

Fast algorithms for computing sequence distances by exhaustive substring composition
- PMID: 18957094
- PMCID: PMC2615014
- DOI: 10.1186/1748-7188-3-13
Fast algorithms for computing sequence distances by exhaustive substring composition
Abstract
The increasing throughput of sequencing raises growing needs for methods of sequence analysis and comparison on a genomic scale, notably, in connection with phylogenetic tree reconstruction. Such needs are hardly fulfilled by the more traditional measures of sequence similarity and distance, like string edit and gene rearrangement, due to a mixture of epistemological and computational problems. Alternative measures, based on the subword composition of sequences, have emerged in recent years and proved to be both fast and effective in a variety of tested cases. The common denominator of such measures is an underlying information theoretic notion of relative compressibility. Their viability depends critically on computational cost. The present paper describes as a paradigm the extension and efficient implementation of one of the methods in this class. The method is based on the comparison of the frequencies of all subwords in the two input sequences, where frequencies are suitably adjusted to take into account the statistical background.
Figures
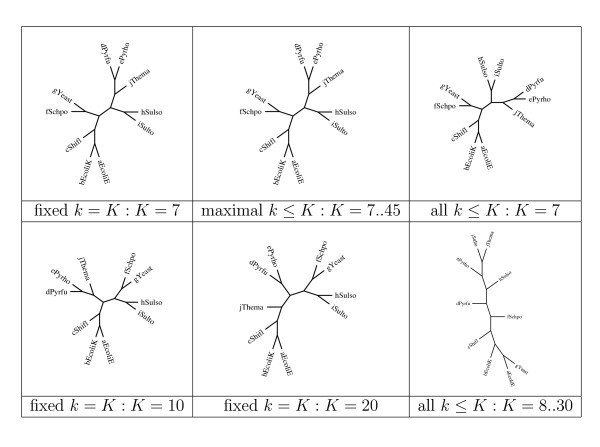
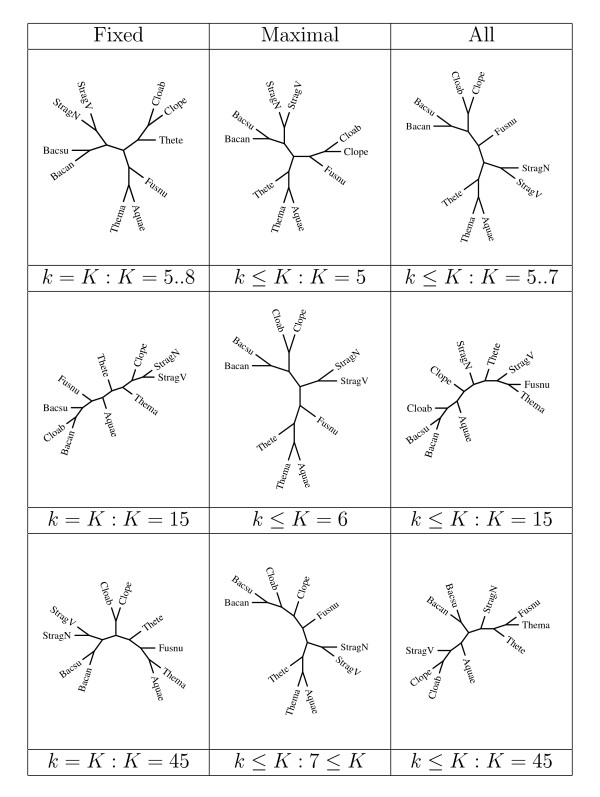
References
-
- von Mises R. Probability, Statistics and Truth MacMillan. 1939.
-
- Brillouin L. Science and Information Theory. Academic Press; 1971.
-
- Kolmogorov A. Three approaches to the quantitative definition of information. Problemi Pederachi Inf. 1965;1
-
- Lempel A, Ziv J. On the complexity of finite sequences. IEEE Transactions on Information Theory. 1976;22:75–81. doi: 10.1109/TIT.1976.1055501. - DOI
-
- Cover TM, Thomas JA. Elements of Information Theory. Wiley-Interscience; 1991.
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
