

Time-frequency masking for speech separation and its potential for hearing aid design
- PMID: 18974204
- PMCID: PMC4111459
- DOI: 10.1177/1084713808326455
Time-frequency masking for speech separation and its potential for hearing aid design
Abstract
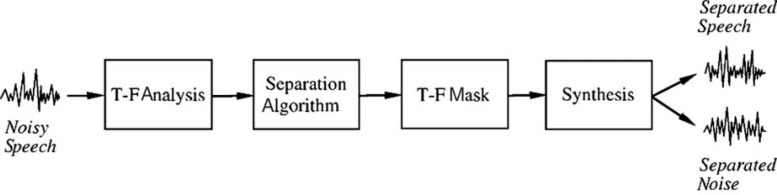
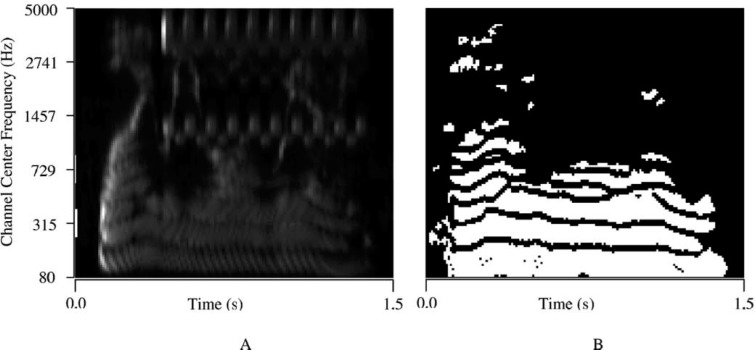
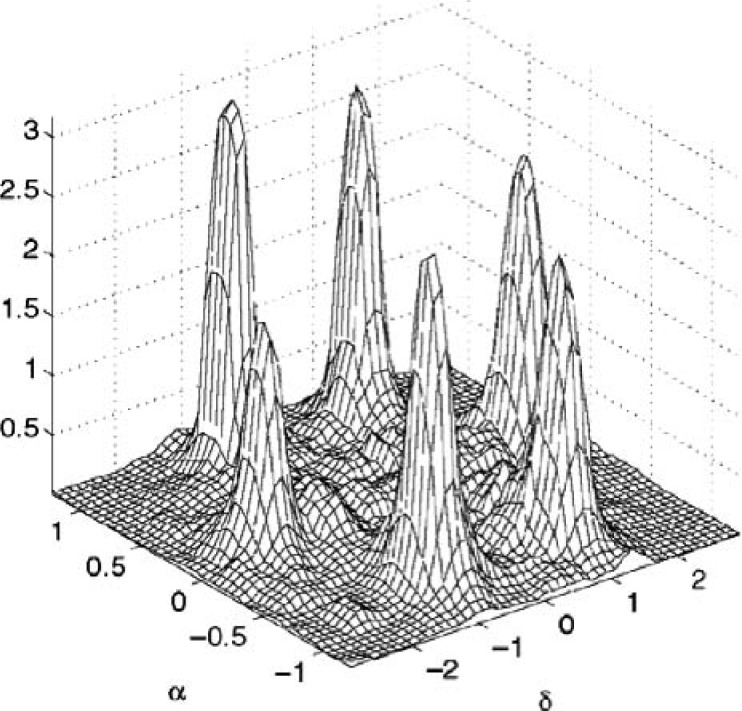
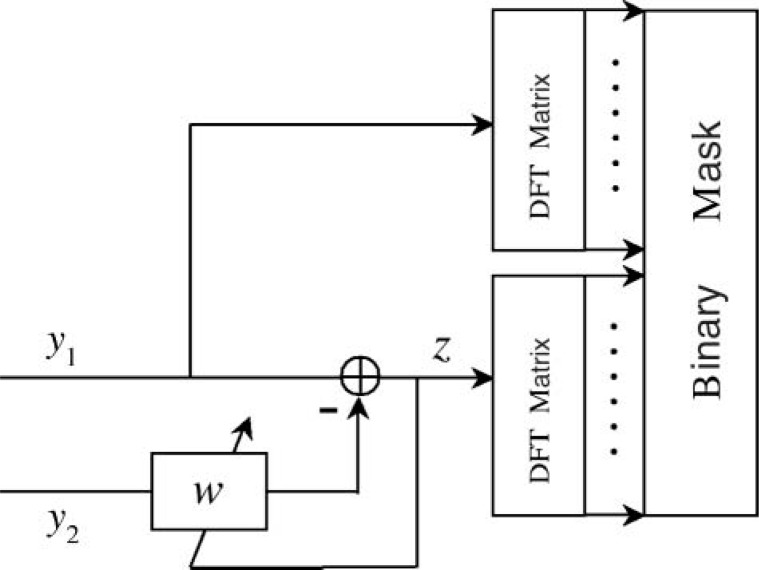
A new approach to the separation of speech from speech-in-noise mixtures is the use of time-frequency (T-F) masking. Originated in the field of computational auditory scene analysis, T-F masking performs separation in the time-frequency domain. This article introduces the T-F masking concept and reviews T-F masking algorithms that separate target speech from either monaural or binaural mixtures, as well as microphone-array recordings. The review emphasizes techniques that are promising for hearing aid design. This article also surveys recent studies that evaluate the perceptual effects of T-F masking techniques, particularly their effectiveness in improving human speech recognition in noise. An assessment is made of the potential benefits of T-F masking methods for the hearing impaired in light of the processing constraints of hearing aids. Finally, several issues pertinent to T-F masking are discussed.
Figures

Similar articles
-
Comparison of single-microphone noise reduction schemes: can hearing impaired listeners tell the difference?Int J Audiol. 2018 Jun;57(sup3):S55-S61. doi: 10.1080/14992027.2017.1279758. Epub 2017 Jan 23. Int J Audiol. 2018. PMID: 28112001
-
Speech quality evaluation of a sparse coding shrinkage noise reduction algorithm with normal hearing and hearing impaired listeners.Hear Res. 2015 Sep;327:175-85. doi: 10.1016/j.heares.2015.07.019. Epub 2015 Jul 29. Hear Res. 2015. PMID: 26232529
-
Effect of spectral change enhancement for the hearing impaired using parameter values selected with a genetic algorithm.J Acoust Soc Am. 2013 May;133(5):2910-20. doi: 10.1121/1.4799807. J Acoust Soc Am. 2013. PMID: 23654396
-
Pitch perception and auditory stream segregation: implications for hearing loss and cochlear implants.Trends Amplif. 2008 Dec;12(4):316-31. doi: 10.1177/1084713808325881. Epub 2008 Oct 30. Trends Amplif. 2008. PMID: 18974203 Free PMC article. Review.
-
Contrasting benefits from contralateral implants and hearing aids in cochlear implant users.Hear Res. 2012 Jun;288(1-2):100-13. doi: 10.1016/j.heares.2011.11.014. Epub 2011 Dec 30. Hear Res. 2012. PMID: 22226928 Review.
Cited by
-
Parameter tuning of time-frequency masking algorithms for reverberant artifact removal within the cochlear implant stimulus.Cochlear Implants Int. 2022 Nov;23(6):309-316. doi: 10.1080/14670100.2022.2096182. Epub 2022 Jul 23. Cochlear Implants Int. 2022. PMID: 35875863 Free PMC article.
-
Reconstruction techniques for improving the perceptual quality of binary masked speech.J Acoust Soc Am. 2014 Aug;136(2):892-902. doi: 10.1121/1.4884759. J Acoust Soc Am. 2014. PMID: 25096123 Free PMC article.
-
A Competing Voices Test for Hearing-Impaired Listeners Applied to Spatial Separation and Ideal Time-Frequency Masks.Trends Hear. 2019 Jan-Dec;23:2331216519848288. doi: 10.1177/2331216519848288. Trends Hear. 2019. PMID: 31104580 Free PMC article.
-
Hearing impairment, cognition and speech understanding: exploratory factor analyses of a comprehensive test battery for a group of hearing aid users, the n200 study.Int J Audiol. 2016 Nov;55(11):623-42. doi: 10.1080/14992027.2016.1219775. Epub 2016 Sep 2. Int J Audiol. 2016. PMID: 27589015 Free PMC article.
-
Harmonic Cancellation-A Fundamental of Auditory Scene Analysis.Trends Hear. 2021 Jan-Dec;25:23312165211041422. doi: 10.1177/23312165211041422. Trends Hear. 2021. PMID: 34698574 Free PMC article.
References
-
- Aarabi P., Shi G. (2004). Phase-based dual-microphone robust speech enhancement. IEEE Transactions on Systems, Man, and Cybernetics—Part B: Cybernetics, 34, 1763–1773 - PubMed
-
- Araki S., Makino S., Blin A., Mukai R., Sawada H. (2004, May). Underdetermined blind separation for speech in speech in real environments with sparseness and ICA. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal processing (Vol. III, pp. 881–884), Montreal, Quebec, Canada.
-
- Araki S., Makino S., Sawada H., Mukai R. (2004). Underdetermined blind separation of convolutive mixtures of speech with directivity pattern based mask and ICA. In Puntonet C. G., Prieto A. (Eds.), Lecture notes in computer science: 3195. Independent component analysis and blind signal separation: Proceedings of the Fifth International Congress, ICA 2004 (pp. 898–905). Berlin: Springer
-
- Araki S., Makino S., Sawada H., Mukai R. (2005, March). Reducing musical noise by a fine-shift overlap-and-add method applied to source separation using a time-frequency mask. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (Vol. III, pp. 81–84), Philadelphia, PA.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous