

PyMVPA: A Unifying Approach to the Analysis of Neuroscientific Data
- PMID: 19212459
- PMCID: PMC2638552
- DOI: 10.3389/neuro.11.003.2009
PyMVPA: A Unifying Approach to the Analysis of Neuroscientific Data
Abstract
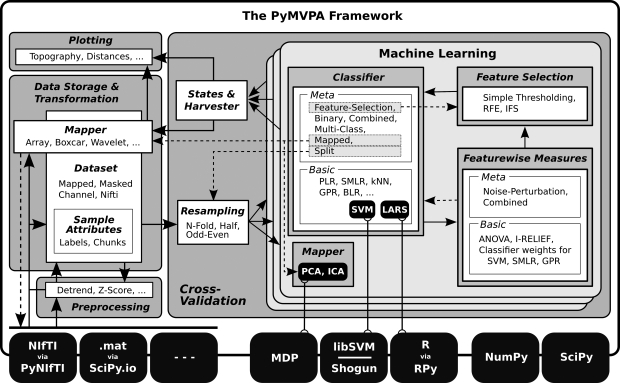
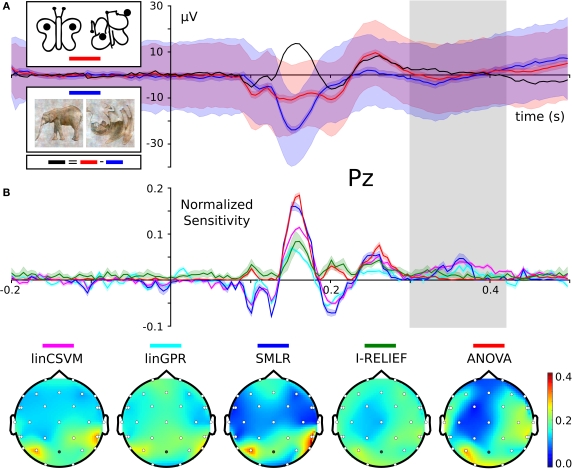
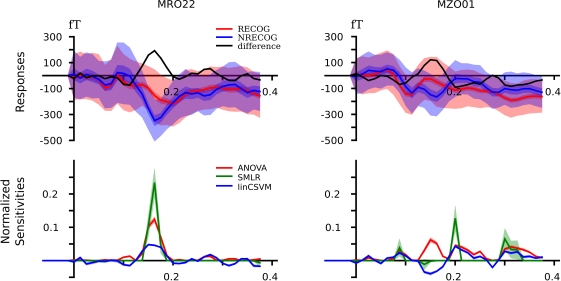
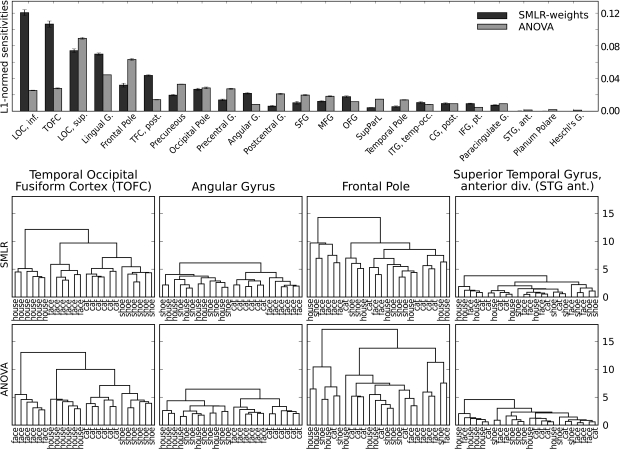
The Python programming language is steadily increasing in popularity as the language of choice for scientific computing. The ability of this scripting environment to access a huge code base in various languages, combined with its syntactical simplicity, make it the ideal tool for implementing and sharing ideas among scientists from numerous fields and with heterogeneous methodological backgrounds. The recent rise of reciprocal interest between the machine learning (ML) and neuroscience communities is an example of the desire for an inter-disciplinary transfer of computational methods that can benefit from a Python-based framework. For many years, a large fraction of both research communities have addressed, almost independently, very high-dimensional problems with almost completely non-overlapping methods. However, a number of recently published studies that applied ML methods to neuroscience research questions attracted a lot of attention from researchers from both fields, as well as the general public, and showed that this approach can provide novel and fruitful insights into the functioning of the brain. In this article we show how PyMVPA, a specialized Python framework for machine learning based data analysis, can help to facilitate this inter-disciplinary technology transfer by providing a single interface to a wide array of machine learning libraries and neural data-processing methods. We demonstrate the general applicability and power of PyMVPA via analyses of a number of neural data modalities, including fMRI, EEG, MEG, and extracellular recordings.
Keywords: Python; electroencephalography; extracellular recordings; functional magnetic resonance imaging; machine learning; magnetoencephalography.
Figures
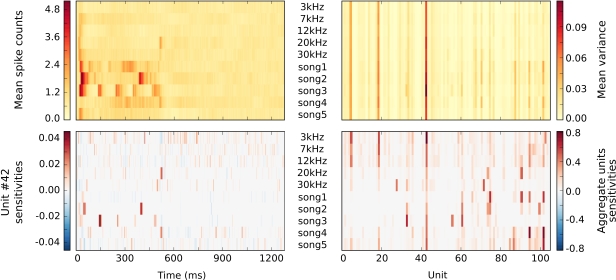
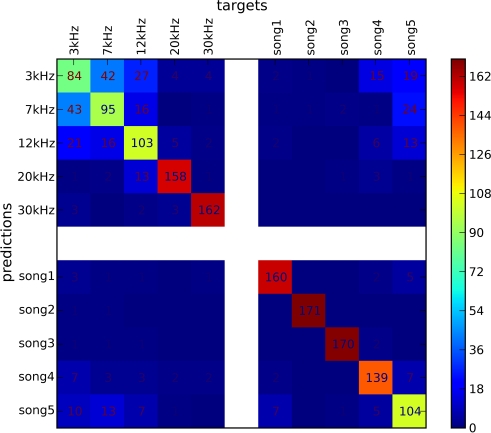
References
-
- Detre G., Polyn S. M., Moore C., Natu V., Singer B., Cohen J., Haxby J. V., Norman K. A. (2006). The Multi-Voxel Pattern Analysis (MVPA) Toolbox. Poster presented at the Annual Meeting of the Organization for Human Brain Mapping (Florence, Italy). Available at: http://www.csbmb.princeton.edu/mvpa
-
- Eads D. (2008). Hcluster: Hierarchical Clustering for SciPy. Available at: http://scipy-cluster.googlecode.com/
Grants and funding
LinkOut - more resources
Full Text Sources