

LRRCE: a leucine-rich repeat cysteine capping motif unique to the chordate lineage
- PMID: 19077264
- PMCID: PMC2637281
- DOI: 10.1186/1471-2164-9-599
LRRCE: a leucine-rich repeat cysteine capping motif unique to the chordate lineage
Abstract
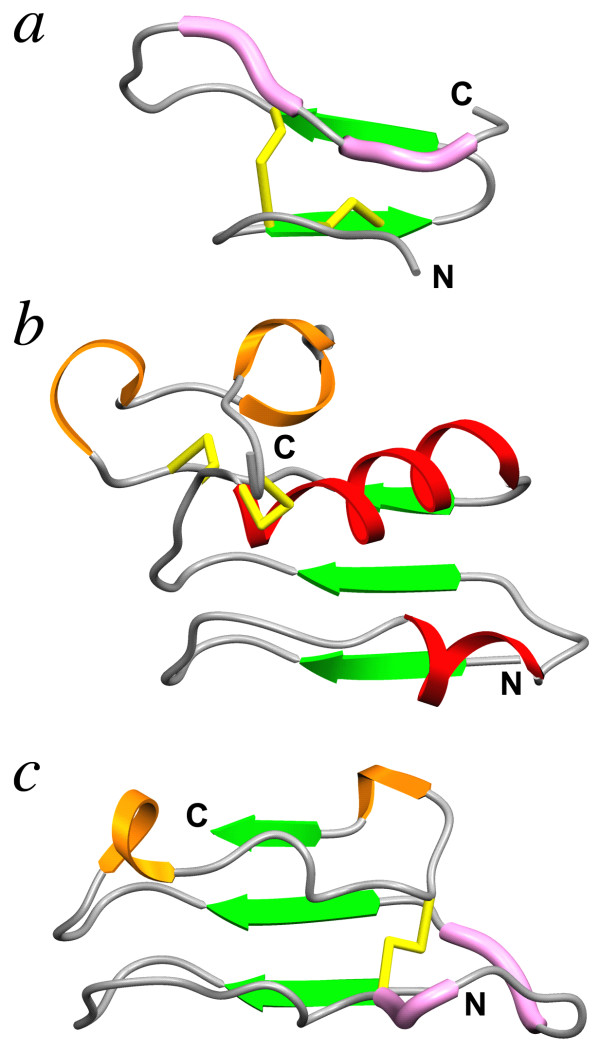
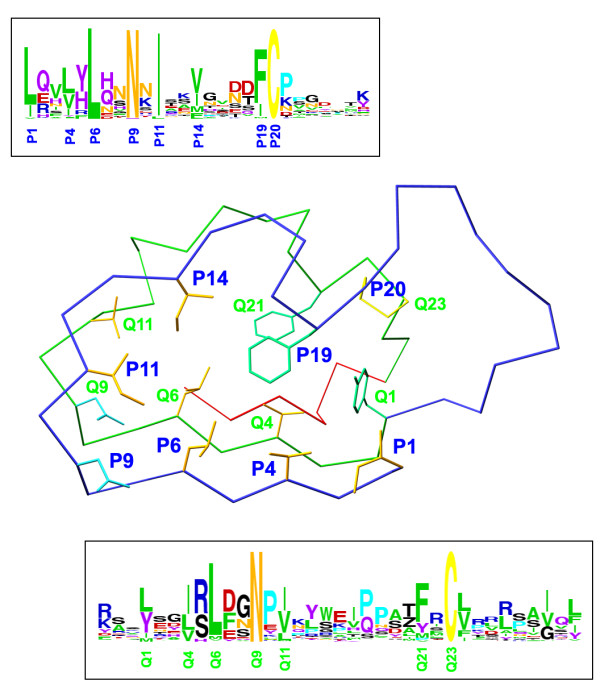
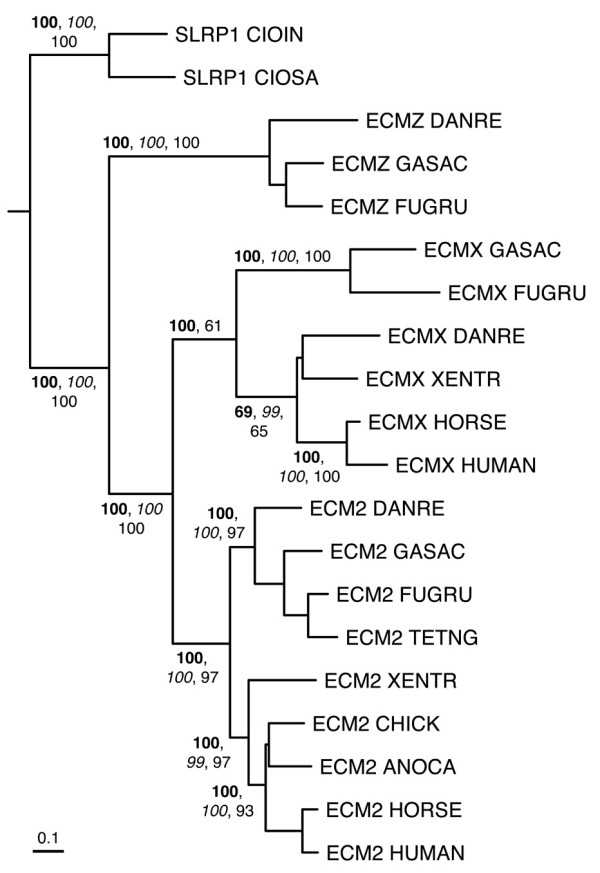
Background: The small leucine-rich repeat proteins and proteoglycans (SLRPs) form an important family of regulatory molecules that participate in many essential functions. They typically control the correct assembly of collagen fibrils, regulate mineral deposition in bone, and modulate the activity of potent cellular growth factors through many signalling cascades. SLRPs belong to the group of extracellular leucine-rich repeat proteins that are flanked at both ends by disulphide-bonded caps that protect the hydrophobic core of the terminal repeats. A capping motif specific to SLRPs has been recently described in the crystal structures of the core proteins of decorin and biglycan. This motif, designated as LRRCE, differs in both sequence and structure from other, more widespread leucine-rich capping motifs. To investigate if the LRRCE motif is a common structural feature found in other leucine-rich repeat proteins, we have defined characteristic sequence patterns and used them in genome-wide searches.
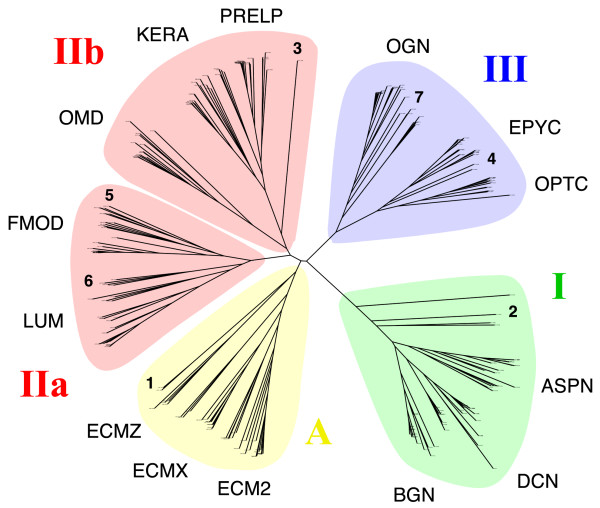
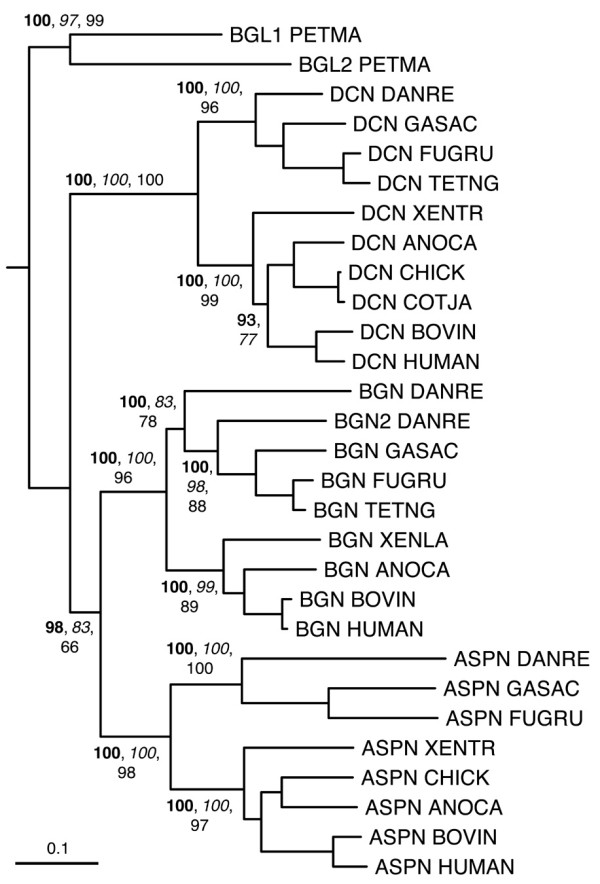
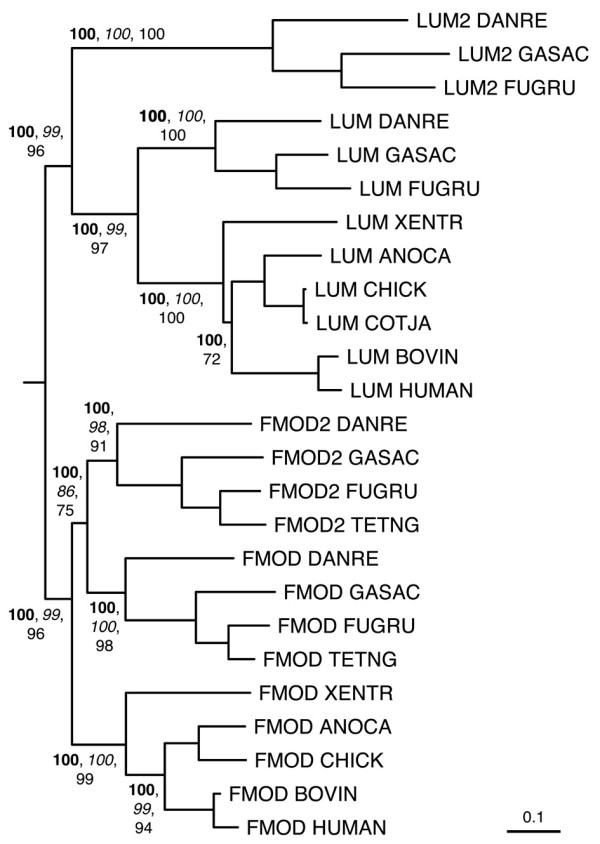
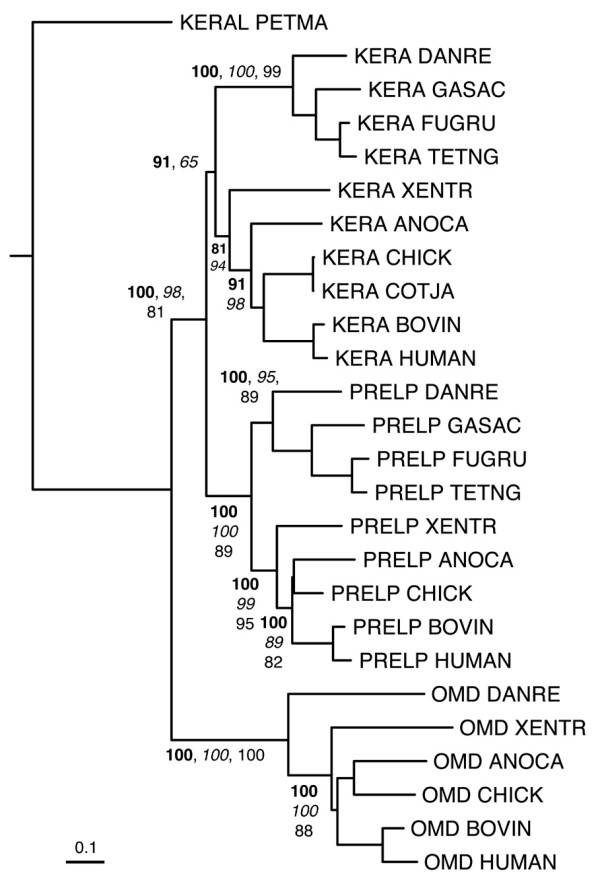
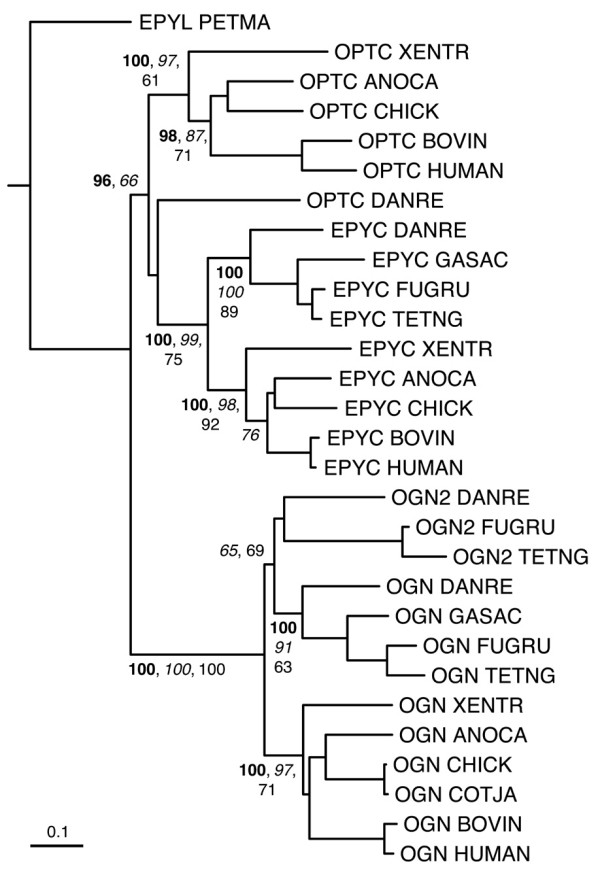
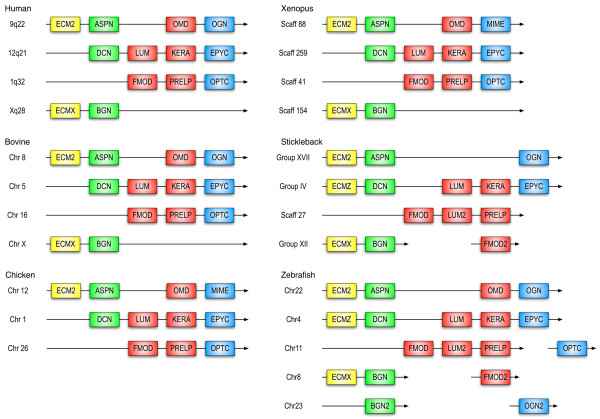
Results: The LRRCE motif is a structural element exclusive to the main group of SLRPs. It appears to have evolved during early chordate evolution and is not found in protein sequences from non-chordate genomes. Our search has expanded the family of SLRPs to include new predicted protein sequences, mainly in fishes but with intriguing putative orthologs in mammals. The chromosomal locations of the newly predicted SLRP genes would support the large-scale genome or gene duplications that are thought to have occurred during vertebrate evolution. From this expanded list we describe a new class of SLRP sequences that could be representative of an ancestral SLRP gene.
Conclusion: Given its exclusivity the LRRCE motif is a useful annotation tool for the identification and classification of new SLRP sequences in genome databases. The expanded list of members of the SLRP family offers interesting insights into early vertebrate evolution and suggests an early chordate evolutionary origin for the LRRCE capping motif.
Figures


References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
