

Hierarchically organized behavior and its neural foundations: a reinforcement learning perspective
- PMID: 18926527
- PMCID: PMC2783353
- DOI: 10.1016/j.cognition.2008.08.011
Hierarchically organized behavior and its neural foundations: a reinforcement learning perspective
Abstract
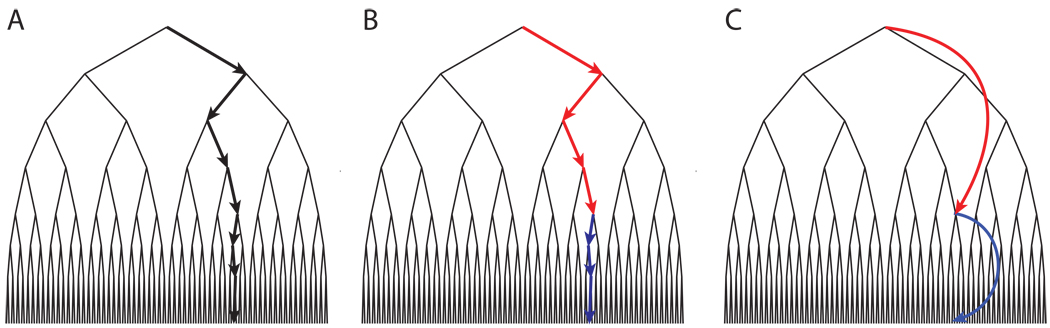
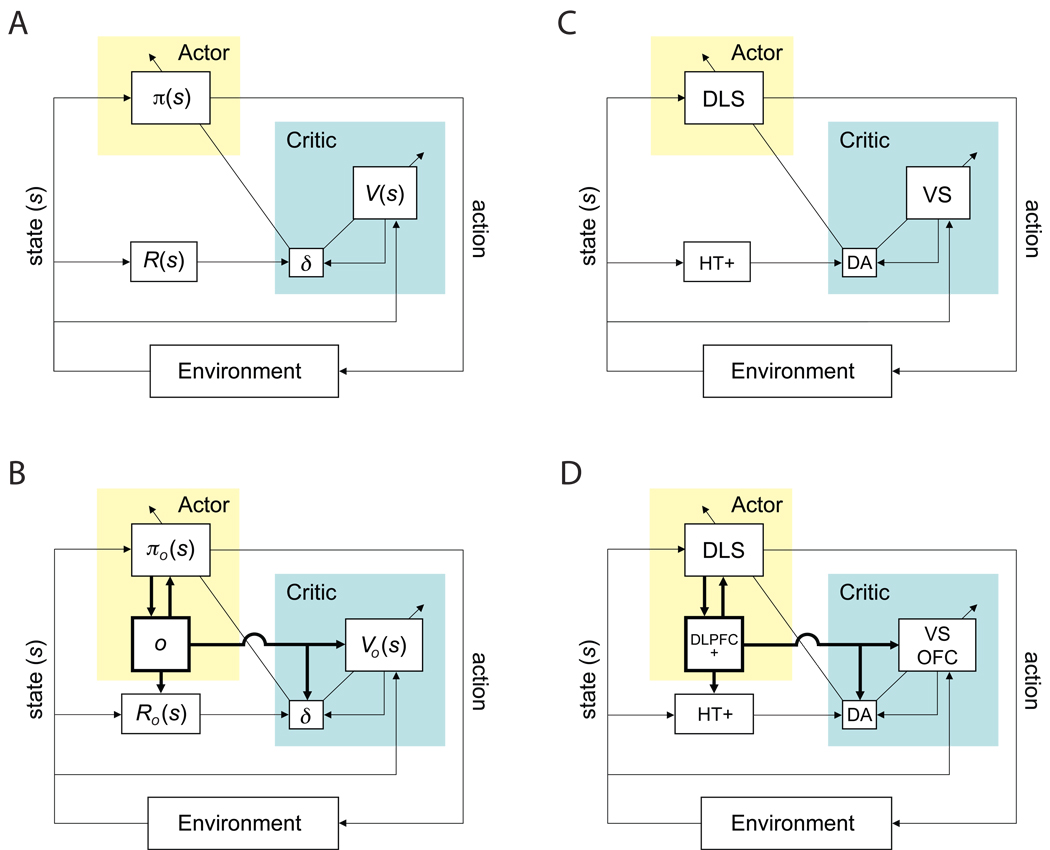
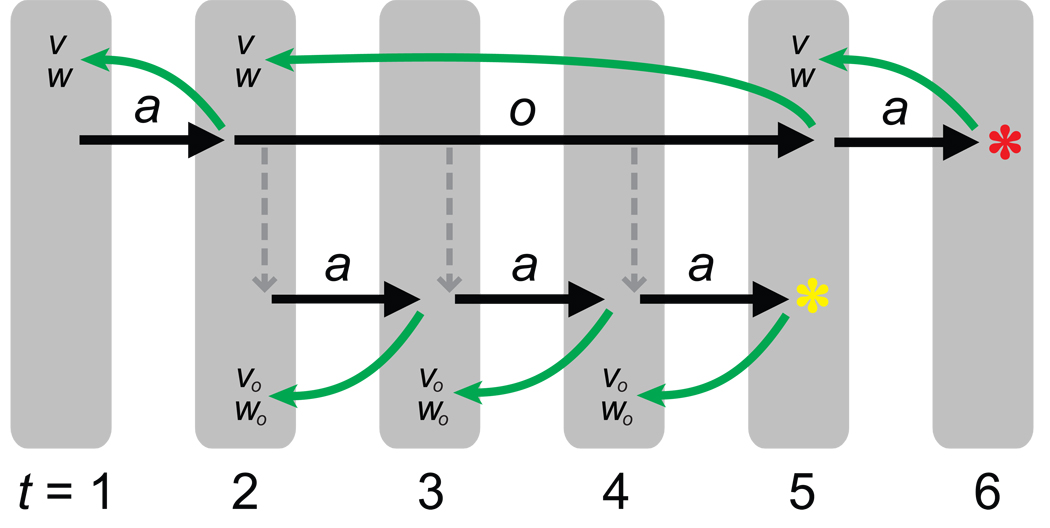
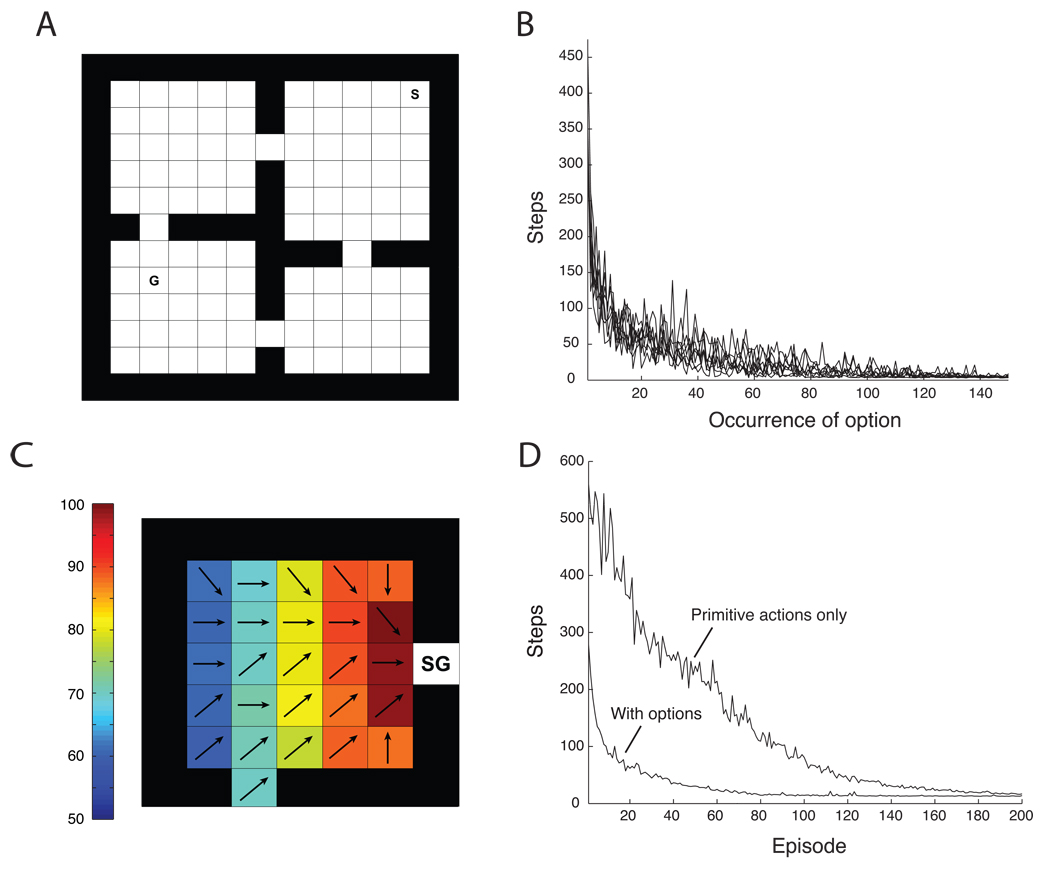
Research on human and animal behavior has long emphasized its hierarchical structure-the divisibility of ongoing behavior into discrete tasks, which are comprised of subtask sequences, which in turn are built of simple actions. The hierarchical structure of behavior has also been of enduring interest within neuroscience, where it has been widely considered to reflect prefrontal cortical functions. In this paper, we reexamine behavioral hierarchy and its neural substrates from the point of view of recent developments in computational reinforcement learning. Specifically, we consider a set of approaches known collectively as hierarchical reinforcement learning, which extend the reinforcement learning paradigm by allowing the learning agent to aggregate actions into reusable subroutines or skills. A close look at the components of hierarchical reinforcement learning suggests how they might map onto neural structures, in particular regions within the dorsolateral and orbital prefrontal cortex. It also suggests specific ways in which hierarchical reinforcement learning might provide a complement to existing psychological models of hierarchically structured behavior. A particularly important question that hierarchical reinforcement learning brings to the fore is that of how learning identifies new action routines that are likely to provide useful building blocks in solving a wide range of future problems. Here and at many other points, hierarchical reinforcement learning offers an appealing framework for investigating the computational and neural underpinnings of hierarchically structured behavior.
