

Evaluation of text-mining systems for biology: overview of the Second BioCreative community challenge
- PMID: 18834487
- PMCID: PMC2559980
- DOI: 10.1186/gb-2008-9-s2-s1
Evaluation of text-mining systems for biology: overview of the Second BioCreative community challenge
Abstract
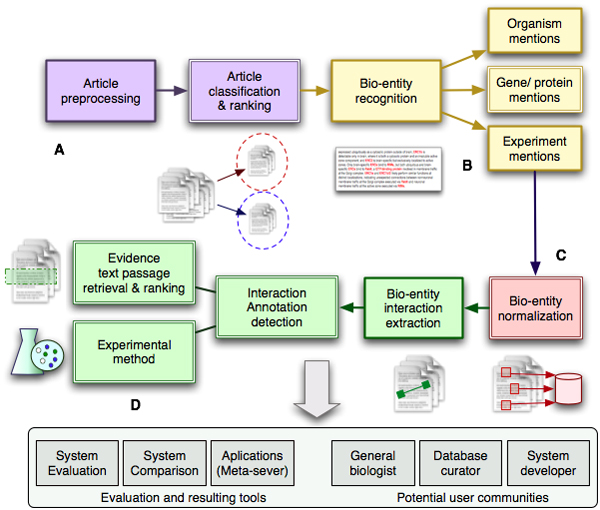
Background: Genome sciences have experienced an increasing demand for efficient text-processing tools that can extract biologically relevant information from the growing amount of published literature. In response, a range of text-mining and information-extraction tools have recently been developed specifically for the biological domain. Such tools are only useful if they are designed to meet real-life tasks and if their performance can be estimated and compared. The BioCreative challenge (Critical Assessment of Information Extraction in Biology) consists of a collaborative initiative to provide a common evaluation framework for monitoring and assessing the state-of-the-art of text-mining systems applied to biologically relevant problems.
Results: The Second BioCreative assessment (2006 to 2007) attracted 44 teams from 13 countries worldwide, with the aim of evaluating current information-extraction/text-mining technologies developed for one or more of the three tasks defined for this challenge evaluation. These tasks included the recognition of gene mentions in abstracts (gene mention task); the extraction of a list of unique identifiers for human genes mentioned in abstracts (gene normalization task); and finally the extraction of physical protein-protein interaction annotation-relevant information (protein-protein interaction task). The 'gold standard' data used for evaluating submissions for the third task was provided by the interaction databases MINT (Molecular Interaction Database) and IntAct.
Conclusion: The Second BioCreative assessment almost doubled the number of participants for each individual task when compared with the first BioCreative assessment. An overall improvement in terms of balanced precision and recall was observed for the best submissions for the gene mention (F score 0.87); for the gene normalization task, the best results were comparable (F score 0.81) compared with results obtained for similar tasks posed at the first BioCreative challenge. In case of the protein-protein interaction task, the importance and difficulties of experimentally confirmed annotation extraction from full-text articles were explored, yielding different results depending on the step of the annotation extraction workflow. A common characteristic observed in all three tasks was that the combination of system outputs could yield better results than any single system. Finally, the development of the first text-mining meta-server was promoted within the context of this community challenge.
Figures

References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
