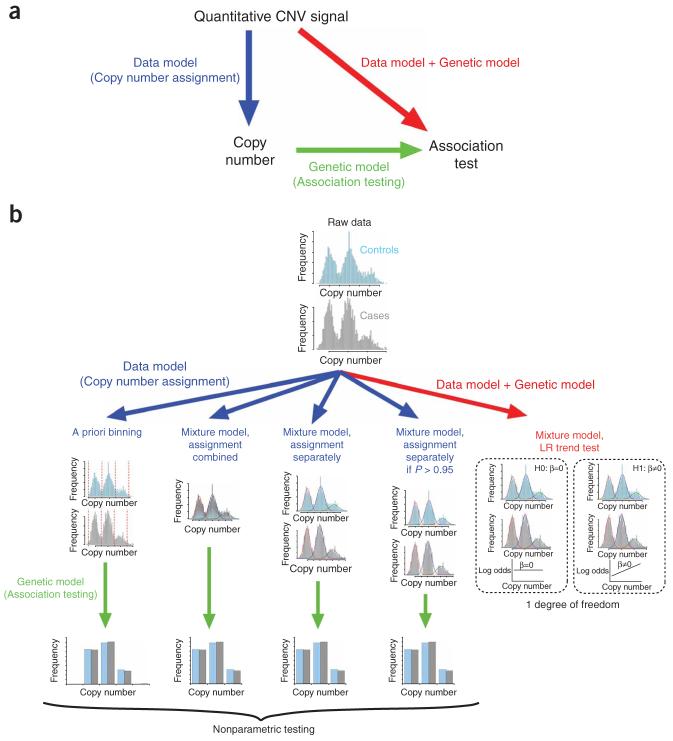
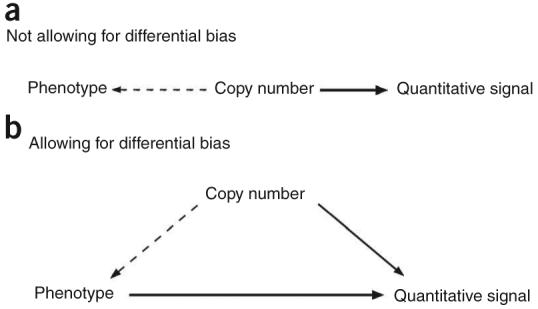
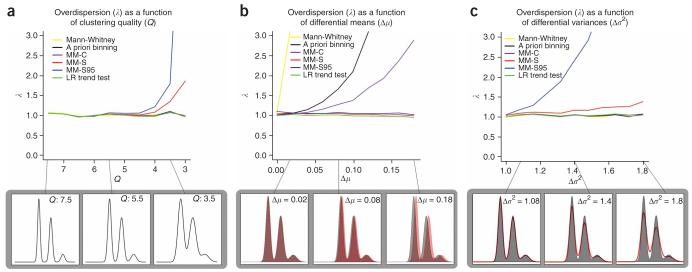
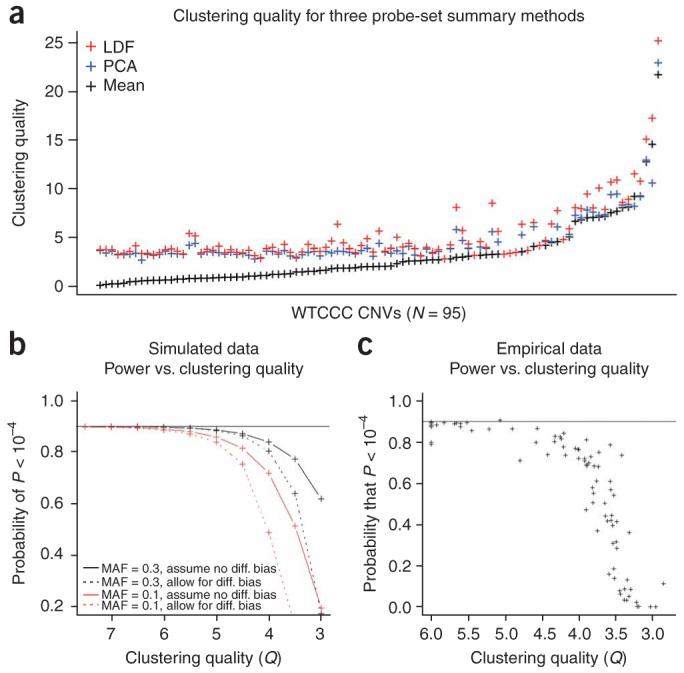
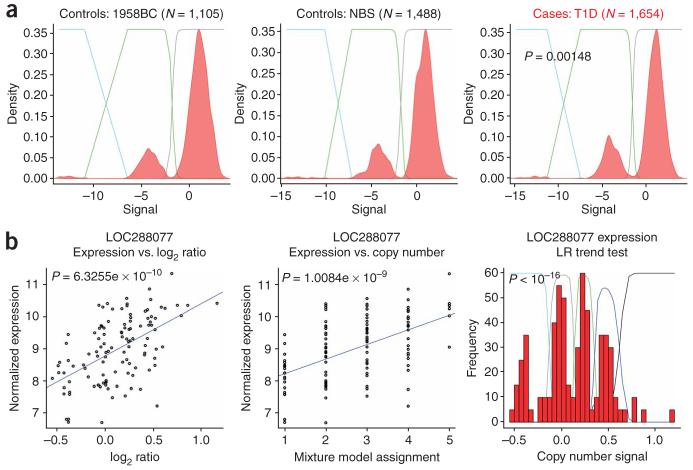
Copy number variation (CNV) is pervasive in the human genome and can play a causal role in genetic diseases. The functional impact of CNV cannot be fully captured through linkage disequilibrium with SNPs. These observations motivate the development of statistical methods for performing direct CNV association studies. We show through simulation that current tests for CNV association are prone to false-positive associations in the presence of differential errors between cases and controls, especially if quantitative CNV measurements are noisy. We present a statistical framework for performing case-control CNV association studies that applies likelihood ratio testing of quantitative CNV measurements in cases and controls. We show that our methods are robust to differential errors and noisy data and can achieve maximal theoretical power. We illustrate the power of these methods for testing for association with binary and quantitative traits, and have made this software available as the R package CNVtools.
Figures
References
-
- Tuzun E, et al. Fine-scale structural variation of the human genome. Nat. Genet. 2005;37:727–732. - PubMed
-
- Lupski JR, Stankiewicz P, editors. Genomic Disorders: The Genomic Basis of Disease. Humana Press; Totowa, New Jersey: 2006. - PubMed
-
- Flint J, et al. High frequencies of alpha-thalassaemia are the result of natural selection by malaria. Nature. 1986;321:744–750. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