Figures
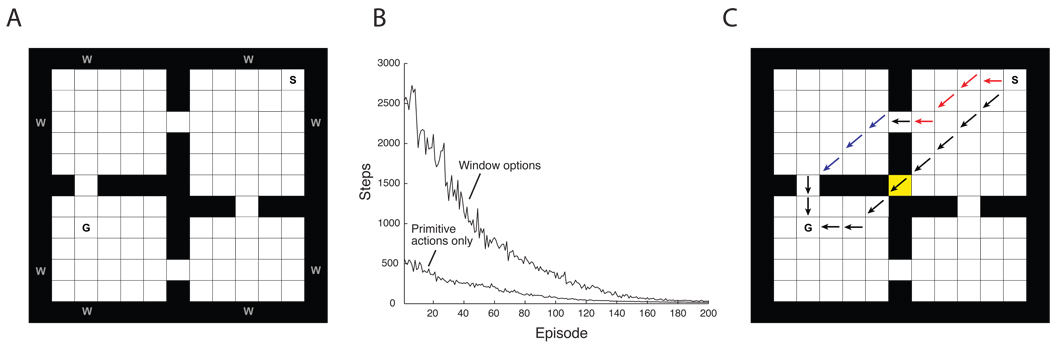
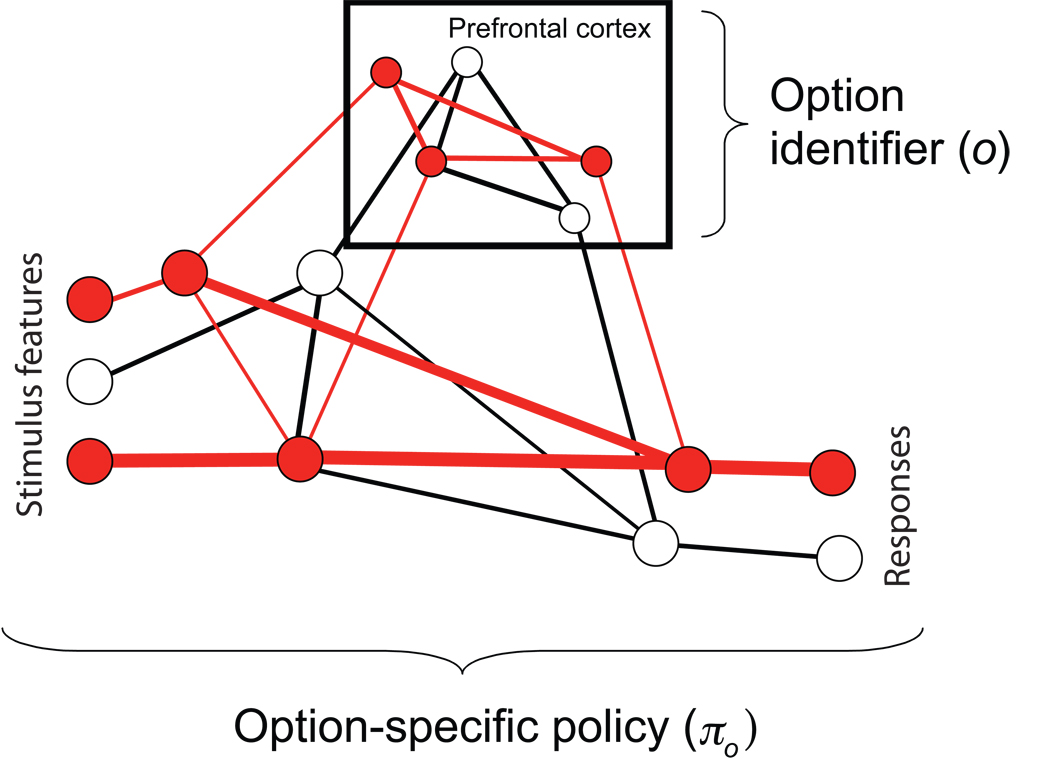
References
-
- Agre PE. The dynamic structure of everyday life (Tech. Rep. No. 1085) Cambridge, MA: Massachusetts Institute of Technology, Artificial Intelligence Laboratory; 1988.
-
- Aldridge JW, Berridge KC, Rosen AR. Basal ganglia neural mechanisms of natural movement sequences. Canadian Journal of Physiology and Pharmacology. 2004;82:732–739. - PubMed
-
- Alexander GE, Crutcher MD, DeLong MR. Basal ganglia-thalamocortical circuits: parallel substrates for motor, oculomotor, "prefrontal" and "limbic" functions. Progress in Brain Research. 1990;85:119–146. - PubMed
-
- Alexander GE, DeLong MR, Strick PL. Parallel organization of functionally segregated circuits linking basal ganglia and cortex. Annual Review of Neuroscience. 1986;9:357–381. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
