

Lip-reading aids word recognition most in moderate noise: a Bayesian explanation using high-dimensional feature space
- PMID: 19259259
- PMCID: PMC2645675
- DOI: 10.1371/journal.pone.0004638
Lip-reading aids word recognition most in moderate noise: a Bayesian explanation using high-dimensional feature space
Abstract
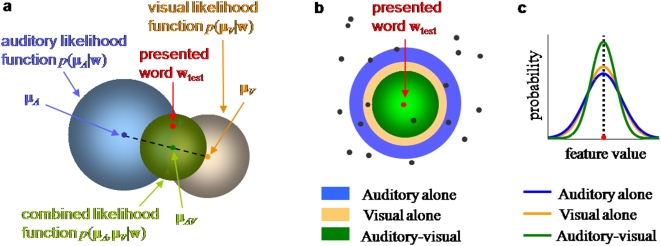
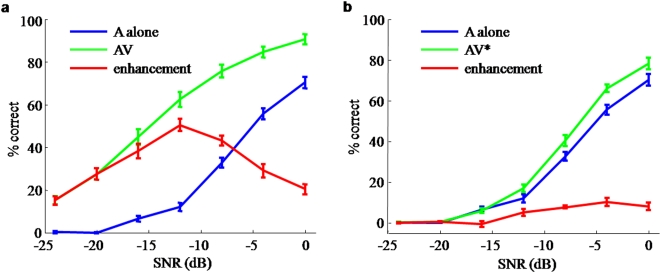
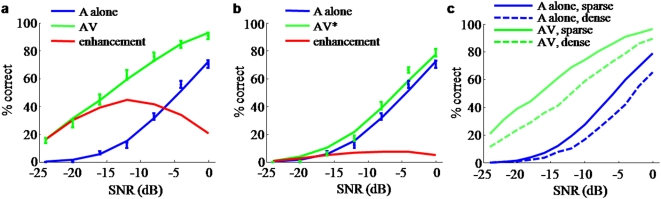
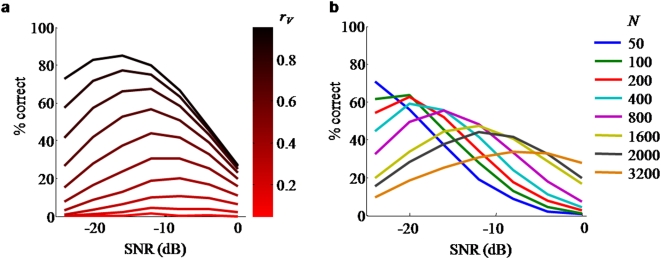
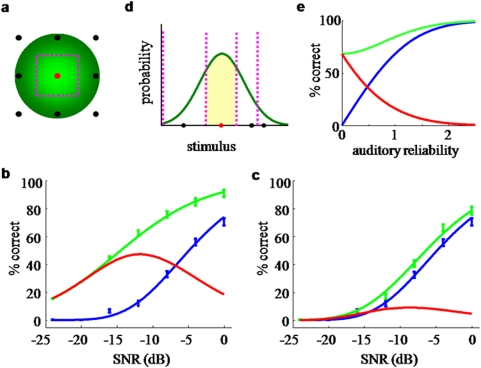
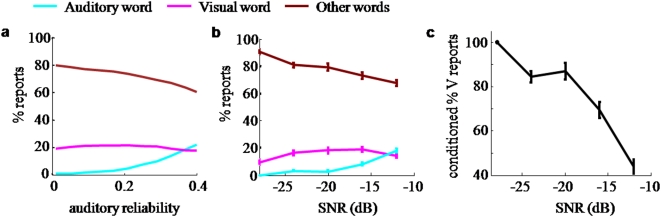
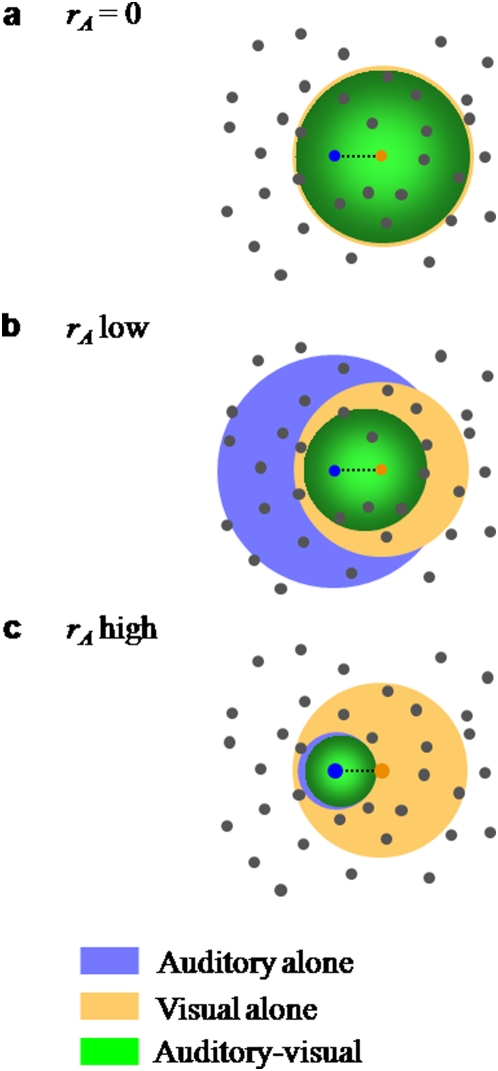
Watching a speaker's facial movements can dramatically enhance our ability to comprehend words, especially in noisy environments. From a general doctrine of combining information from different sensory modalities (the principle of inverse effectiveness), one would expect that the visual signals would be most effective at the highest levels of auditory noise. In contrast, we find, in accord with a recent paper, that visual information improves performance more at intermediate levels of auditory noise than at the highest levels, and we show that a novel visual stimulus containing only temporal information does the same. We present a Bayesian model of optimal cue integration that can explain these conflicts. In this model, words are regarded as points in a multidimensional space and word recognition is a probabilistic inference process. When the dimensionality of the feature space is low, the Bayesian model predicts inverse effectiveness; when the dimensionality is high, the enhancement is maximal at intermediate auditory noise levels. When the auditory and visual stimuli differ slightly in high noise, the model makes a counterintuitive prediction: as sound quality increases, the proportion of reported words corresponding to the visual stimulus should first increase and then decrease. We confirm this prediction in a behavioral experiment. We conclude that auditory-visual speech perception obeys the same notion of optimality previously observed only for simple multisensory stimuli.
Conflict of interest statement
Figures

References
-
- Campbell R. Speechreading: advances in understanding its cortical bases and implications for deafness and speech rehabilitation. Scand Audiol. 1998;Suppl 49 - PubMed
-
- Bernstein LE, Demorest ME, Tucker PE. Speech perception without hearing. Perception and Psychophysics. Perception and Psychophysics. 2000;62:233–252. - PubMed
-
- Grant KW, Walden BE. Evaluating the articulation index for auditory-visual consonant recognition. J Acoust Soc Am. 1996;100:2415–2424. - PubMed
-
- MacLeod A, Summerfield Q. Quantifying the contribution of vision to speech perception in noise. Br J Audiol. 1987;21:131–141. - PubMed
-
- Massaro DW. Speech perception by ear and eye: A paradigm for psychological inquiry. Hillsdale, , NJ: Erlbaum; 1987.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
