

How to make the most of NE dictionaries in statistical NER
- PMID: 19025691
- PMCID: PMC2586754
- DOI: 10.1186/1471-2105-9-S11-S5
How to make the most of NE dictionaries in statistical NER
Abstract
Background: When term ambiguity and variability are very high, dictionary-based Named Entity Recognition (NER) is not an ideal solution even though large-scale terminological resources are available. Many researches on statistical NER have tried to cope with these problems. However, it is not straightforward how to exploit existing and additional Named Entity (NE) dictionaries in statistical NER. Presumably, addition of NEs to an NE dictionary leads to better performance. However, in reality, the retraining of NER models is required to achieve this. We chose protein name recognition as a case study because it most suffers the problems related to heavy term variation and ambiguity.
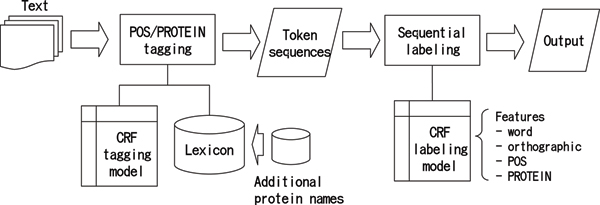
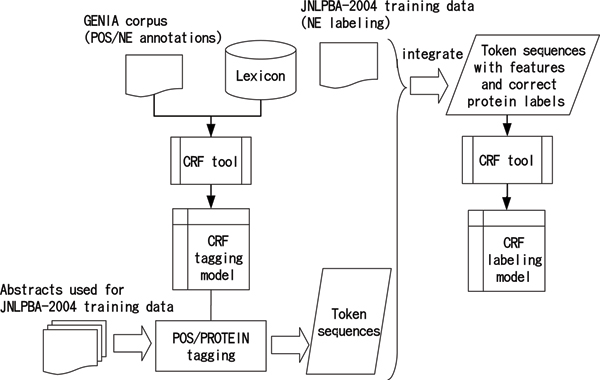
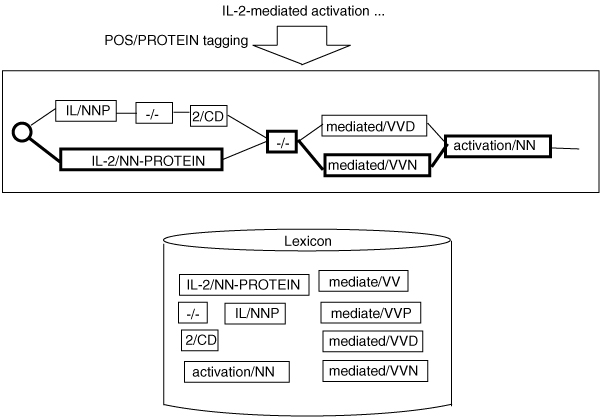
Methods: We have established a novel way to improve the NER performance by adding NEs to an NE dictionary without retraining. In our approach, first, known NEs are identified in parallel with Part-of-Speech (POS) tagging based on a general word dictionary and an NE dictionary. Then, statistical NER is trained on the POS/PROTEIN tagger outputs with correct NE labels attached.
Results: We evaluated performance of our NER on the standard JNLPBA-2004 data set. The F-score on the test set has been improved from 73.14 to 73.78 after adding protein names appearing in the training data to the POS tagger dictionary without any model retraining. The performance further increased to 78.72 after enriching the tagging dictionary with test set protein names.
Conclusion: Our approach has demonstrated high performance in protein name recognition, which indicates how to make the most of known NEs in statistical NER.
Figures
References
-
- Ananiadou S, McNaught J, (eds) Text Mining for Biology and Biomedicine. Artech House, London. 2006.
-
- Lafferty J, McCallum A, Pereira F. Conditional random fields: probabilistic models for segmenting and labelling sequence data. Proceedings of the Eighteenth International Conference on Machine Learning (ICML-2001) 2001. pp. 282–289.
-
- Baum LE, Petrie T. Statistical inference for probabilistic functions of finite state Markov chains. The Annals of Mathematical Statistics. 1966;37:1554–1563.
-
- McCallum A, Freitag D, Pereira F. Maximum entropy Markov models for information extraction and segmentation. Proceedings of the Seventeenth International Conference on Machine Learning. 2000. pp. 591–598.
-
- Kim J-D, Ohta T, Tsuruoka Y, Tateisi Y. Introduction to the Bio-Entity Recognition Task at JNLPBA. Proceeding of the Joint Workshop on Natural Language Processing in Biomedicine and its Applications (JNLPBA-2004) 2004. pp. 70–75.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
