

nGASP--the nematode genome annotation assessment project
- PMID: 19099578
- PMCID: PMC2651883
- DOI: 10.1186/1471-2105-9-549
nGASP--the nematode genome annotation assessment project
Abstract
Background: While the C. elegans genome is extensively annotated, relatively little information is available for other Caenorhabditis species. The nematode genome annotation assessment project (nGASP) was launched to objectively assess the accuracy of protein-coding gene prediction software in C. elegans, and to apply this knowledge to the annotation of the genomes of four additional Caenorhabditis species and other nematodes. Seventeen groups worldwide participated in nGASP, and submitted 47 prediction sets across 10 Mb of the C. elegans genome. Predictions were compared to reference gene sets consisting of confirmed or manually curated gene models from WormBase.
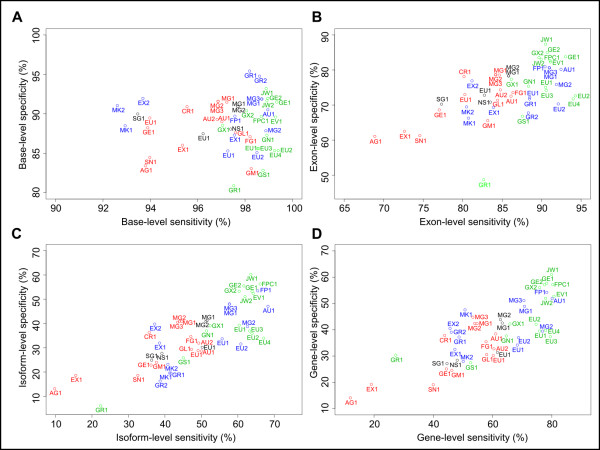
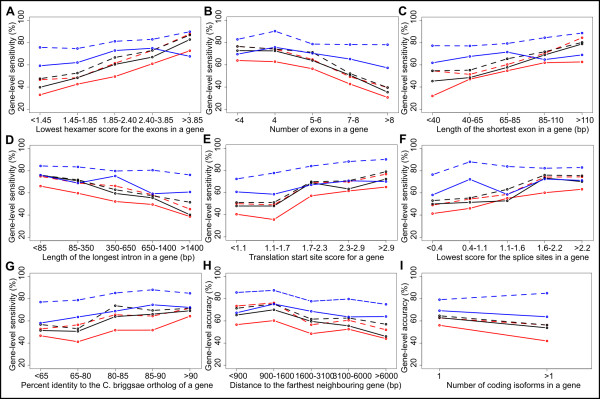
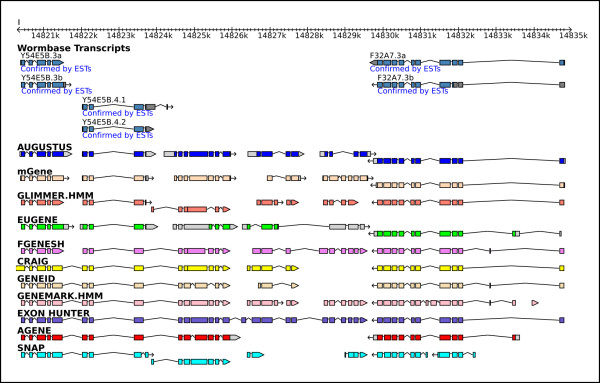
Results: The most accurate gene-finders were 'combiner' algorithms, which made use of transcript- and protein-alignments and multi-genome alignments, as well as gene predictions from other gene-finders. Gene-finders that used alignments of ESTs, mRNAs and proteins came in second. There was a tie for third place between gene-finders that used multi-genome alignments and ab initio gene-finders. The median gene level sensitivity of combiners was 78% and their specificity was 42%, which is nearly the same accuracy reported for combiners in the human genome. C. elegans genes with exons of unusual hexamer content, as well as those with unusually many exons, short exons, long introns, a weak translation start signal, weak splice sites, or poorly conserved orthologs posed the greatest difficulty for gene-finders.
Conclusion: This experiment establishes a baseline of gene prediction accuracy in Caenorhabditis genomes, and has guided the choice of gene-finders for the annotation of newly sequenced genomes of Caenorhabditis and other nematode species. We have created new gene sets for C. briggsae, C. remanei, C. brenneri, C. japonica, and Brugia malayi using some of the best-performing gene-finders.
Figures
References
-
- Stein LD, Bao Z, Blasiar D, Blumenthal T, Brent MR, Chen N, Chinwalla A, Clarke L, Clee C, Coghlan A, Coulson A, D'Eustachio P, Fitch DH, Fulton LA, Fulton RE, Griffiths-Jones S, Harris TW, Hillier LW, Kamath R, Kuwabara PE, Mardis ER, Marra MA, Miner TL, Minx P, Mullikin JC, Plumb RW, Rogers J, Schein JE, Sohrmann M, Spieth J, Stajich JE, Wei C, Willey D, Wilson RK, Durbin R, Waterston RH. The genome sequence of Caenorhabditis briggsae: a platform for comparative genomics. PLoS Biol. 2003;1:E45. doi: 10.1371/journal.pbio.0000045. - DOI - PMC - PubMed
-
- Sternberg PW, Waterston RH, Speith J, Eddy SR, Wilson RK. Genome sequence of additional Caenorhabditis species: enhancing the utility of C. elegans as a model organism. National Human Genome Research Institute White Paper; 2003.
-
- Rogers A, Antoshechkin I, Bieri T, Blasiar D, Bastiani C, Canaran P, Chan J, Chen WJ, Davis P, Fernandes J, Fiedler TJ, Han M, Harris TW, Kishore R, Lee R, McKay S, Müller HM, Nakamura C, Ozersky P, Petcherski A, Schindelman G, Schwarz EM, Spooner W, Tuli MA, Van Auken K, Wang D, Wang X, Williams G, Yook K, Durbin R, Stein LD, Spieth J, Sternberg PW. WormBase 2007. Nucleic Acids Res. 2008:D612–617. - PMC - PubMed
-
- Ghedin E, Wang S, Spiro D, Caler E, Zhao Q, Crabtree J, Allen JE, Delcher AL, Guiliano DB, Miranda-Saavedra D, Angiuoli SV, Creasy T, Amedeo P, Haas B, El-Sayed NM, Wortman JR, Feldblyum T, Tallon L, Schatz M, Shumway M, Koo H, Salzberg SL, Schobel S, Pertea M, Pop M, White O, Barton GJ, Carlow CK, Crawford MJ, Daub J, Dimmic MW, Estes CF, Foster JM, Ganatra M, Gregory WF, Johnson NM, Jin J, Komuniecki R, Korf I, Kumar S, Laney S, Li BW, Li W, Lindblom TH, Lustigman S, Ma D, Maina CV, Martin DM, McCarter JP, McReynolds L, Mitreva M, Nutman TB, Parkinson J, Peregrín-Alvarez JM, Poole C, Ren Q, Saunders L, Sluder AE, Smith K, Stanke M, Unnasch TR, Ware J, Wei AD, Weil G, Williams DJ, Zhang Y, Williams SA, Fraser-Liggett C, Slatko B, Blaxter ML, Scott AL. Draft genome of the filarial nematode parasite Brugia malayi. Science. 2007;317:1756–1760. doi: 10.1126/science.1145406. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
