

De novo fragment assembly with short mate-paired reads: Does the read length matter?
- PMID: 19056694
- PMCID: PMC2652199
- DOI: 10.1101/gr.079053.108
De novo fragment assembly with short mate-paired reads: Does the read length matter?
Abstract
Increasing read length is currently viewed as the crucial condition for fragment assembly with next-generation sequencing technologies. However, introducing mate-paired reads (separated by a gap of length, GapLength) opens a possibility to transform short mate-pairs into long mate-reads of length approximately GapLength, and thus raises the question as to whether the read length (as opposed to GapLength) even matters. We describe a new tool, EULER-USR, for assembling mate-paired short reads and use it to analyze the question of whether the read length matters. We further complement the ongoing experimental efforts to maximize read length by a new computational approach for increasing the effective read length. While the common practice is to trim the error-prone tails of the reads, we present an approach that substitutes trimming with error correction using repeat graphs. An important and counterintuitive implication of this result is that one may extend sequencing reactions that degrade with length "past their prime" to where the error rate grows above what is normally acceptable for fragment assembly.
Figures

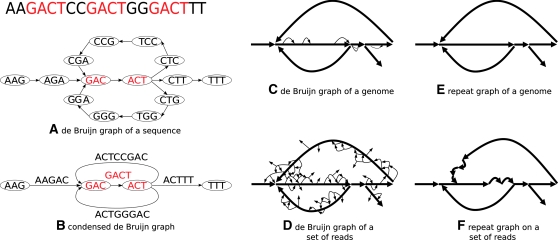
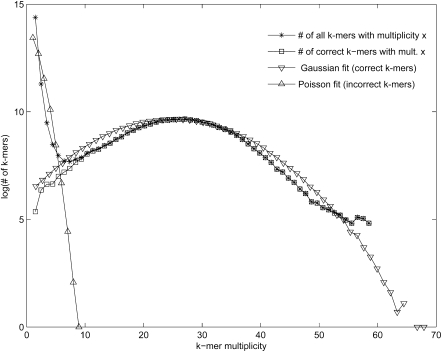
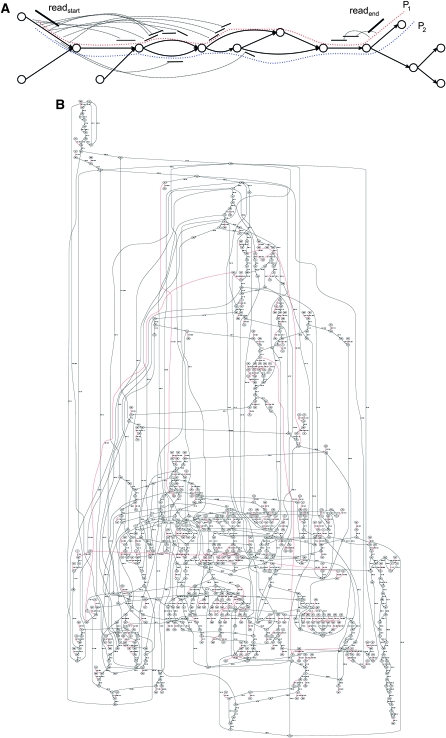




References
-
- Barski A., Cuddapah S., Cui K., Roh T.Y., Schones D.E., Wei G., Chepelev I., Zhao K. High-resolution profiling of histone methylations in the human genome. Cell. 2007;129:823–837. - PubMed
-
- Chaisson M.J., Tang H., Pevzner P.A. Fragment assembly with short reads. Bioinformatics. 2004;20:2067–2074. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous