

High Dimensional Classification Using Features Annealed Independence Rules
- PMID: 19169416
- PMCID: PMC2630123
- DOI: 10.1214/07-AOS504
High Dimensional Classification Using Features Annealed Independence Rules
Abstract
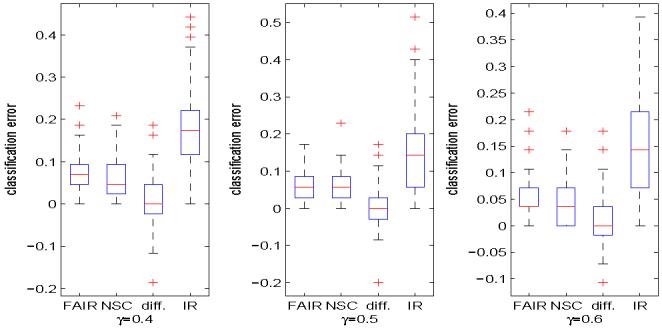
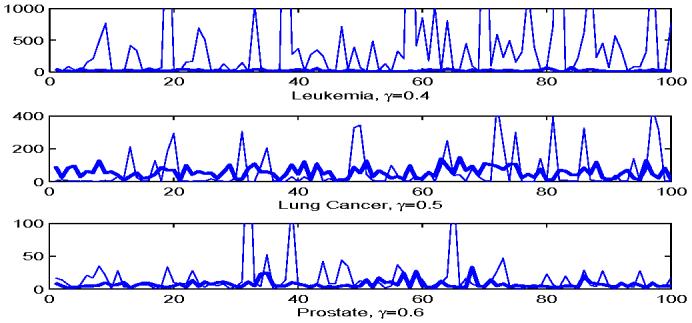
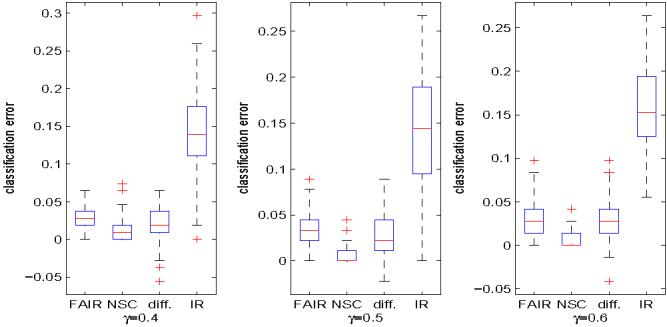
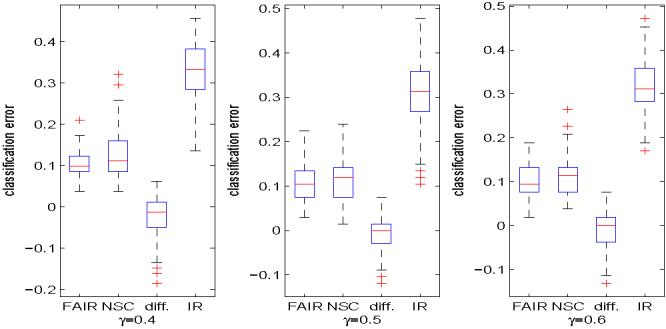
Classification using high-dimensional features arises frequently in many contemporary statistical studies such as tumor classification using microarray or other high-throughput data. The impact of dimensionality on classifications is largely poorly understood. In a seminal paper, Bickel and Levina (2004) show that the Fisher discriminant performs poorly due to diverging spectra and they propose to use the independence rule to overcome the problem. We first demonstrate that even for the independence classification rule, classification using all the features can be as bad as the random guessing due to noise accumulation in estimating population centroids in high-dimensional feature space. In fact, we demonstrate further that almost all linear discriminants can perform as bad as the random guessing. Thus, it is paramountly important to select a subset of important features for high-dimensional classification, resulting in Features Annealed Independence Rules (FAIR). The conditions under which all the important features can be selected by the two-sample t-statistic are established. The choice of the optimal number of features, or equivalently, the threshold value of the test statistics are proposed based on an upper bound of the classification error. Simulation studies and real data analysis support our theoretical results and demonstrate convincingly the advantage of our new classification procedure.
Figures
References
-
- ANTONIADIS A, LAMBERT-LACROIX S, LEBLANC F. Effective dimension reduction methods for tumor classification using gene expression data. Bioinformatics. 2003;19:563–570. - PubMed
-
- BAI Z, SARANADASA H. Effect of high dimension : by an example of a two sample problem. Statistica Sinica. 1996;6:311–329.
-
- BAIR E, HASTIE T, DEBASHIS P, TIBSHIRANI R. Prediction by supervised principal components. The Annals of Statistics. 2007 to appear.
-
- BICKEL PJ, LEVINA E. Some theory for Fisher's linear discriminant function, “naive Bayes”, and some alternatives when there are many more variables than observations. Bernoulli. 2004;10:989–1010.
-
- BOULESTEIX A. PLS Dimension reduction for classification with microarray data. Statistical Applications in Genetics and Molecular Biology. 2004;3:1–33. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials