

Finding friends and enemies in an enemies-only network: a graph diffusion kernel for predicting novel genetic interactions and co-complex membership from yeast genetic interactions
- PMID: 18832443
- PMCID: PMC2593582
- DOI: 10.1101/gr.077693.108
Finding friends and enemies in an enemies-only network: a graph diffusion kernel for predicting novel genetic interactions and co-complex membership from yeast genetic interactions
Abstract
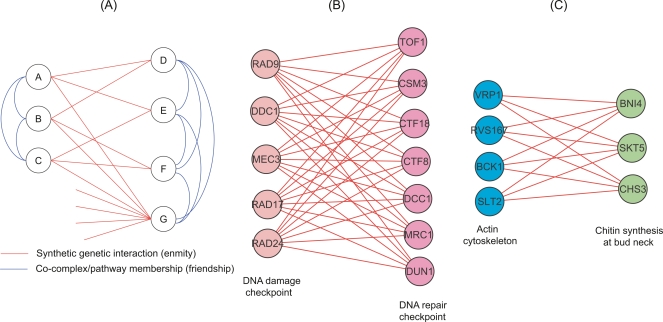
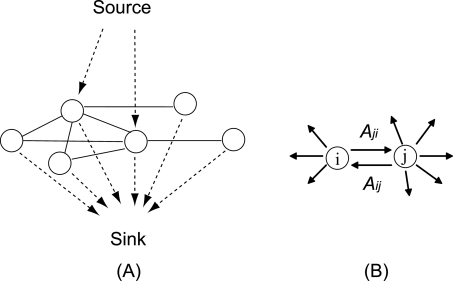
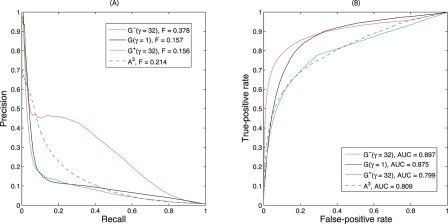
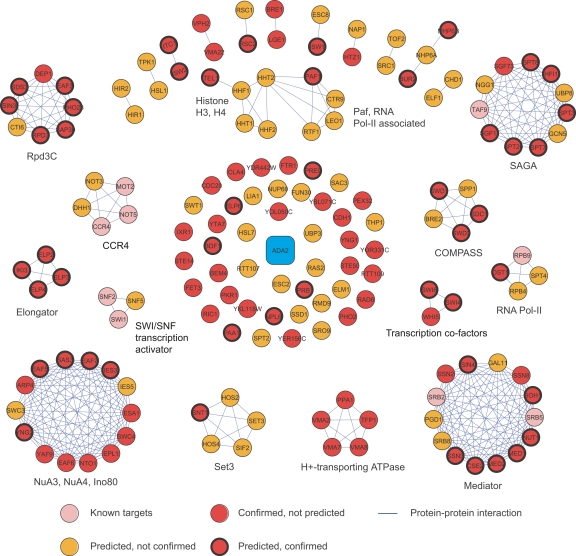
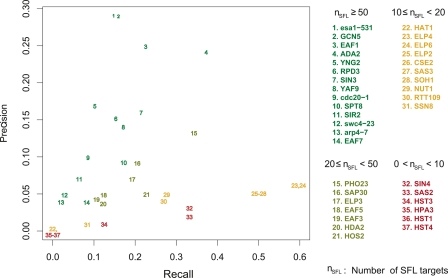
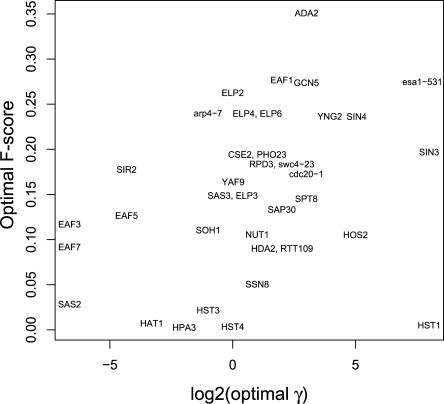
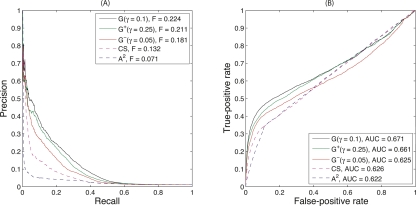
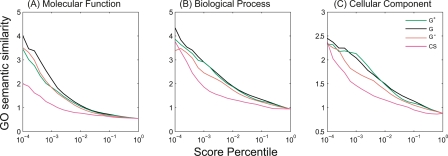
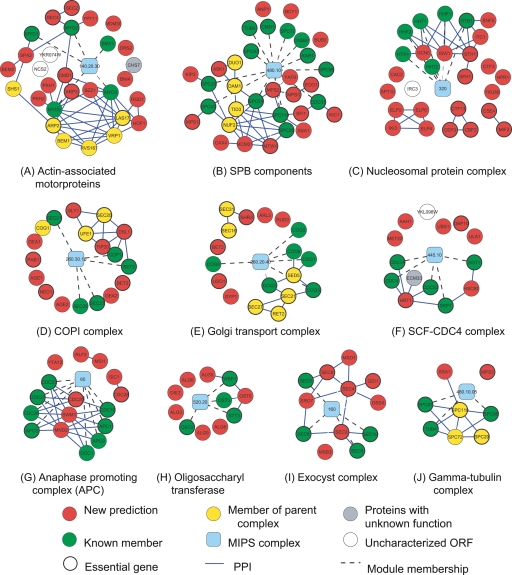
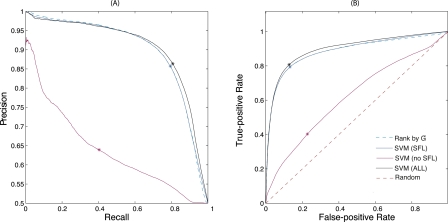
The yeast synthetic lethal genetic interaction network contains rich information about underlying pathways and protein complexes as well as new genetic interactions yet to be discovered. We have developed a graph diffusion kernel as a unified framework for inferring complex/pathway membership analogous to "friends" and genetic interactions analogous to "enemies" from the genetic interaction network. When applied to the Saccharomyces cerevisiae synthetic lethal genetic interaction network, we can achieve a precision around 50% with 20% to 50% recall in the genome-wide prediction of new genetic interactions, supported by experimental validation. The kernels show significant improvement over previous best methods for predicting genetic interactions and protein co-complex membership from genetic interaction data.
Figures
References
-
- Boser B.E., Guyon I.M., Vapnik V.N. COLT ’92: Proceedings of the Fifth Annual Workshop on Computational Learning Theory. ACM; New York: 1992. A training algorithm for optimal margin classifiers; pp. 144–152.
-
- Brin S., Page L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998;30:107–117.
-
- Chua H.N., Sung W.K., Wong L. Exploiting indirect neighbours and topological weight to predict protein function from protein–protein interactions. Bioinformatics. 2006;22:1623–1630. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases